
In a previous blog series, we announced that Git has a new commit-graph feature, and described some future directions. Since then, the commit-graph feature has grown and evolved. In the recently released Git version 2.24.0, the commit-graph is enabled by default! Today, we discuss what you should know about the feature, and what you can expect when you upgrade.
What is the commit-graph, and what is it good for?
The commit-graph file is a binary file format that creates a structured representation of Git’s commit history. At minimum, the commit-graph file format is faster to parse than decompressing commit files and parsing them to find their parents and root trees. This faster parsing can lead to 10x performance improvements.
To get even more performance benefits, Git does not just use the commit-graph file to parse commits faster, but the commit-graph includes extra information to help avoid parsing some commits altogether. The critical idea is that an extra value, the generation number of a commit, can significantly reduce the number of commits we need to walk. Since Git 2.19.0, the commit-graph stores generation numbers.
Since then, we added new algorithms to improve Git commands such as force push or fetch negotiation.
Finally, the most immediately-visible improvement is the time it takes to sort commits by topological order. This algorithm is the critical path for git log --graph. Before the commit-graph, Git needed to walk every reachable commit before returning a single result.
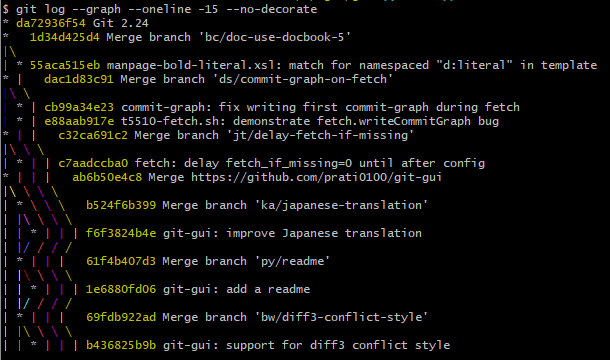
git log --graph
For example, here is a run of git log --graph in the Linux repository without the commit-graph feature, timing how long it takes to return ten results:
$ time git -c core.commitGraph=false log --graph --oneline -10 >/dev/null
real 0m6.103s
user 0m5.803s
sys 0m0.300s
The reason it took so long is because Kahn’s algorithm computes the “in-degrees” of every reachable commit before it can start to select commits of in-degree zero for output. When the commit-graph is present with generation numbers, Git now uses an iterative version of Kahn’s algorithm to avoid walking too far before knowing that some of the commits have in-degree zero and can be sent to output.
Here is that same command again, this time with the commit-graph feature enabled:
$ time git -c core.commitGraph=true log --graph --oneline -10 >/dev/null
real 0m0.009s
user 0m0.000s
sys 0m0.008s
Six seconds to nine milliseconds is a 650x speedup! Since most users asking for git log --graph actually see the result in a paged terminal window, this allows Git to load the first page of results almost instantaneously, and the next pages are available as you scroll through the history.
Sounds Great! What do I need to do?
If you are using Git 2.23.0 or later, then you have all of these benefits available to you! You just need to enable the following config settings:
-
git config --global core.commitGraph true: this enables every Git repo to use the commit-graph file, if present. -
git config --global gc.writeCommitGraph true: this setting tells thegit gccommand to write the commit-graph file whenever you do non-trivial garbage collection. Rewriting the commit-graph file is a relatively small operation compared to a full GC operation. -
git commit-graph write --reachable: this command will update your commit-graph file to contain all reachable commits. You can run this to create the commit-graph file immediately, instead of waiting for your first GC operation.
In the recently-released Git version 2.24.0, core.commitGraph and gc.writeCommitGraph are on by default, so you don’t need to set the config manually. If you don’t want commit-graph files, then explicitly disable these settings and tell us why this isn’t working for you. We’d love to hear your feedback!
Write during fetch
The point of the gc.writeCommitGraph is to keep your commit-graph updated with some frequency. As you add commits to your repo, the commit-graph gets further and further behind. That means your commit walks will parse more commits the old-fashioned way until finally reaching the commits in the commit-graph file.
When working in a Git repo with many collaborators, the primary source of commits is not your own git commit calls, but your git fetch and git pull calls. However, if your repo is large enough, writing the commit-graph after each fetch may make your git fetch command unacceptably slow. Perhaps you downloaded a thousand new commits, but your repo has a million total commits. Writing the full commit-graph operates on the size of your repo, not on the size of your fetch, so writing those million commits is costly relative to the runtime of the fetch.
During garbage collection, you are already paying for a full repack of all of your Git objects. That operation is already on the scale of your entire repository, so adding a full commit-graph write on top of that is not a problem.
There is a solution: don’t write the whole commit-graph every time! We’ll go into how this works in more detail in the next section, but first you can enable the fetch.writeCommitGraph config setting to write the commit-graph after every git fetch command:
git config --global fetch.writeCommitGraph true
This ensures that your commit-graph is updated on every fetch and your Git commands are always as fast as possible.
Incremental Commit-Graph Format
Before getting too far into the incremental file format, we need to refresh some details about the commit-graph file itself.
A Single Commit-Graph File
The commit-graph file format stores commit data in a set of tables.
One table is a sorted list of commit IDs. This row number of a commit ID in this table defines the lexicographical position (lex position for short) of a commit in the file.
Another table contains metadata about the commits. The nth row of the metadata table corresponds to the commit with lex position n. This table contains the root tree ID, commit time, generation number, and information on the first two parents of the commit. We use special constants to say “this commit does not have a second parent”, and use a pointer to a third “extra edges” table in the case of octopus merges.
The two parent columns are stored as integers, and this is very important! If we store parents as commit IDs, then we waste a lot of space. Further, if we only have a commit ID, then we need to perform a binary search on the commit list to find the lex position. By storing the position of a parent, we can navigate to the metadata row for that parent as a random-access lookup.
For that reason, the commit-graph file is closed under reachability, meaning that if a commit is in the file, then so is its parent. Otherwise, we could not refer to the parent using an integer.
Before incremental writes, Git stored the commit-graph file as .git/objects/info/commit-graph. Git looks for that file, and parses it if it exists.
Multiple Commit-Graph Files
Instead of having just one commit-graph file, now Git can have multiple! The important idea is that these files are ordered carefully such that they form a chain. The figure below shows three sections of a graph. The bottom layer is completely self-contained: if a commit is in the bottom layer, then so is its parents and every other commit it can reach. The middle layer allows parents to span between that layer and the bottom layer. The top layer is the same.
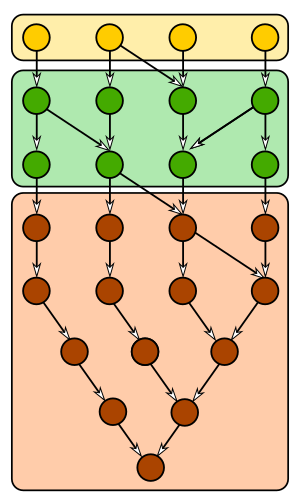
The important feature is that the top layer is smaller than the other layers. If those commits are new to the repo, then writing that top layer is much faster than rewriting the entire graph.
Keep this model in mind as we dig into the concrete details of how Git creates this chain of commit-graph files.
If the single .git/objects/info/commit-graph file does not exist, Git looks for a file called .git/objects/info/commit-graphs/commit-graph-chain. This file contains a list of SHA-1 hashes separated by newlines. To demonstrate, we will use this list of placeholders:
{hash0}
{hash1}
{hash2}
These hashes correspond to files named .git/objects/info/commit-graphs/graph-{hash0}.graph. The chain of the three files combine to describe a set of commits.
The first graph file, graph-{hash0}.graph, is a normal commit-graph file. It does not refer to any other commit-graph and is closed under reachability.
The second graph file, graph-{hash1}.graph is no longer a normal commit-graph file. To start, it contains a pointer to graph-{hash0}.graph by storing an extra “base graphs” table containing only “{hash0}”. Second, the parents of the commits in graph-{hash1}.graph may exist in that file or in graph-{hash0}.graph. Each graph file stores the commits in lexicographic order, but we now need a second term for the position of a commit in the combined order.
We say the graph position of a commit in the commit-graph chain is the lex position of a commit in the sorted list plus the number of commits in the base commmit-graph files. We now modify our definition of a parent position to use the graph position. This allows the graph-{hash1}.graph file to not be closed under reachability: the parents can exist in either file.
Extending to graph-{hash2}.graph, the parents of those commits can be in any of the three commit-graph files. The figure below shows this stack of files and how one commit row in graph-{hash2}.graph can have parents in graph-{hash1}.graph and graph-{hash0}.graph.
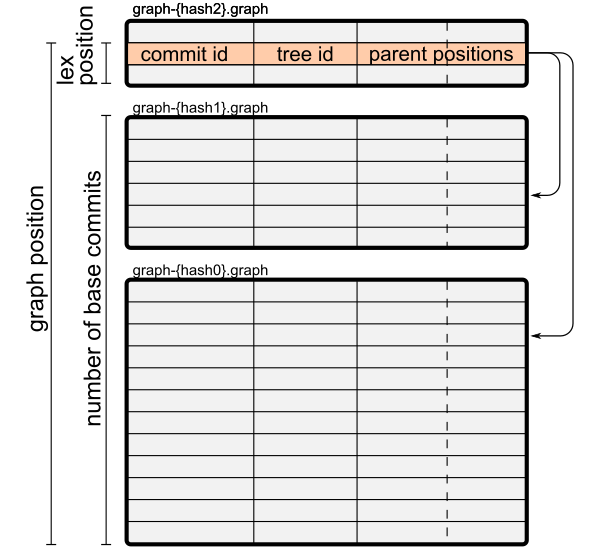
If you enable fetch.writeCommitGraph, then Git will write a commit-graph chain after every git fetch command. This is much faster than rewriting the entire file, since the top layer of the chain can consist of only the new commits. At least, it will usually be faster.
Do it Yourself!
To create your own commit-graph chain, you can start with an existing commit-graph file then create new commits and create an incremental file:
git commit-graph write --reachable git commit --allow-empty -m "empty" git commit-graph write --reachable --splitThe
‐‐splitoption enables creating a chain of commit-graph files. If you ever run the command without the‐‐splitoption, then the chain will merge into a single file.
The figure above hints at the sizes of the commit-graph files in a chain. The base file is large and contains most of the commits. As we look higher in the chain, the sizes should shrink.
There is a problem, though. What happens when we fetch 100 times? Will we get a chain of 100 commit-graph files? Will our commit lookups suddenly get much slower? The way to avoid this is to occasionally merge layers of the chain. This results in better amortized time, but will sometimes result in a full rewrite of the entire commit-graph file.
Merging Commit-Graph Files
To ensure that the commit-graph chain does not get too long, Git will occasionally merge layers of the chain. This merge operation is always due to some number of incoming commits causing the “top” of the chain to be too large. There are two reasons Git would merge layers, given by these options to git commit-graph write --split:
-
--size-multiple=<X>: Ensure that a commit-graph file isXtimes larger than any commit-graph file “above” it.Xdefaults to 2. -
--max-commits=<M>: When specified, make sure that only the base layer has more thanMcommits.
The size-multiple option ensures that the commit-graph chain never has more than log(N) layers, where N is total number of commits in the repo. If those chains seem to be too long, the max-commits setting (in conjunction with size-multiple) guarantees that there are a constant number of possible layers.
In all, you should not see the incremental commit-graph taking very long during a fetch. You are more likely to see the automatic garbage collection trigger, and that will cause your commit-graph chain to collapse to a single layer.
Try it Yourself!
We would love your feedback on the feature! Please test out the --split option for writing commit-graphs in Git 2.23.0 or later, and the fetch.writeCommitGraph option in Git 2.24.0. Git 2.24.0 is out now, so go upgrade and test!
0 comments