
[Editor’s note: “Smart Unit Tests” has been renamed to “IntelliTest” with effect from Visual Studio 2015 Release Candidate (RC).]
Our previous post introduced Smart Unit Tests. Please read that first if you have not already done so. Now let us continue.
How is “Smart Unit Tests” able to generate a compact test suite with high coverage? How does it work? Having a mental model of how it works will help us interact with the feature and interpret the results it reports. So without further ado, let’s dive in.
“Smart Unit Tests” works by using run time instrumentation and monitoring:
- The code-under-test (i.e. “code”) is first instrumented and callbacks are planted that will allow the testing engine to monitor execution. The code is then “run” with the simplest relevant concrete input value (based on the type of the parameter). This represents the initial test case.
- The testing engine monitors execution, computes code coverage for each test case, and tracks how the input value flows through the code. If all branches are covered the process stops; all exceptional behaviors are considered as branches just like explicit branches in the code. If not all branches have been covered yet, the testing engine picks a test case which reaches a program point from which an uncovered branch leaves, and determines how the branching condition depends on the input value.
- The engine constructs a constraint system representing the condition under which control reaches to that program point and would then continue along the previously uncovered branch. It then queries a constraint solver to synthesize a new concrete input value based on this constraint.
- If the constraint solver can determine a concrete input value for the constraint, then the code is run with the new concrete input value.
- If coverage increases, then a test case is emitted.
Steps (2) to (5) are repeated until all branches are covered, or until pre-configured exploration bounds are exceeded.
Here is a block diagram representing the above steps:
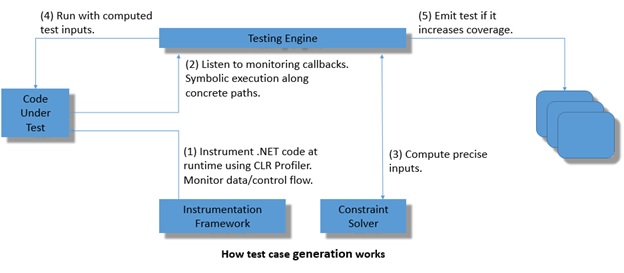
This process is termed an “exploration”. Within an “exploration” the code can be “run” several times – some of those runs increase “code ****coverage”, and only the runs that increase coverage emit test cases. Thus, all tests that are emitted exercise feasible paths.
A view of the lifetime of an exploration is shown in the below graph. As can be seen, the code may be run multiple times, and test cases are emitted only when coverage increases, and various “issues” are reported along the way.
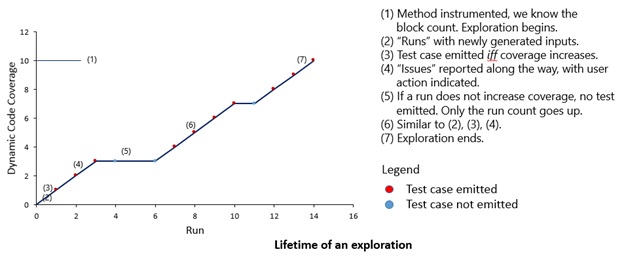
Armed with this knowledge let’s walk through the concrete example below:
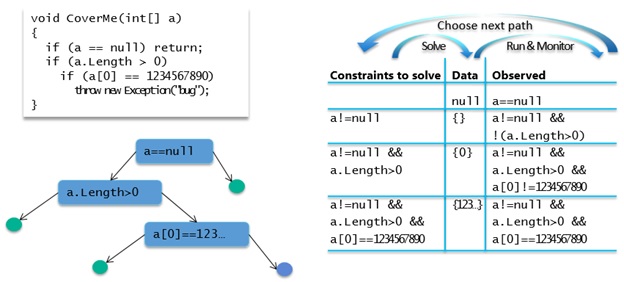
Exploration proceeds as follows:
- The engine starts by choosing some inputs. It always begins with the simplest inputs possible. In this case, the input would be null for the array parameter.
- The code is run, and the engine monitors all conditions that are checked, along the execution path that is taken for the chosen inputs.
- In the above example the methods returns because a == null.
- The engine negates this condition and queries a constraint solver to determine whether there is a solution for the negated condition.
- If a solution exists, then this solution represents another test input, which would cause the code to take a different path.
And then the engine repeats this process. Internally, it represents all conditions that the program checks as a tree. Every time it runs the code this tree might grow, and the engine learns about new behaviours of the code. After a few iterations, exploration finishes for this example as shown in the table above. Note that with just 4 test inputs the engine is able to cover all of the code; a compact suite with high coverage! A random test input generator might have little chance of generating the precise data value required to cause the exception to be thrown. Try this sample out and see for yourself.
But what about correctness? How does engine know if the code was correct? The answer to that is that code coverage and correctness are connected by assertions. The assertion could be in the form of the Debug.Assert method, etc. The nice thing is that these are all compiled down to branches – an if statement with a then branch and an else branch representing the outcome of the predicate being asserted. Since the engine computes inputs that exercise all branches, it becomes an effective bug-finding tool as well – any input it comes up with that can trigger the else branch represents a bug in the code. Thus, all bugs which are reported are actual bugs.
At this point let’s pause and take stock. We began by asking how does it work, and have begun answering that in terms of a mental model consisting of the notions of an “exploration”, “code coverage”, “runs”, and “assertions”. Indeed, these are represented in the user interface as well. There are several more questions to answer however – for example, what are the “issues” that it reports? What do “exploration boundaries” mean? If you are interested, let us know and we will discuss them in upcoming posts.
For now, start using “Smart Unit Tests”, and report any issues or overall feedback below, or through the Send a Smile feature in Visual Studio.
0 comments