
On 21 November 2017 we had an incident with Visual Studio Team Services (VSTS) that had a serious impact on the availability of our service for many customers (incident blog here). We apologize for the disruption. Below we describe the cause and the actions we are taking to address the issues.
Customer Impact
This incident caused performance issues and errors across multiple instances of the VSTS service within the US and Europe. The services affected were Git and TFVC (version control), Build, Work, and Test.
The incident started on 21 November at 8:25 UTC and ended at 18:49 UTC. The impact breakdown across affected instances of VSTS was as follows for scale units in our North Central US (NCUS), South Central US (SCUS) and Western European (WEU) data centers.

The graph below shows the total number of impacted users during the incident.
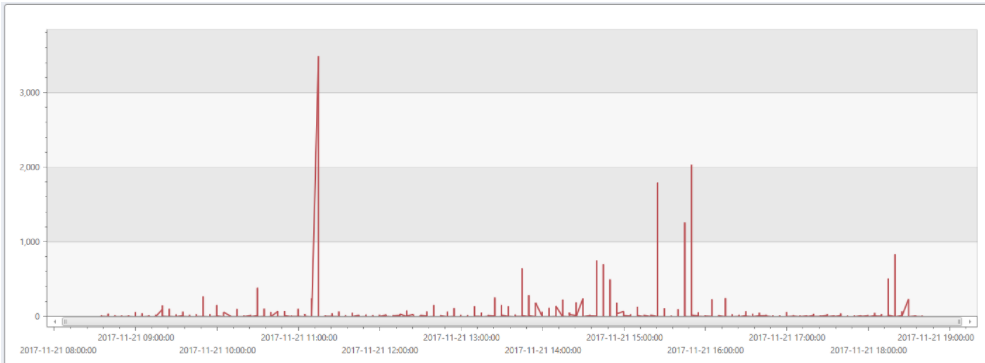
What Happened
VSTS uses SignalR to provide automatic updates for pull request, builds, dashboard, task boards, and other experiences in the web portal. For example, if you are reviewing a pull request and the author updates it, you’ll receive a notification in the browser that there is a newer version.
We have seen cases where large numbers of clients disconnect at the same time. In these cases, the JavaScript client attempts to reconnect every 2-3 seconds depending on the transport used. If the request doesn’t complete within 5 seconds, the request is canceled, the client waits 2-3 seconds, and then a new request is attempted. This pattern repeated for up to 40 seconds with no randomization in the back-off logic.
Due to this behavior, clients all attempt to reconnect at effectively the exact same intervals which causes request queuing due to the burst of new requests. Some reconnects succeed, others continually timeout and are canceled which causes issues such as lock contention on the timer queue. Once the reconnection timeout has been reached, the clients will then enter a randomized back-off and attempt to establish connectivity with a brand new connection. The new connections will not have any messages pending delivery and do not place the same CPU load on the server as the reconnects previously mentioned.
Next Steps
We are taking the following steps to fix the root cause of this issue:
- SignalR contains a cache for info on messages not delivered per connection that can be expensive to enumerate if the number of clients reconnecting is large and the cache has been saturated. In order to help reduce the impact we have reduced the size of the cache.
- As described above, the retry delays for reconnecting the JavaScript clients use fixed times. In the event of a large number of clients being disconnected at the same time, they all attempt to reconnect at the same time. We’ve changed this behavior to use a random time delay in order to spread out the reconnection attempts.
- We are adding a circuit breaker to limit the number of reconnect calls made over a window of time in order to prevent overwhelming the machine.We will investigate having the connections from the web UI drop when the tab in the browser has not been used for an extended period of time to reduce the number of connections.
- We again apologize for the disruption this caused you. We are fully committed to improving our service to be able to limit the damage from an issue like this and be able mitigate the issue more quickly if it occurs.
Sincerely, Buck Hodges Director of Engineering, VSTS
0 comments