
Earlier, we announced that Git 2.18 contains a new commit-graph feature, and we discussed the commit-graph file format. As shipped in Git 2.18, this file only speeds up commit walks by a constant multiple, due to parsing structured data from the commit-graph file. Today, we continue by talking about how we can use the idea of a generation number to greatly reduce the number of commits we walk, giving much greater performance improvements. Many of the topics we discuss today are already on their way to a future version of Git while others are still part of the future plans for the commit-graph feature.
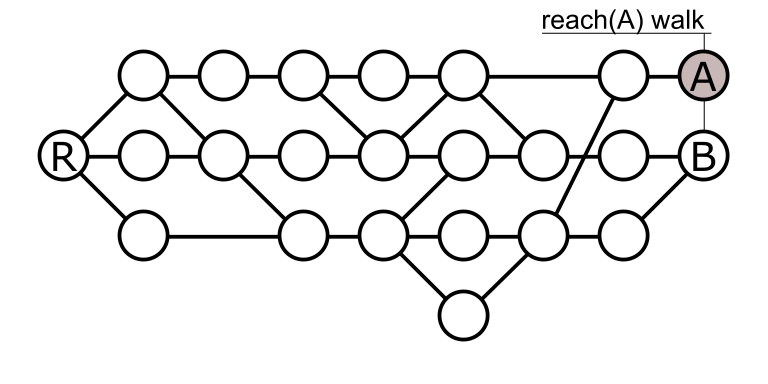
Let’s use this commit graph example:

Each circle represents a commit and the lines demonstrate a commit-to-parent relationship. Commits are arranged left-to-right based on time, so the commit R is a root commit. Commits A and B represent two “tip” commits (no commits have A or B as parents). Commit A has a single parent while commit B is a merge between two commits.
What is a Generation Number?
We define the generation number of a commit as follows:
- If a commit has no parents, then its generation number is 1.
- Otherwise, the generation number of a commit is one more than the maximum generation number of its parents.
Computing generation numbers is relatively simple: perform a depth-first search (DFS), stopping when you reach a commit with known generation number, and then walk backwards filling in your generation numbers. An algorithm for computing generation numbers in Git is slated for the next major release (Git 2.19).
For our example above, I already organized the commits in columns based on generation number:

Note that I only have a few examples of commits whose parents have differing generation numbers, but it is very common in real-world repositories to have greatly different generation numbers among parents. Every time a single-developer’s topic branch merges into master using a pull request, the first parent of the merge — which contains all commits introduced by other developers during that topic’s lifetime — is likely to have a much higher generation number than the second parent, which contains the commits that one developer created.
We are able to store the generation number for each commit in the commit-graph file due to some forethought in the format. When we discussed the commit-graph file format, we had a column of data reserved for the commit date. That column is actually 64-bits (8 bytes) wide. In the next version of Git, we split that column into two columns for commit date and generation number.
Generation numbers have the following property:
Suppose A and B are commits with generation numbers gen(A) and gen(B). If gen(A) < gen(B) then A cannot reach B.
This allows us to short-circuit commit graph walks in several ways. I’ll describe several of these tricks in the sections below. These applications vary from very simple to rather complicated. Take your time going through the examples.
Using Generation Number in “Can X Reach Y?” Questions
git push sends the information contained in your current branch to your origin remote. If that remote already contains a branch with that name, then it may reject the push unless your branch contains the existing branch value in its history. If not, then you need to use a force push, knowing that you may be removing important history.
This is a classic example of a “Can X reach Y?” question. This is currently answered by performing a commit walk ordered by commit date starting at X. If Y appears during this walk, we can stop and return success. If X cannot reach Y, then we will walk all commits reachable from X!
The simplest way to improve this algorithm is to stop visiting commits with generation number lower than the generation number of Y. Those commits cannot reach Y, so don’t bother walking them! You can see how this works in our example, where we try to see if A can reach T.

Using Generation Number in Merge-Base Questions
When Git merges two commits, it first finds a merge base to use when computing the resulting merge algorithm. There may be multiple possible merge bases between two commits A and B, but each have the following properties:
- A merge base is reachable from both A and B.
- A merge base is not reachable from another commit that is also reachable from A and B.
In our example below, the commits P and Q are the possible merge bases for A and B.
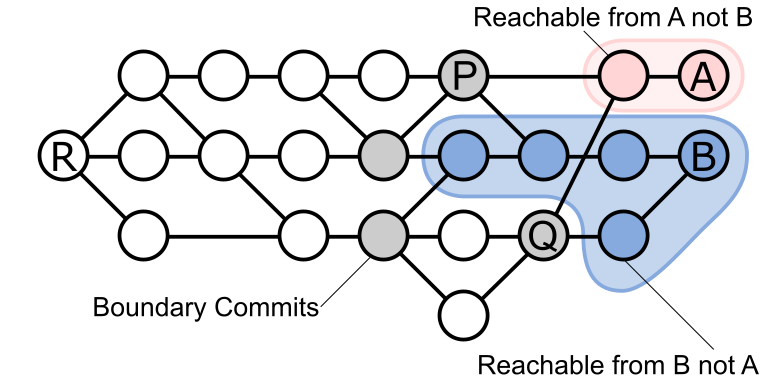
To find the set of merge bases between A and B, we can perform a commit walk (ordered by commit date, descending) marking each commit along the way as reachable from A, from B, or from both. We can stop the walk when all commits in our walk boundary are reachable from both A and B. Git has another trick to help with the second condition above: if a commit is reachable from both A and B, then we mark that commit’s parents as uninteresting. Then we can perform a second walk from A and B to find the first commit interesting commit that is reachable from both. That is our merge base.
This algorithm is pretty efficient, and it even has a built-in short-circuit to avoid walking the entire graph when the merge bases are close to A and B. The one place we can improve is in the heuristic we use when walking the commits. We walk in order of descending generation number instead of descending commit date. Since clock-skew can provide incorrect ordering of commits, it is possible that we need to walk commits twice: once to distribute the “reachable from A” mark, and a second time to distribute the “reachable from B” mark.
Not only is this algorithm used by git merge-base, it is also used by git status when your local branch has an upstream branch and it displays how many commits are ahead or behind. Similarly, git branch -vv outputs the ahead/behind counts for every branch in your repo. In the example above, A is two commits ahead of B, but five commits behind B.
Using Generation Number for Topological Sorting
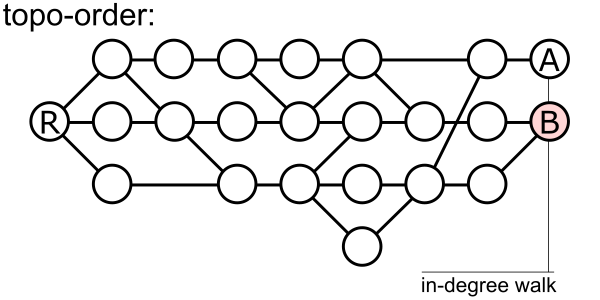
Now we get into the really complicated applications of generation number. When you use the git log --graph command, you are asking for an ordering of your commits that is nice to display along with the edges between a commit and its parents. For this to make sense, we must have all edges pointing down in the list. That is, a commit must appear before its parent. This is called a topological sort.
The standard algorithm for topological sort is Kahn’s Algorithm. The basic way this algorithm works is by walking the commit graph in two passes:
- The first pass computes the “in-degree” of each commit: how many commits have this commit as a parent? (This in-degree only cares about commits reachable from our starting position.)
- Walk the commit graph by selecting a commit with in-degree zero and decrementing the in-degree of its parents.
This algorithm works because a commit must be selected before its parent, or else the in-degree of the parent is positive! The problem is, we need to walk the entire graph in order to guarantee the in-degree of a commit is zero.
You can see this two-stage algorithm in the Git codebase. The first pass is done by limit_list() while the walk in the second phase is done by sort_in_topological_order(). These methods are called in order before a single commit is output in git log --graph.
When you are looking at the command line for git log --graph or at the web view for commit history, you only need a few dozen results in the first page of values. You do not need thousands of results to be completely ordered before you investigate the first few results. Here is where generation numbers can come in and help.
The trick is to keep two commit walks going at the same time. One walk is in charge of computing in-degrees while the other is for walking the commits in topological order. The in-degree walk only needs to advance when the topological order walk considers a commit for the next selection. Since the in-degree walk advances by selecting a commit of maximum generation number (stored in a priority queue), we can detect in constant time if we need to advance that walk.
There is one thing we need to mention about the topological sorting walk. To minimize the number of crossing edges in our graph diagram, we use a special kind of “visit order” as we walk. When we select a commit for the topological order, we decrement the in-degree of its parents and assign an integer value to each, incrementing the value each time. In this way, we prioritize following the topic branch merged by a pull request before following the first-parent history.
The animation below shows how this two-walk algorithm works on our example.
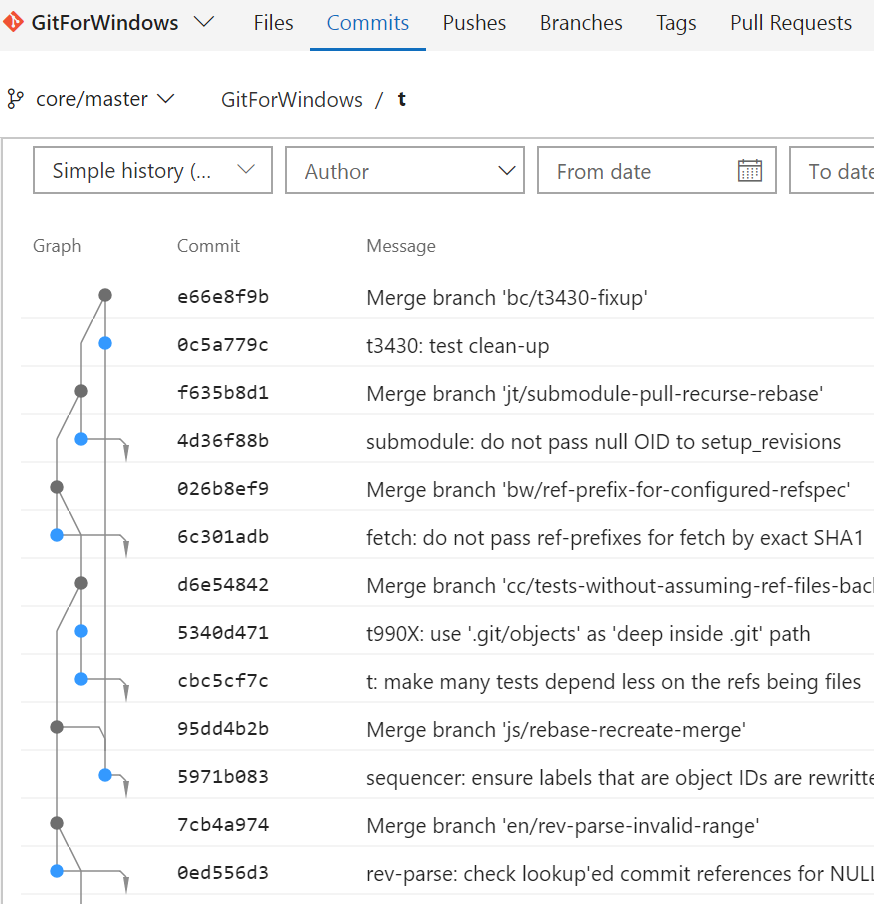
This algorithm is at the heart of how Visual Studio Team Services (VSTS) displays commit history, as in the image below.
The topo-order algorithm will be harder to implement in Git as the existing code is structured as a two-phase process. However, we are already discussing how to use this new algorithm. At this point, the only challenge is refactoring the logic to allow this algorithm without breaking the existing applications of the revision-walk machinery.
It gets more complicated if we combine the topological order requirement with a comparison query. For example, if we use git log --graph A..B we want to topo-order the commits reachable from B but not reachable from A. This means we need to add a third walk (ahead of the in-degree walk) that determines if each commit is reachable from A. This is the problem that is solved when presenting the commits being introduced by a pull request, or by each update in a VSTS pull request:
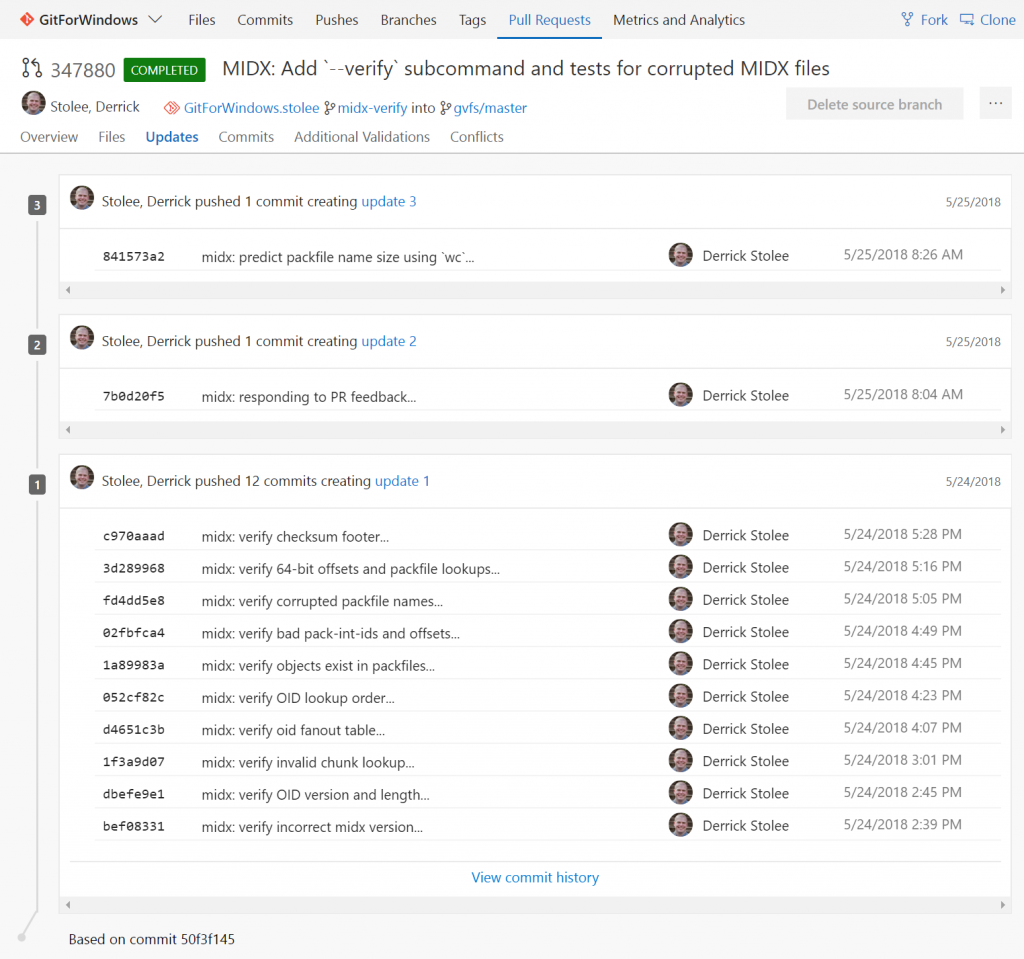
Instead of going deep into that three-walk algorithm, I’ll just leave you with another animation:
Why Not Just Use Commit Date?
The important detail we get from the generation number is that we can say that A cannot reach B if gen(A) is less than gen(B). If you think about it, the commit date should provide this same condition. A commit should be created only after its parent, so the commit date should be larger!
The operative word is should. In fact, there are several reasons why this does not hold for many large repositories. The first is that not every computer has a synchronized clock. It is possible for you to create a commit on your machine, push it, and merge it using a pull request on the server and the commit date of the merge is “before” your local commit. These events are rare, but they do occur.
Further, you could dig deep into the Git internals and manufacture a commit with whatever commit date you want. For this reason, we cannot rely on commit date. Users have reported git log output being in the “wrong” order before, and that is because the default order uses commit date and does not verify topological order.
There is another reason to use generation number. The generation number of a commit can be defined non-recursively as “The generation number of A is the number of commits along a longest path from A to a root commit”. In this way, the generation number of a commit is as small as possible while being helpful. This means that for any given cutoff value, as many commits as possible have generation number below that value.
To Be Continuted
In part IV, we discuss using Bloom filters to accelerate file history.
Unfortunately after site reorganization both animations got lost: instead of animated GIF of original version of the article the site now includes static PNG image.