

Whenever I talk to somebody about Git and version control, one question always comes up:
How do you do your branching at Microsoft?
And there’s no one answer to this question. Although we’ve been moving everybody in the company into one engineering system, standardizing on Git hosted in Visual Studio Team Services, what we haven’t done is move everybody into the same branching and development model.
Some teams — like Windows — have kept a branching strategy that is similar to the one that they’ve been using for many years. It’s hard to argue with this approach, they’ve got a lot of tooling to support it, and the developers have institutional knowledge about how things move between branches. Moving a team that big to Git was challenging enough — you can only boil so many oceans at the same time.
But this has led to some confusion in the way we talk about using Git: for example, Raymond Chen recently wrote an interesting series of blog posts explaining how you shouldn’t cherry-pick commits in Git. And while this is perfectly reasonable advice for his team’s workflows, it goes against the workflows that we use to build Visual Studio Team Services itself, and how the VSTS team works on a daily basis.
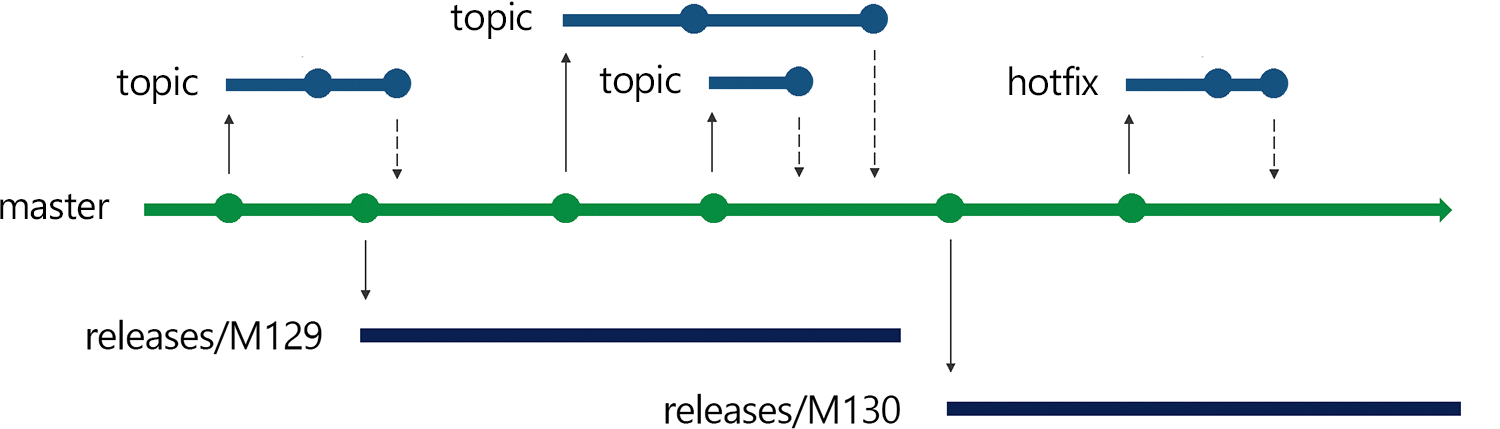
So, then — how do we do branching on the VSTS Team? First, we follow a trunk-based development approach. But unlike some trunk-based models, like GitHub Flow, we do not continuously deploy master to production. Instead, we release our master branch every sprint by creating a branch for each release. When we need to bring hotfixes into production, we cherry-pick those changes from master into the release branch. It’s a strategy that we call “Release Flow“.
Why Trunk-Based Development
We’re big fans of trunk-based development on the VSTS team. We like a simple branching structure where there’s a single master branch that everybody works in. This is much simpler than our old branching structure back in the dark days, many years ago, when our team was in the same TFVC repository as the Visual Studio IDE. We used to have this multi-level branching strategy that was — to be polite — ”complex”.
The more I talk to developers, the more I’ve observed something that tends to happen to teams that don’t do trunk-based development. No matter how organized they think they are, in fact, they tend to structure their branches in the same way. It’s a bit of a corollary to Conway’s Law:
Organizations tend to produce branching structures that copy the organization chart.
We were no exception: you could basically watch your code flowing through the org chart. When you checked in to your branch, your code would eventually be “forward integrated” into the next branch closer to trunk, eventually landing in trunk. Once that would happen, you’d want to “reverse integrate” trunk back up to all the feature branches so that you’d have everybody else’s code.
This is merge hell — yes, that’s actually what we called it — and we had a person employed full-time to deal with merging, conflict resolution and making sure all this integration continued to build. Whatever we paid him, it probably wasn’t enough.
Why We Don’t Continuously Deploy
When you back away from feature branches and start thinking about trunk-based branching strategies, the one that often comes up is GitHub Flow. (Note, that’s GitHub Flow, not Git Flow, which has two “trunks” and is therefore is not really trunk-based at all.)
I’m very familiar with GitHub Flow from my time working at GitHub. Overall, I really like this system; it’s lightweight and with good tooling and automation, you can be very productive. This system works pretty well for GitHub, but unfortunately, it doesn’t scale to the VSTS team’s needs. That’s because there’s a subtlety to GitHub Flow that often goes overlooked. You actually deploy your changes to production before merging the pull request:
Once your pull request has been reviewed and the branch passes your tests, you can deploy your changes to verify them in production… Now that your changes have been verified in production, it is time to merge your code into the master branch. — Understanding GitHub Flow
This system is extremely clever: when you’re ready to check-in, you get immediate feedback on how a pull request will behave in production, and that feedback happens before you complete the pull request. So if there’s a problem with your code changes, you can simply abandon the deployment, and your bad code never got merged into master. This lets you take a step back and look at the monitoring data to understand why your changes were problematic, then iterate on the pull request and try again.
The problem with this development strategy is that it scales extremely poorly to larger teams, because there’s contention when you’re trying to deploy to production:
During peak work hours, multiple developers are often trying to deploy their changes to production. To avoid confusion and give everyone a fair chance, we can ask Hubot to add us to the deployment queue. — Deploying Branches to GitHub.com
(If you’re not familiar with Hubot, it’s the core of GitHub’s chatops infrastructure. GitHub uses Hubot to perform their deployments from within Slack.)
When you have a few developers, you’re going to need a deployment queue to ensure that only one pull request can be deployed at once. This is great, but as you start to grow and hire more developers, there are more people in the queue. As your codebase grows, builds start to take longer. And as you get more popular, your infrastructure grows and with it, the time it takes to deploy.
Visual Studio Team Services has hundreds of developers working on it. On average, we build, review and merge over 200 pull requests a day into our master branch. If we wanted to deploy each of those before we merged them it, it would decimate our velocity.
We try to strike a balance where we want to code fast and get changes into master quickly, even if it takes them a little while longer to get into production. So instead of deploying every pull request to production, we deploy master to production at the end of each sprint — every three weeks. This means that a new feature could take that long to get into production. (And, of course, that new feature might only be enabled in testing, and not for all users, since we use feature flags in production.)
Sprintly Deployments
At the end of a sprint, when we’re ready to do a release, we create a new branch from master. This will be the release branch for the remainder of the sprint. While new feature work and development goes on in master, production stays nicely isolated from that work. Again, this keeps our development velocity moving quickly; we don’t have to worry about how long it takes to deploy these changes to our cloud of hundreds of servers spread across multiple Azure regions. We just open a pull request, get a code review and merge it into master.

We name these branches after the sprint that they correspond with. At the end of sprint 129, we create a branch named releases/M129 from master and deploy that. Once we finish development in sprint 130, we’re ready to deploy those changes to production; at that point, we forget about the old releases/M129 branch. Instead, we create a new branch named releases/M130 from master and deploy it. Once the releases/M130 deployment finishes — which would take a while, since we use a ringed deployment strategy — we don’t care about the old releases/M129 branch anymore. Once all the servers are running releases/M130 and there’s nothing with M129 in production, that branch is only of historical interest. We could even delete it.
Cherry-Picking Changes into Production
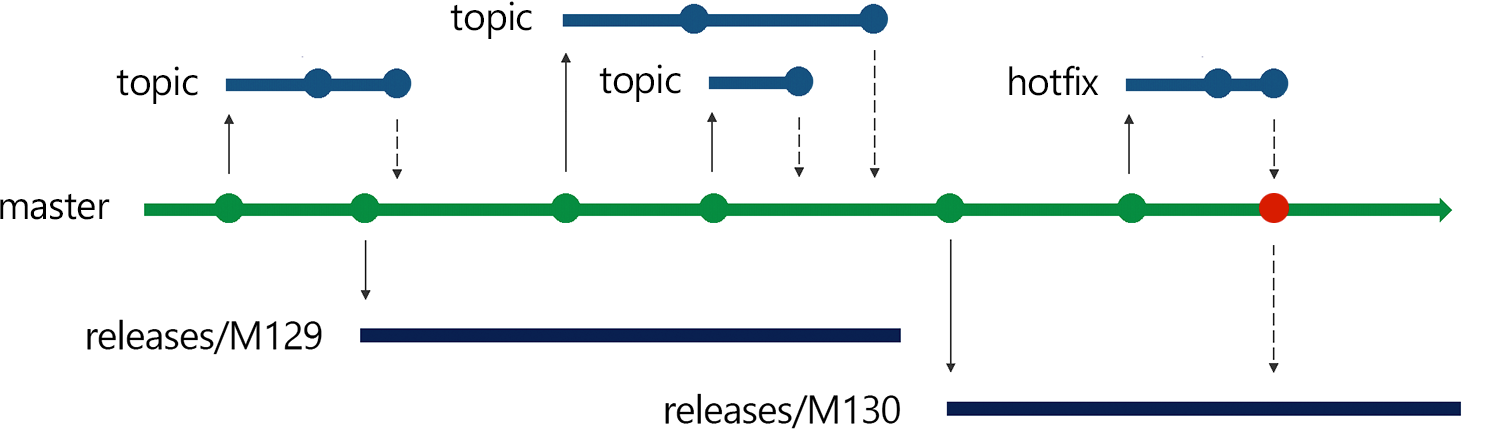
Of course, we don’t want production to exist in a vacuum. If there’s a high-priority bug or an availability issue, we need to be able to fix the problem quickly and deploy it immediately. That’s where cherry-picking comes in.
When we need to bring a change to production, we first make the change against the master branch. We get it code reviewed as usual — though at a bit higher priority than normal — and merge it into master. Then we cherry-pick that pull request into the current production release branch and start deploying it.
We find this workflow so useful that you can cherry-pick a pull request right from VSTS:

This actually cherry-picks the whole pull request, bringing each commit that made up the PR from one branch to another.
We always make production changes this way, starting in master; that’s because how the code gets into production is as important as the code that ultimately gets there. If we were to hotfix production directly, we might accidentally forget to bring a change back to master for the next release. But by bringing changes into master first, we ensure that we never have regressions in production.
This is so important that we ask if you’ve done it in the pull request template for our release branches:

The only exception, of course, is when the change doesn’t make sense to bring into master. Perhaps there’s been some refactoring that means that this bug doesn’t exist in master anymore. That’s the only time pull requests can go directly into a release branch without going through master first.
Even though this “master first” policy takes a few extra minutes, it’s always worth it. That’s especially true when you feel the time pressure to resolve a production incident, when you might be tempted to cut corners. It ensures that we only fix these bugs once and that we won’t have a repeat availability incident due to the same problem.
I hope that this gives some context behind the branching strategy we use on the VSTS team and why it works for us. Of course, for your branching strategy, you need to pick an approach that works for your team you have and the product that you’re building. And you should be willing to re-evaluate as those things change: as we transitioned from building an on-premises product shipping every few years to a cloud service deploying all the time, we had to change our branching strategy to fit. We needed a structure that would meet the challenges that we face today instead of fighting battles of the past. You do, too.
If you have any questions, please feel free to leave a comment — or if you’re coming to the Build 2018 conference on May 7th, then I’d love to chat in person. You can drop by the version control area on the expo floor, where I’ll be hanging out.
I would love to see a comparison between this and Git Flow. It seems to me, that Release Flow is aiming to solve the same problems that Git Flow solves, compared to Github Flow, but with different semantics. Are you basically just combining the Release branch with the Develop branch and calling them “M” branches? Which branch do you deploy to the various testing and staging environments?
Bit of time has passed, but to answer Vince’s question: to prevent regression.If you commit directly to the release branch and forget to cherry pick, your change could potentially be lost/regress in the next release. However, if you make that change to master first, there’s zero chance of regression. Edward admits it’s slower, but that extra assurance that they avoid merge hell is worth it.
A new blog post just came out (https://devblogs.microsoft.com/devops/improving-azure-devops-cherry-picking/) where the hotfix commits are applied to the current release branch and cherry-picked back into master and any other release branches (presumably not-yet-deployed). However, in your article, you state:-------------
We always make production changes this way, starting in master; that’s because how the code gets into production is as important as the code that ultimately gets there. If we were to hotfix production directly, we might accidentally forget to bring a change back to master for the next release. But by bringing changes into master first, we ensure that we never have regressions in production.
-------------Why...
Hi Edward! We met at Build just a few weeks ago. I'm curious how this kind of flow might work for a native application. Suppose development in the trunk removes a certain project from a solution after a release branch is cut. Now a bug is found in the release that deals with this project that got removed. You can't fix the bug in master and cherry pick merge. My guess is that in the case of the article here, that bug would just report that "it's fixed in the next release". But in a native app that is deployed...
You mentioned that you develop code in master branch then cut out a release branch when the release is ready. That means you do not use short-lived feature branches ? if yes then how you do code review in the same branch.? Please reply
Edward, how you are creating pull requests/Code review for master branch? when every once is working in the master then how you create the pull requests for the same branch.? i can’t see this option in Azure dev-ops
Hello Edward. We are possbily looking into this branching style, but we have a question in regards to hotfixes (change to production) and how you state above that you address them, which is:
"When we need to bring a change to production, we first make the change against the master branch. We get it code reviewed as usual — though at a bit higher priority than normal — and merge it into master. Then we cherry-pick that pull request into the current production release branch and start deploying it."
In that scenario, what if the file that the hotfix is in had someone already...
i have same question, the cherry-pick pull request cannot be created as there’s conflict. i also checked TBD official doc, https://trunkbaseddevelopment.com, no answer.could we have some suggestion here?
The only exception, of course, is when the change doesn’t make sense to bring into master. Perhaps there’s been some refactoring that means that this bug doesn’t exist in master anymore. That’s the only time pull requests can go directly into a release branch without going through master first.
Also, regarding Chads question In that scenario, what if the file that the hotfix is in had someone already update that file for the next sprint? Wouldn’t those changes that are for the next sprint then get put into production by cherry picking those changes (that file) onto the release branch and...
How do you keep track of history? Are you tagging master with release/m20 at the point of the branch? Also what is the purpose of creating a branch of that release it seems like a tag would serve the same purpose. Thanks!
Hi Edward, great post i have configured the environment at my workplace to work in a similar way, i however have some questions if you could help?I have a release pipeline set with the deployment stages "QA -> Initial Pilot -> General Release" with post-approval on each stage, however a critical bug has been found in the testing process of the "QA" stage, this has been fixed and merged into the `master` branch I now can cherry pick this PR into the `release` branch, however what happens to the current release pipeline?, do i abandon the current release, and create a new...