
On 6 December 2017 we had a global incident with Visual Studio Team Services (VSTS) that had a serious impact on the availability of our service (incident blog here). We apologize for the disruption. Below we describe the cause and the actions we are taking to address the issues.
Customer Impact
This was a global incident that caused performance issues and errors across multiple instances of VSTS, impacting many different scenarios. The incident occurred within Shared Platform Services (SPS), which contains identity, account, and commerce information for VSTS.
The incident started on 6 December at 8:45 UTC and ended at 14:50 UTC.
The below shows the number of impacted users during the incident.
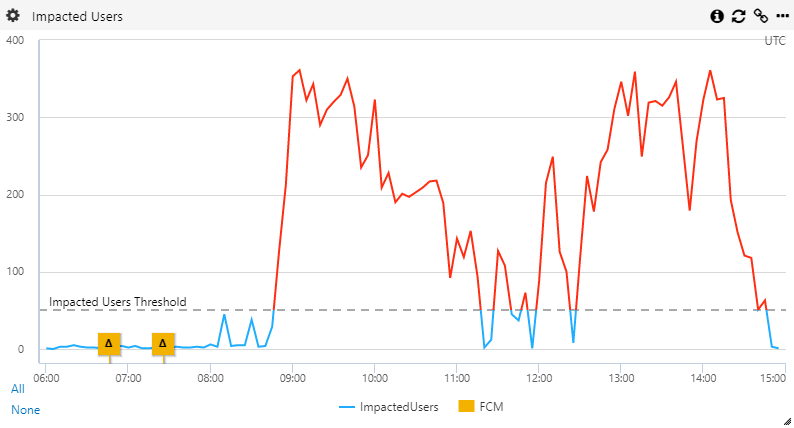
What Happened
An SPS hotfix was deployed on 6 December at 6:46 UTC to mitigate an LSI. The hotfix increased the SPS application tier count from 7 to 10. As part of this change, the last step started SPS S126 DB upgrades which were not intended to start until later in the day (and thus would have experienced the upgrade-induced issue later). As the S126 DB upgrades were progressing we observed customer impact across scale units, high CPU on the SQL DBs, and circuit breakers opening due to concurrency limits.
The S126 DB upgrade completed on 7 of the 9 SPS DBs and S126 SPS upgrades were manually stopped on the last 2 databases. These 2 databases were unhealthy, showing high CPU usage, and high number of concurrency circuit breakers. In addition to the upgrade load which was running an expensive upgrade step, one of the SQL stored procedures where we have two variants was running the wrong variant. For this particular stored procedure, we have one that works on Azure SQL ‘S’ SKUs and a more efficient one that takes advantage of a feature (memory-optimized tables) that is available in Azure SQL ‘P’ SKUs.
We upgraded the DBs to larger Azure SQL SKUs, and the increased resources mitigated the issue. The upgrade of one of the DBs completed in a short period of time, and the other took nearly 2 hours to complete. Subsequently the upgrade was completed.
Next Steps
Beyond the immediate fix to the SQL stored procedure, we are taking the following steps to prevent issues like this one going forward:
- We are fixing the release definition not to trigger DB upgrade when we are running in a state where only the binaries are updated (we run updated binaries for 24 hours prior to DB upgrade to ensure we can switch back to the old binaries if we find a problem).
- We will make the mechanism to select the efficient stored procedure robust.
- We are improving the guidance in some of our standard operating procedures, including our guidance around scaling up, querying for impact to a specific account, and stopping upgrades.
- We are reviewing circuit breaker limits that were inconsistent (different settings in the code and the DB).We again apologize for the disruption this caused you. We are fully committed to improving our service to be able to limit the damage from an issue like this and be able mitigate the issue more quickly if it occurs.
Sincerely,
Buck Hodges Director of Engineering, VSTS
0 comments