
Introduction
In media companies, like WarnerMedia, footage filmed for the entire day include ‘takes’ of various scenes or footage types as well as footage before and after each take. This footage filmed each day is known as ‘digital dailies’.
Archival of digital dailies is a manual and time-consuming process. When digital dailies are produced all the data is permanently archived, however there is a portion of that content that should either be long-term archived or completely discarded. The problem here is two-pronged: 1. It’s an expensive manual process to identify which portions of content can be archived and/or discarded and 2. There is a cost associated with storing unnecessary content, especially when we are dealing with terabytes and petabytes of data.
This project is a co-engineering collaboration between WarnerMedia and Microsoft’s Commercial Software Engineering for identifying action and cut sequences within media for archival purposes.
Goals
Our primary goal was to use Machine Learning to identify archival content from WarnerMedia digital dailies, that could be either long-term archived or discarded, to reduce storage costs.
Exploring the Possibilities
We focused on identifying “action” and “cut” using visual and audio cues in the footage as a means of demarcating the content to identify portions for long-term storage and portions that can be discarded.
When an “action” event has been identified, and up to a “cut” event, that’s content that should be kept. When “cut” happens, and up to the next “action” that’s content that could be archived or discarded.

To accurately detect “action” and “cut”, the Data Science team iterated through many different services and experimentations.
Visual Exploration:
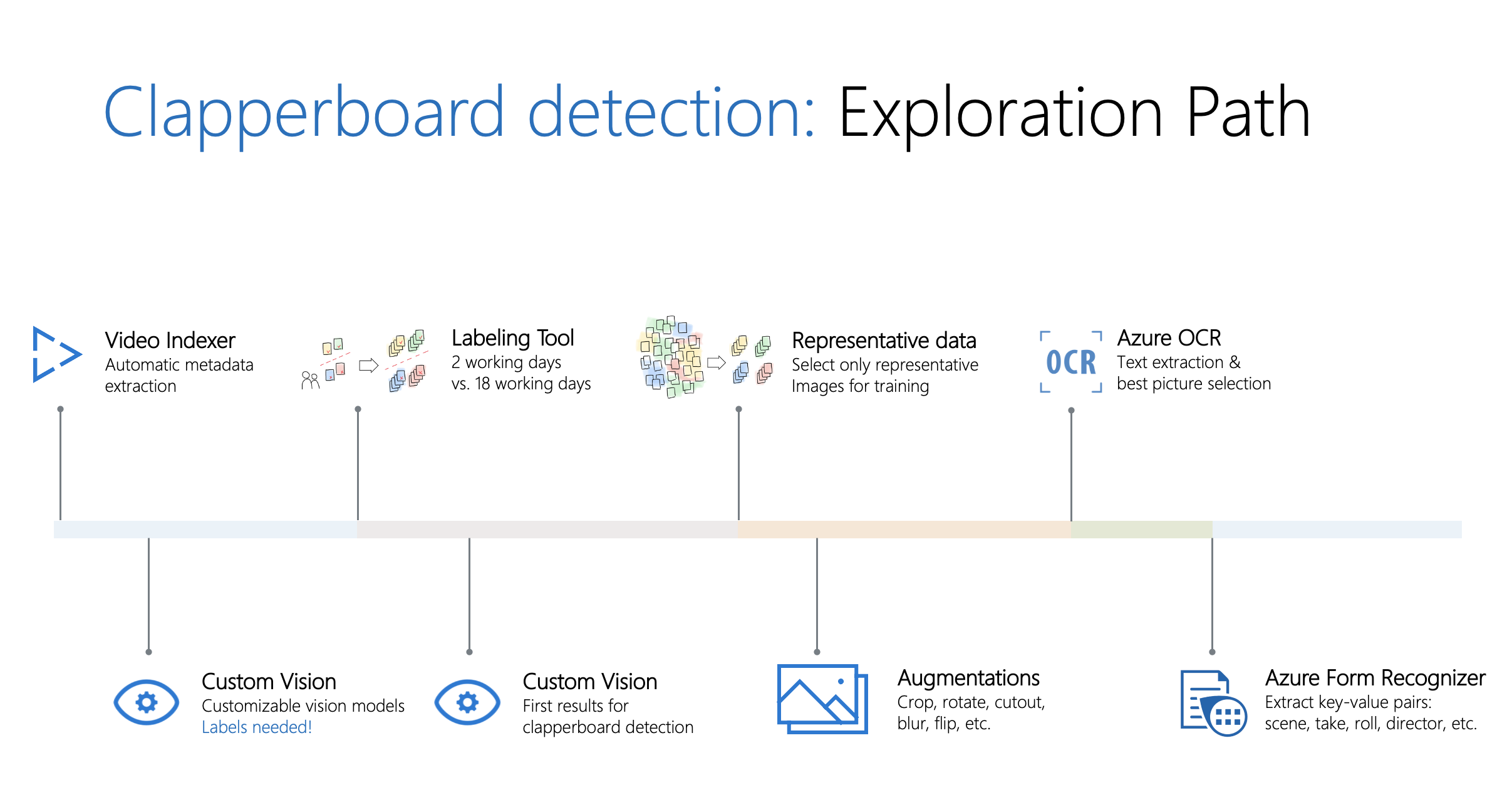
The goal with the visual exploration is to identify clapperboards within frames of video and extract text from those clapperboards. The exploration consisted of:
- Automatic metadata and insights extraction using Azure Video Analyzer for Media (formerly known as Video Indexer).
- Selecting and generating a representative dataset of frames for model training.
- Augmenting images within the dataset by utilizing crop, rotate, cutout, blur, flip techniques and more.
- A semi-supervised labeling tool to automatically group similar labels using density-based spatial clustering.
- Training and utilizing Azure Cognitive Services Custom Vision models to detect clapperboard images against various backdrops.
- Clapperboard detection with trained Azure Cognitive Services Custom Vision models
- Training a custom model in Azure Form Recognizer to detect and extract items such as “roll”, “scene”, “take”, etc. in detected clapperboard images.
- Using Azure Cognitive Services Computer Vision Read API (OCR) to choose the “best” clapperboard frame (clapperboard image with the most detectable text) for each action event.
- Using a trained custom model in Azure Form Recognizer to extract key value pairs (such as “scene”, “roll”, “take”, etc.) from detected clapperboard images.
Audio Exploration:
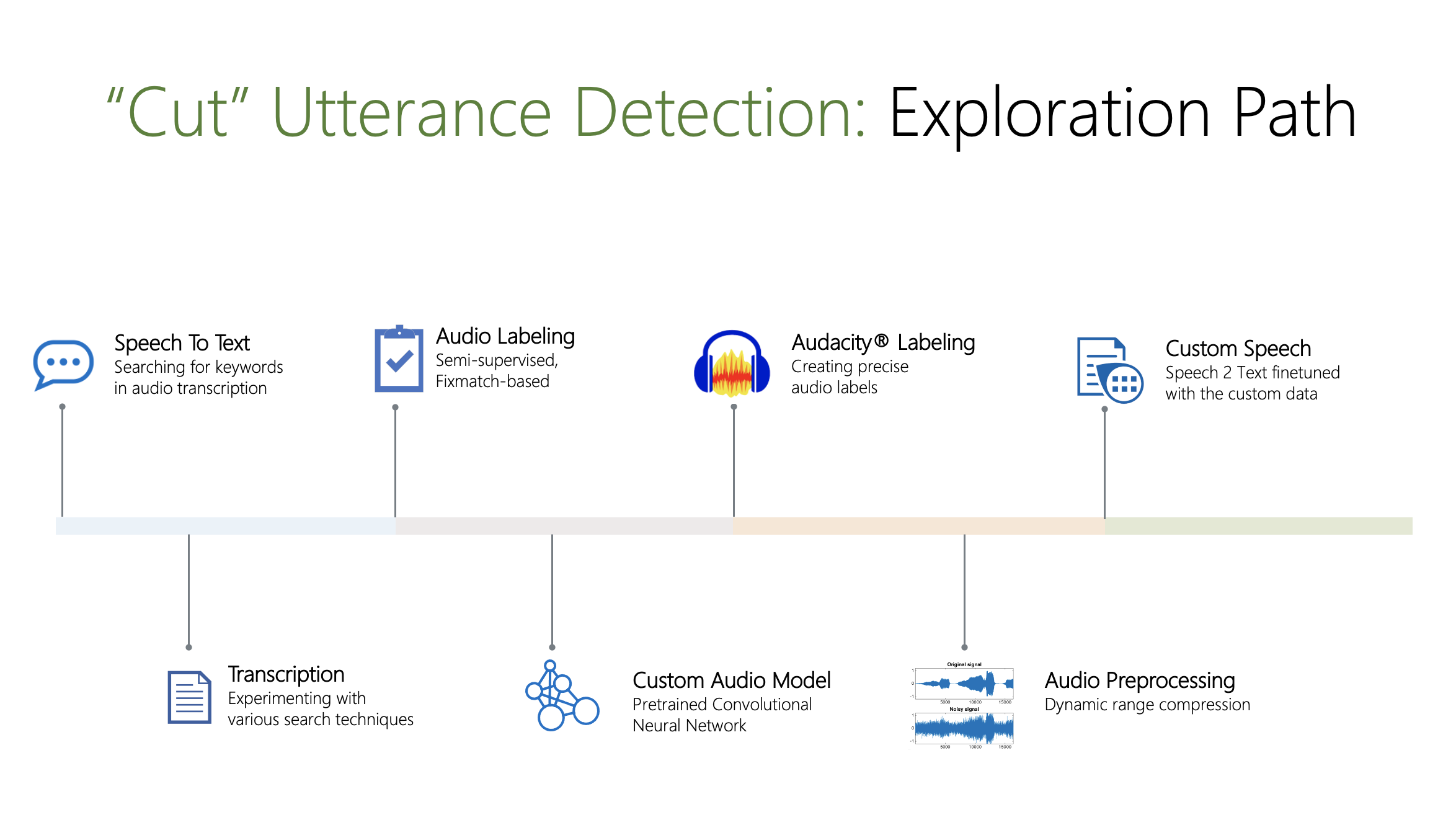
Here we had to accurately detect the spoken word “cut”. The exploration consisted of:
- Utilizing the Speech to Text Cognitive Service
- Experimenting with search techniques
- Semi-supervised, FixMatch-based audio labeling
- Custom Audio Model with a pre-trained Convolutional Neural Network
- Using the OSS Audacity® for creating audio labels
- Audio preprocessing using Dynamic range compression
- Utilizing the Custom Speech to Text service fine-tuned with custom data
Overall Design
After the initial exploration phase of the project the team decided the best way to go was a combination of utterance and clapperboard detection. We decided to proceed with the following services for the final solution:
Here is a look at the final scoring pipeline process.
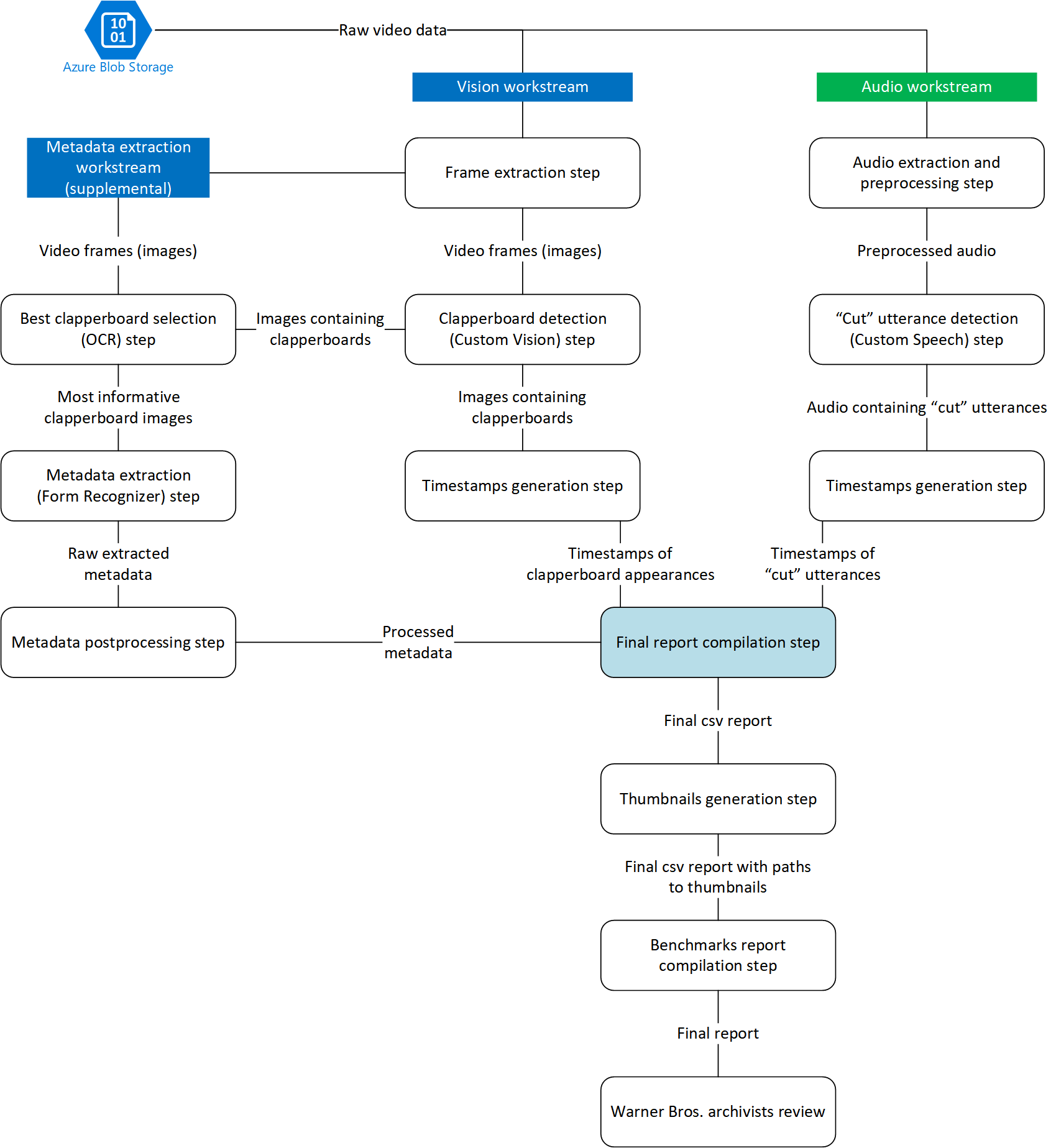
In the scoring pipeline there are three workstreams: audio, vision, and metadata extraction. These three workstreams extract out the audio and visual cues from the raw video and compile those into a final report which identifies “action” and “cut” at the various timestamps within the video.
And to tie the above services together we used Azure Machine Learning to run training and scoring pipelines for the various cognitive services.
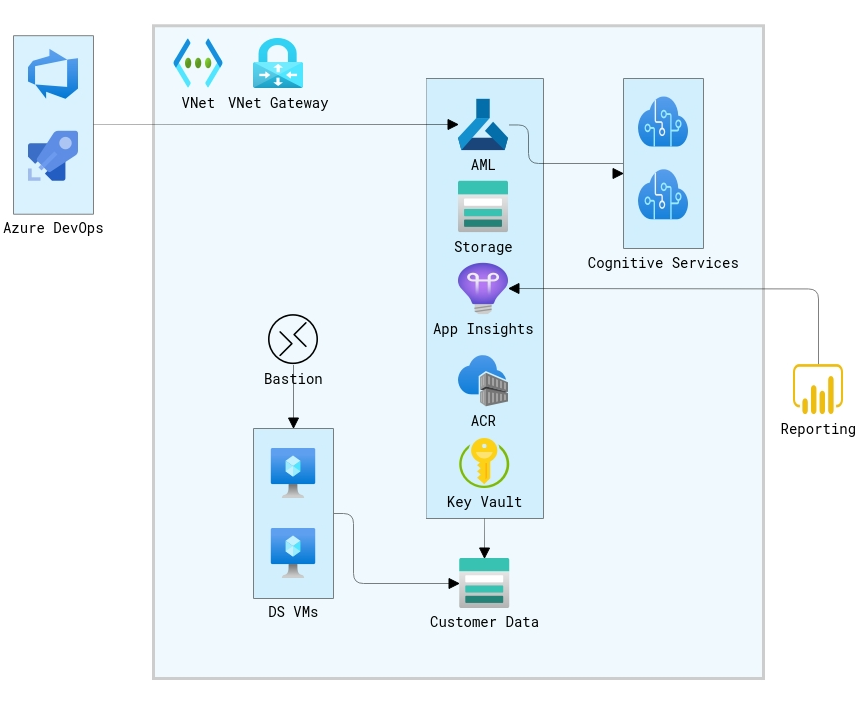
We created an architecture with training pipelines for MLOps (Machine Learning Operations) to efficiently maintain, train, and deploy models. In this architecture the pipelines would first run against simplified datasets for PRs, then after merging, they would run full training pipelines and train the various models. From this point, models could be promoted to production to be used as the primary scoring model. At a high level the infrastructure looks like this:
Results
The results turned out to be excellent with the precision and recall both being 96%. The precision meaning how much discardable footage was labeled archive and recall meaning did we archive all the footage of interest.
For content with audio, we were able to discard around 45% of the content, that means eliminating storage costs completely for the discarded content, and we marked around 55% of content for long-term archival, that means lower costs for cheaper storage tiers. When referring to long-term archival, Azure provides both ‘cool’ and ‘archive’ storage for reduced costs instead of storing everything in the ‘hot’ tier.
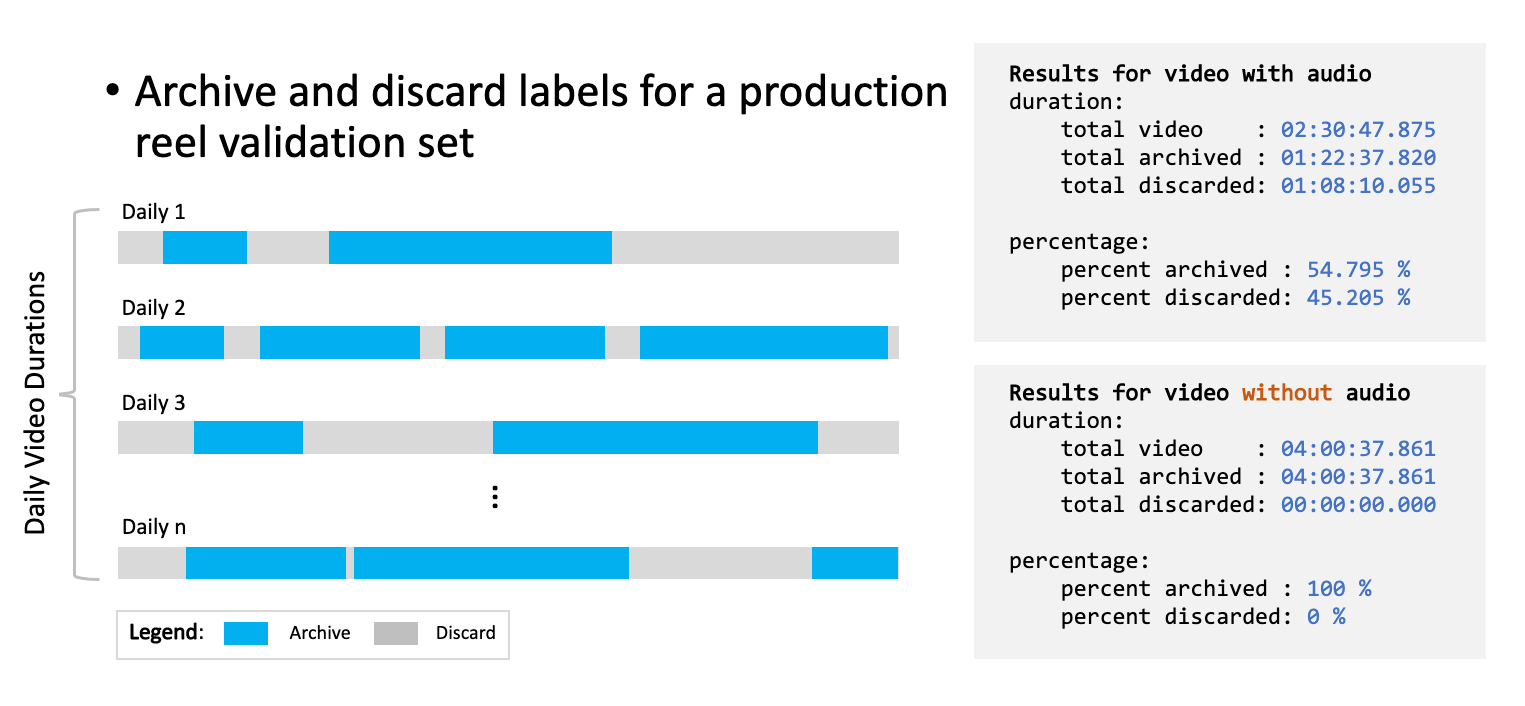
Note that for video with no audio, 100% of the content is marked archive. The reason being that audio is required to detect “cut” utterances denoting the end of takes, which is necessary for identifying segments of footage that can be discarded. Without this additional audio component, the confidence to completely discard a portion of the video content would decrease.
Summary
This project demonstrated an effective iterative process in exploring Machine Learning techniques where Data Scientists were able to utilize various techniques to progressively increase the precision and recall through a combination of visual and audio workstreams. Along with the accomplishment of reaching a precision and recall of 96% the software engineers on the team created infrastructure as code and DevOps/MLOps code and configuration that allowed for both quick deployment and exploration on the ML side and also effective promotion of the trained models to production.
For a deeper dive into the work done by the Data Scientists please see Detecting “Action” and “Cut” in Archival Footage Using a Multi-model Computer Vision and Audio Approach with Azure Cognitive Services.
Acknowledgements
Special thanks to the engineers and contributors from Deltatre and WarnerMedia and especially Michael Green and David Sugg.
Also, a big thank you to all contributors to our solution from the Microsoft Team (last name alphabetically listed): Sergii Baidachnyi, Andy Beach, Kristen DeVore, Daniel Fatade, Geisa Faustino, Moumita Ghosh, Vlad Kolesnikov, Bryan Leighton, Vito Flavio Lorusso, Samuel Mendenhall, Simon Powell, Patty Ryan, Sean Takafuji, Yana Valieva, Nile Wilson