
Authored by Gaurav Sisodia from EPS team and Aseem Bansal from RM team.
In this post, we will talk about how VSTS organization (Brian Harry’s team) is using VSTS for continuous integration and testing the product. We will also talk about how we have transformed engineering systems from internal home grown tool, that we used to use for testing the product, to using release management.
What were we using before RM came?
Before we talk about how we are using Release Management (RM) today, let me talk about how we were testing TFS/VSTS product before RM was available and this will help in getting complete context.
Before RM, all teams were using an internal home grown tool called RollingTest and tfsruns for their continuous integrations runs. This tool was used by each feature team to configure their CI run(s) and to monitor them build over build for their product quality. In each of these runs, teams were deploying their product in a particular configuration and then running tests against it to check quality. For example: – test management feature team had one run for their on-prem configuration for master branch, one for dev-fabric configuration (i.e. VSTS setup) for master branch and similar configurations for release branches etc. The tool was being used by each of the VSTS service to monitor the quality for internal testing, and deployment like TFS service had
- TFS.SelfTest run which consisted of all P0 tests targeting TFS service and signify whether partners can consume the service for development.
- TFS.SelfHost run which consisted of all non P0 tests and that signifies that it is good for deployment to canary environment.
The rolling (or continuous integration) run was configured using rolling.xml (steps) on a machine. The rolling tests tool consisted of the following components: –
- An exe used to run on each of test machine and monitors the specified build definition for new successful builds, deploy the build and run tests using the steps specified in an xml file and report status of the steps to a home grown tfs server called tfsruns.
- A web interface where engineer can see the results of the various rolling runs, see the logs and diagnose failures. There were capabilities to create bug and see test history.
- A dashboard like widget where you can see the aggregated status of important runs build over build.



This tool had evolved over last 7+ years and was working well for us but it had mainly 2 problems.
- We were spending enough time/resources to maintain these tools.
- We were not using the product that we are shipping for internal testing requirements very broadly.
It is typically hard to convince all of the stakeholders that we should move away from a working system but it was easy here because : –
- Everyone was using RM for their production releases.
- RM team was using RM for their test runs from more than a year and in those test runs we were also deploying the same product tfs, VSTS services etc, as other teams. See Abhishek’s 18 months older post.
So as part of our effort to modernize engineering systems and achieve continuous deployment for our VSTS services, we set the goal of using VSTS product capabilities to test our product keeping the list of CI runs same like feature team CI runs, self test CI run etc. This will help in shaping our product by getting faster feedback.
Feature list
We evaluated RM and test reporting roughly 12-24 months ago for all testing requirements and came up with a good list of features that are required in the product for everyone to move away from RollingTest. We categorized our requirements in two buckets (Adoption Blockers and Enhanced experience) and built a feature backlog.
Adoption Blockers
- Ability to reuse a list of tasks in multiple environments in such a way that they don’t have to update each & every team’s release definition/environment to make a common change.
- Ability to queue only latest build on environments that take 3-4 hours to run tests as testing each & every build will require lot more resources.
- Ability to see health of the repo for N environments across different release definitions.
- Ability to timeout a task if it takes longer than specific timeout.
- Ability to trigger releases only from specific branches/tags so that engineers don’t end up running all the environments in their pre-check-in flows.
- Ability to pass oauth token to the scripts so that they can use it to make rest calls to VSTS.
- Environments should show “not deployed” when they are auto-cancelled.
Enhanced Experience
- Ability to schedule releases at more granular level.
- Ability to view history of a task group.
- Ability to view definitions that are using a task group.
- Ability to run deployments on various test environments in PR.
- Ability to find whether new or recurring failure of task.
- Ability to associate bug for task failure.
- Ability to see history of a task execution.
We added all the blocking features in the product since then and the important ones that I want to call out are as follows: –
- Task groups for reusability of processes across definitions along with its history/references.
- Queuing policy at environment.
- Branch/tag filters in release triggers/environment conditions.
- Deployment status widget.
- Timeout in task control options.
Current usage
In the first quarter of this year, we successfully moved all the feature teams within VSTS organization to start using RM and product capabilities system has been running well for last 3-4 months. In this section we will show how we use product’s native capabilities to setup continuous integration pipeline for each micro service.
- Exe got replaced with various agents and agent queues with notions of agent capabilities, request history, see health, enable/disable agents, update agents etc.
- Xml steps got replaced with release definitions/task groups which are editable in a nice editor.
- Monitoring of successful builds got replaced by triggers in RM with additional branch/tags filters.
- Result of various rolling runs is now available with rich traceability of commits/work items/tests that are being tested.
- Dashboard widget which takes me directly to the failing release/test run.






How different personas are using it day-to-day?
In this section we will cover the onboarding experience we have built for various services and the workflow of individual engineers and release managers for their daily needs.
Authoring continuous integration pipeline
Our goal is to make it easy for teams/engineers to setup continuous integration pipeline for their service and maintenance cost should be low. We have a common engineering systems and tools for all services and given this we have setup common release definition templates built using task groups which teams/engineers can reuse. Here are the important items that we follow to make the onboarding of feature teams easier.
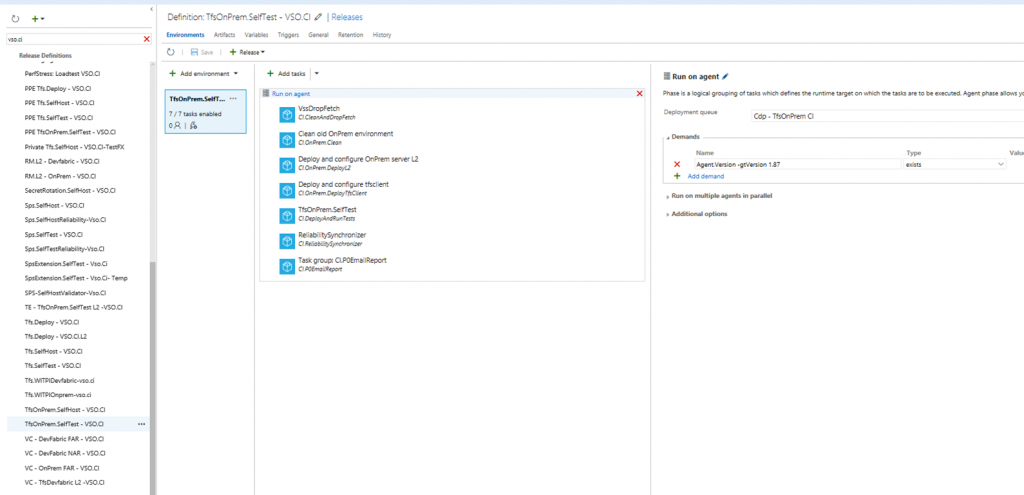
- We have created custom environment templates for the common test configurations like we test services in on-prem tfs, dev fabric (azure emulator) etc.
- The release definition created from these templates have multiple task groups which groups related tasks and it helps in abstracting out lots of internal details.
- CI.CleanAndDropFetch : It cleans the environments and downloads build drop
- CI.OnPrem.Clean: It cleans up stray product binaries and databases
- CI.OnPrem.DeployL2: Specifies the product that should be deployed. See next point for more details.
- TestRun: Deploys tests, runs tests and publishes results. Here each service should define the tests they want to run and thus are not part of the template.
- We define the product that should be deployed using the environment variables so that each feature team can define the services/components that they want to deploy.

 In the above environment, let us see what we are doing in the above task groups.
In the above environment, let us see what we are doing in the above task groups.
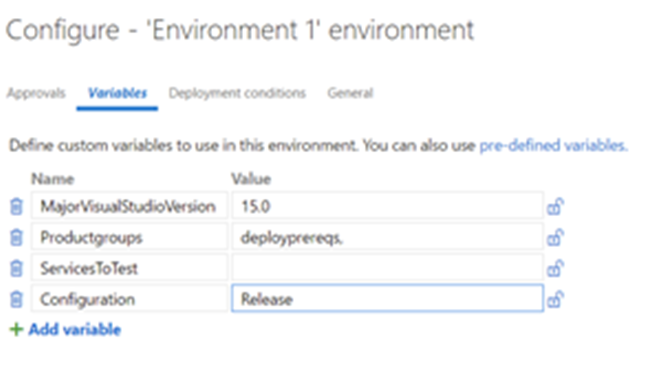
With this, each service is able to define their continuous integration pipeline !!
Engineers analyzing failure
Let us go through the engineer’s workflow who is responsible for keeping the engineering system healthy everytime.
- Engineer receives release notification email on failure and can navigate to releases.
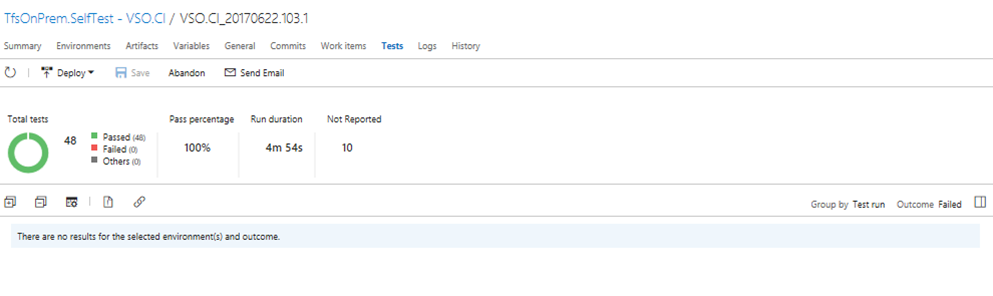
- (S)he can see failure with information on whether is a new failure or failing from past. In below example, it shows as failing from this release.
- (S)he can click on create bug icon and below workitem form opens up with all information populated
- Second engineer who gets the bug, can look into attached logs to diagnose and fix the issue either by fixing or reverting a commit.


Super easy workflow for the engineer to file actionable bugs !!
Release owner checking readiness for release
Let us go through the release owner’s workflow who is responsible for deploying their services to production.
- They look at configured dashboard to see the quality of build in various environment configurations.
- They can click on the individual cells above to drill into the failure in a specific configuration.
- They can see the bugs associated with the failure and then see who owns fixing those bugs.
- If all the configurations are green for a given build, then they can choose to proceed with the deployment to canary environment.


What’s left?
As I mentioned above, we are done with all the blocking features that EPS needed and the new system is working fine but there were “good to do” features that are pending and that list is here.
- Ability to do test deployments in various configurations in PR workflow.
- Ability to view current state w.r.t. deployment of a given commit.
Enjoy !!
0 comments