
Distributed Deep Learning Model Training on Batch AI For Land O’Lakes Sustainability Project
With population growth spiking around the world, and scientists warning of the risk of climate change on the environment around us, across industries corporations are turning to innovation to help them make practices greener and more sustainable. This is especially true in the agricultural industry. However, while leading agricultural organizations are pushing for positive change in practices, it can be harder to convince individual farmers that they should change lifelong practices to help improve sustainability and limit the damaging effects on the nature around us.
Land O’Lakes is the second largest farming co-op in the U.S. with three businesses: seed, animal feed, and dairy. In recent years, the cooperative has been on a mission to make farming methods more sustainable and to convince other farmers to do the same. However, one of the first issues which the coop has come up against is highlighting farms where sustainable practices are being used due to their remote locations.
To tackle this issue, Microsoft and Land O’Lakes partnered to develop an automated solution to identify sustainable farming practices given thousands of satellite images of Iowan farms. Our primary goal was to reduce the reliance on manual interviewing of farmers and make it more profitable for farmers to follow sustainable farming practices.
Challenge and solutions
Since Land O’Lakes aimed to train its deep learning model with a large set of images from farms across the whole state of Iowa — the 25th largest state in the US in terms of size — this meant managing a huge amount of data from large teams of data scientists. As such, one of the main challenges facing our team was working out how to take the current AI workload that their data science teams were working on their personal computers and deploy it into the cloud. Doing so would allow data science teams to take advantage of all the benefits of Azure, such as reduced entry cost, efficient data management and storage, elastic bursting, resiliency and more efficient team collaboration.
Due to the nature of our problem, we needed to choose a distributed platform that supported AI model training. To tackle this issue our team deployed a highly scalable Batch AI cluster on Azure and then performed distributed deep learning model training using the Horovod framework.
Deciding on a service for model training
Several options exist to deploy and execute deep learning training on the cloud. Today, managed services like Functions and App Services are capable of deploying and using pre-trained models. Nevertheless, training a model from scratch using these platforms would require excessive amounts of time and resources (data and compute). We first considered using Kubeflow. This option would have required us provisioning a Kubernetes cluster with all the infrastructure needed for training such as networking, storage, etc. Kubeflow authors recommend using their service for training / serving Tensorflow models under many circumstances like multi-cloud or hybrid (on premise-cloud) scenarios. Unfortunately, at the time we working with Land O’Lakes, Kubeflow only supported three main operators: Tensorflow, PyTorch, and Caffe2. For its ease of use on distributed computing , we wanted to use Horovod, which was not currently supported by Kubeflow.
Rather than using Kubeflow, we decided instead to use Azure Batch AI, because it supported Horovod and provided infrastructure for distributed model training. Batch AI allowed us to easily provision managed infrastructure on Azure, and there was no requirement to have an extensive background on infrastructure or Kubernetes. It also supported mounting various file systems and launching training jobs formatted in JSON. In addition, Batch AI supported popular frameworks and libraries like Horovod, Tensorflow, CNTK, Caffe2, Chainer, Keras, PyTorch and many more through its custom toolkit support.
Batch AI background
To use the Batch AI service, we first needed to configure a cluster and a set of jobs. Figure 1 shows a basic sample architecture of a Batch AI cluster running on NC Virtual Machines using Azure Storage as its data source and Docker Hub as its image registry. The architecture diagram below can be optimized further, by using a parallel storage option like GlusterFS rather than Azure Files, but its main purpose is to exemplify how the resources interact.
The following sections describe how we set up a cluster and ran training jobs.

Before deploying a cluster – Batch AI configuration
We needed to consider a few options when provisioning a cluster for Land O’Lakes:
- CPU, GPU, memory, and network
- Storage
- Deep learning libraries
Choosing a virtual machine
CPU, GPU, and memory depend on the selected SKU of the Azure virtual machine. Referring to GPU optimized virtual machines, the official documentation lists NC’s ND and NV sizes and the following table gives a summary of their main objectives:
| N Series | Graphic Card | Description |
| NC | NVIDIA Tesla K80 | NC series are optimized for compute-intensive and network-intensive applications and algorithms, including CUDA- and OpenCL-based applications and simulations, AI, and Deep Learning. 2 Tesla GK210 GPUs. |
| NC v2 | NVIDIA Tesla P100 | 2x NC performance. |
| NC v3 | NVIDIA Tesla V100 | 1.5 x NCv2 performance. |
| ND | NVIDIA Tesla P40 | Larger GPU memory size (24 GB), enabling to fit much larger neural net models. |
| NV | NVIDIA Tesla M60 | Designed for remote visualization, streaming, gaming, encoding, and Virtual Desktop Infrastructure (VDI) scenarios utilizing frameworks such as OpenGL and DirectX. GRID licensed for desktop use. |
| Size | vCPU | Memory
GiB |
Temp storage (SSD) GiB | GPU | Max data disks | Max NICs |
| NC6s v3 | 6 | 112 | 736 | 1 | 12 | 4 |
| NC12s v3 | 12 | 224 | 1’474 | 2 | 24 | 8 |
| NC24s v3 | 24 | 448 | 2’948 | 4 | 32 | 8 |
| NC24rs v3* | 24 | 448 | 2’948 | 4 | 32 | 8 |
Storage
Choosing a storage option was not an easy task, as there were so many factors to consider. For example, the optimal storage option depends a lot on the size of data and the speed at which records should be read. Also, it depends on where the data is located and how difficult it is to transfer data to the desired cloud location. Nevertheless, Batch AI offers several storage options to choose from:
- Local Disk. Used mostly for testing purposes.
- Azure Files. Easy implementation.
- NFS Server and Parallel File Systems (Lustre, Gluster, BeeGFS, BlobFuse, etc). Best performance, but must be provisioned by the user.
Batch AI quick-start documentation examples use Azure Files, so this would be the easiest option to get started when having small amounts of data. Nevertheless, for large data sets, it would be more appropriate to use either NFS Server or parallel file systems. If a parallel file system is chosen, then a custom VNet must be set in place where both the File System and the Batch AI cluster would be located. More information on how to achieve this can be found here. We went with Azure Files for Land O’Lakes, since it was quick and easy to set up for initial investigation. In the future, we would move to using a parallel file system to get the best performance.
For transferring files, there are also many tools like BlobPorter and AzCopy. For sufficiently small data sources (under 100 GB), it’s enough to wait for the storage solution (like Azure Files) to be mounted in the cluster /mnt/batch/tasks/shared/LS_root/mounts, then establish a SSH connection with one of the virtual machines in the cluster, and finally use wget or curl to copy the files into the selected mounted service. In the hackfest, we used wget to copy the files into Azure Files and this was sufficient as we were only copying a few gigabytes of data.
Batch AI cluster deployment
Now that we had chosen the components of our infrastructure, we were easily able to set up a configuration to deploy our Batch AI cluster. There is official documentation on deploying a Batch AI cluster in Azure Batch AI QuickStart using the Azure CLI, but we also created an interactive bash script to make cluster deployment easier and this script was how we deployed our cluster. The main requirement to run the script is a bash terminal with Azure CLI and SSH client installed. Another easier option is to use the Azure Cloud Shell because it already has the latest Azure CLI installed. The cluster provision script has a number of preset cluster configurations.
The following sections will describe considerations we made when provisioning Batch AI jobs to run distributed training.
Batch AI jobs
After we provisioned a cluster of NC24rs nodes with our interactive script, we needed to create a training job script to train our model. We chose Horovod because it was easy to configure distributed training.

Let’s discuss our job.json file below, which we used as a basis for our training for Land O’Lakes:
The job.json file defines several environment variables like HOROVOD_TIMELINE and NUM_NODES. Also, it used Batch AI custom toolkit settings to run Horovod training. In addition, it defined the location of the common files to be used within the training processes: input scripts, output files, and logs. Finally, there is a defined Docker image that will be the base environment for the job to run and a job preparation script to install custom python libraries not included in this base image.
job.json sample
{
"$schema": "https://raw.githubusercontent.com/Azure/BatchAI/master/schemas/2017-09-01-preview/job.json",
"properties": {
"nodeCount": 2,
"environmentVariables": [
{
"name": "NUM_NODES",
"value": "2"
},
{
"name": "PROCESSES_PER_NODE",
"value": "4"
},
{
"name": "HOROVOD_TIMELINE",
"value": "$AZ_BATCHAI_OUTPUT_TIMELINE/timeline.json"
}
],
"customToolkitSettings": {
"commandLine": "$AZ_BATCHAI_INPUT_SCRIPTS/run-cifar10.sh"
},
"stdOutErrPathPrefix": "$AZ_BATCHAI_MOUNT_ROOT/external/storagedir",
"outputDirectories": [
{
"id": "MODEL",
"pathPrefix": "$AZ_BATCHAI_MOUNT_ROOT/external/storagedir/horovod",
"pathSuffix": "models"
},
{
"id": "TIMELINE",
"pathPrefix": "$AZ_BATCHAI_MOUNT_ROOT/external/storagedir/horovod",
"pathSuffix": "timelines"
}
],
"inputDirectories": [
{
"id": "DATASET",
"path": "$AZ_BATCHAI_MOUNT_ROOT/external/storagedir/horovod/data/cifar-10-batches-py"
},
{
"id": "SCRIPTS",
"path": "$AZ_BATCHAI_MOUNT_ROOT/external/storagedir/horovod"
}
],
"containerSettings": {
"imageSourceRegistry": {
"image": "tensorflow/tensorflow:1.6.0-gpu"
}
},
"jobPreparation": {
"commandLine": "$AZ_BATCHAI_INPUT_SCRIPTS/job-prep.sh"
}
}
}
Docker image
Once we had chosen the machine learning framework and provisioned our cluster, we had enough information to create an environment suitable for the training script. One of the features that Batch AI provided was that it could run our training scripts on top of predefined docker images. This made it easier to be consistent within a development and production environment. During Microsoft’s engagement with Land O’Lakes, two main strategies were used to obtain the perfect docker image:
- Using a standard docker image and installing the needed packages through the job preparation commands. A couple of useful docker images examples are: CNTK, Tensorflow, Caffe2, and Chainer.
- Creating a custom dockerfile and improving it step by step until it fits the needs of the job, deploying it to a public or private docker registry, then pointing the job.json file to that location including (if needed) the registry credentials.
We went with using a standard docker image, tensorflow/tensorflow:1.6.0-gpu and then installed other necessary custom libraries that were not included in the base image in our jobPreparation script, job-prep.sh.
job-prep.sh script
#!/bin/bash apt-get update -y apt-get install -y -q -o Dpkg::Options::="--force-confold" --no-install-recommends cpio libdapl2 libmlx4-1 libsm6 libxext6 wget git # Install intel MPI cd /tmp wget -q 'http://registrationcenter-download.intel.com/akdlm/irc_nas/tec/11595/l_mpi_2017.3.196.tgz' tar zxvf l_mpi_2017.3.196.tgz sed -i -e 's/^ACCEPT_EULA=decline/ACCEPT_EULA=accept/g' /tmp/l_mpi_2017.3.196/silent.cfg sed -i -e 's|^#ACTIVATION_LICENSE_FILE=|ACTIVATION_LICENSE_FILE=/tmp/l_mpi_2017.3.196/USE_SERVER.lic|g' /tmp/l_mpi_2017.3.196/silent.cfg sed -i -e 's/^ACTIVATION_TYPE=exist_lic/ACTIVATION_TYPE=license_server/g' /tmp/l_mpi_2017.3.196/silent.cfg cd /tmp/l_mpi_2017.3.196 ./install.sh -s silent.cfg cd .. rm -rf l_mpi_2017.3.196* echo "source /opt/intel/compilers_and_libraries_2017.4.196/linux/mpi/intel64/bin/mpivars.sh" >> ~/.bashrc # install horovod source /opt/intel/compilers_and_libraries_2017.4.196/linux/mpi/intel64/bin/mpivars.sh pip install horovod absl-py keras h5py
Because we created a cluster of NC24rs nodes with Infiniband enabled, we found that the RDMA capabilities on the InfiniBand network on Azure were only supported through Intel Message Passing Interface (MPI) and not other frameworks. At the moment of writing this article, there is no support for Open MPI nor support for NCCL. This means that the Intel MPI packages must be installed on each node and its End User License Agreement must be accepted whenever this feature is needed. For example, we used the provided job-prep.sh file to install Intel MPI libraries and accept the EULA.
Secondly, any dependencies required for the python training script should be either installed directly in the custom Docker image (not in python virtual environment), or include the installation commands on the jobPreparation section of the job.json file.
We found that Batch AI containers run in a headless state, so any CMD or ENTRYPOINT statements in the dockerfile caused the container to exit. This could be counter-intuitive for conda users, as they may want to have an ENTRYPOINT statement to start the container with a certain version of Python. In this training example, a python 3.5 environment in a custom docker image was needed, so to bootstrap adding the environment activation a /root/.bashrc file was placed with all the CMD statements needed in the container. For example, to activate a conda environment, the following line can be added to the dockerfile:
RUN echo "source activate-py35.sh" >> /root/.bashrc
Running the training (run-cifar10.sh)
Training will be run as MPI processes. BatchAI defines a hostfile with all the nodes that are used by MPI. In our example, the training was done on two nodes, each with four Tesla K80 GPUs, so eight processes in total:
#!/bin/bash
source /opt/intel/compilers_and_libraries_2017.4.196/linux/mpi/intel64/bin/mpivars.sh
mpirun -n 8 -ppn 4 -hosts $AZ_BATCH_HOST_LIST
-env I_MPI_FABRICS=dapl
-env I_MPI_DAPL_PROVIDER=ofa-v2-ib0
-env I_MPI_DYNAMIC_CONNECTION=0
python $AZ_BATCHAI_INPUT_SCRIPTS/cifar10_cnn.py
--data-dir $AZ_BATCHAI_INPUT_DATASET
--model-dir $AZ_BATCHAI_OUTPUT_MODEL
--batch-size 64
--epochs 5
--verbose 1
Deep learning libraries
Batch AI does not distribute the training workload automatically. It is up to the training python script to determine the parallel training strategy that will be used, and the training strategies available depend largely on the machine learning framework. For example, during training, Batch AI will not aggregate and reduce computed gradients from each worker node, because that is determined by the parallel training strategy defined in the script.
There are two main parallel training strategies: model-parallel distributed training, and data-parallel distributed training. Model-parallel distributed training is where each worker is responsible for performing updates to a subset of model parameters and has access to the entire dataset. Data-parallel distributed training is where each worker is responsible for computing gradients on a subset of the data set and each worker would have a copy of the entire model.
For instance, to set up a data-parallel-training strategy, one can use distributed CNTK learners like data_parallel_distributed_learner, block_momentum_distributed_learner and a Communicator. In this case, the training script will use synchronous, distributed training with CNTK. Workers would communicate proposed gradient updates to each other before the next minibatch begins so that at the beginning of the next minibatch, all workers have an identical copy of the model.
Given the choice between model parallel and data parallel options, there are still tendencies to prefer some frameworks over others in terms of ease of use. Also, when considering distribution and efficient use of hardware resources, make careful consideration of the backend framework. To provide more context into how the choice of machine learning framework impacts the efficient use of hardware resources, the next sections will provide a comparison between standard distributed Tensorflow and Horovod, a framework that makes distributing frameworks like Tensorflow easier in a few lines of code. During our hackfest with Land O’Lakes, we found that setting up distributed training with Horovod was much easier than setting up distributed training with Tensorflow.
Standard distributed Tensorflow
We originally tried setting up standard distributed Tensorflow as our backend framework. Working with distributed Tensorflow was tough because it required many code changes and a deep understanding of Tensorflow’s low-level API to be successful. Moreover, Tensorflow required several boilerplate code changes to enable distributed training such as defining a tf.Server() , tf.ClusterSpec() , tf.train.SyncReplicasOptimizer(), etc. For Land O’Lakes, we ran into many challenges like debugging distributed code changes and spent a lot of time trying to understand the lower-level API.
In addition to complicated code changes, because distributed Tensorflow uses parameter servers to average gradients, one also needs to do a careful selection of a proper ratio of parameter servers to workers. Parameter servers can become a computational bottleneck if not enough parameter servers exist and a network bottleneck if too many parameter servers exist. With too many parameter servers, communication may saturate the network (Figure 2).

Another consideration is the efficient use of hardware resources when scaling up to 128 GPUs or more. Because Tensorflow uses parameter servers, Tensorflow does not efficiently use hardware resources at 128 GPUs or more due to communication with parameter servers, shown in Figure 3. At 128 GPUs, standard distributed Tensorflow may only use hardware resources at 50% capacity.

Horovod
As a result of Tensorflow’s inefficient use of hardware resources due to parameter servers, we created Horovod. Horovod is a framework that makes it easier to distribute machine learning frameworks like Tensorflow, PyTorch, and Keras, in just a few lines of code. Horovod uses MPI to set up the distributed infrastructure necessary for the workers to communicate. To distribute Tensorflow code with Horovod, we only needed to add a few lines of code without changing our model.
We created a Convoluted Neural Network (CNN) model to train on CIFAR-10 data and were able to perform distributed training on a Batch AI cluster. From this model, we were able to adapt the initial architecture to support the satellite imagery from Land O’Lakes. Below is are some lines we needed to add to our code to make our training distributed:
# Horovod: initialize Horovod hvd.init() # Horovod: pin GPU to be used to process local rank (one GPU per process) config = tf.ConfigProto() config.gpu_options.allow_growth = True config.gpu_options.visible_device_list = str(hvd.local_rank()) K.set_session(tf.Session(config=config)) # Build the model model = ... # Initiate RMSprop optimizer # RMSprop: An (unpublished) adaptive learning rate method proposed by Geoff Hinton in Lecture 6e of his Coursera Class. opt = keras.optimizers.rmsprop(lr=learning_rate, decay=1e-6) # Horovod: add Horovod Distributed Optimizer. opt = hvd.DistributedOptimizer(opt) # Train the model using RMSprop model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) callbacks = [ # Horovod: broadcast initial variable states from rank 0 to all other processes. # This is necessary to ensure consistent initialization of all workers when # training is started with random weights or restored from a checkpoint. hvd.callbacks.BroadcastGlobalVariablesCallback(0), ] # Horovod: save checkpoints only on worker 0 to prevent other workers from corrupting them if hvd.rank() == 0: callbacks.append(keras.callbacks.ModelCheckpoint(data_dir + '/logs/checkpoint-{epoch}.h5')) callbacks.append(keras.callbacks.TensorBoard(data_dir + '/logs'))
Using these code changes, our team was able to run training with MPI on a CNN model written with Keras and using a Tensorflow 1.6 backend with Horovod to enable distribution on the model training.
It is important to acknowledge that Horovod’s distribution model is different from the standard Tensorflow’s distribution model. Rather than using parameter servers, Horovod takes advantage of a new way of averaging gradients, the ring-allreduce algorithm (Figure 4).
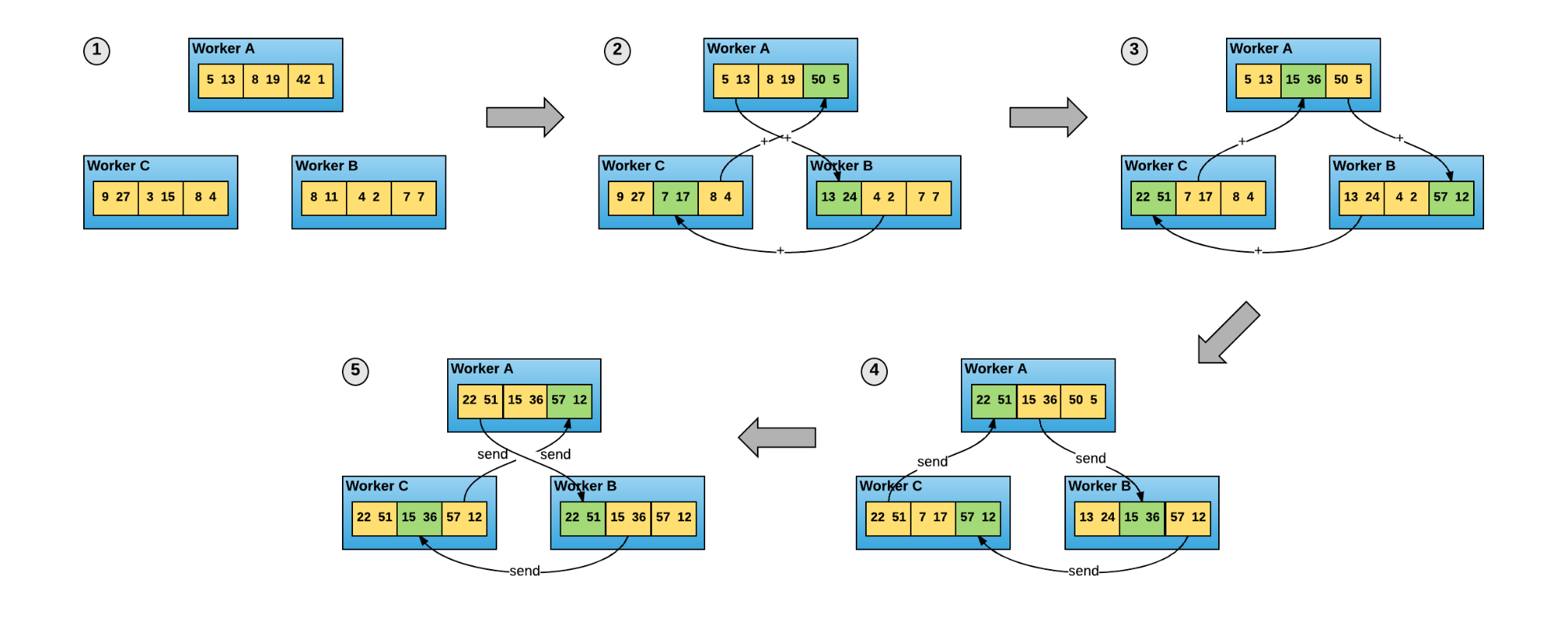
Because Horovod uses ring-allreduce, less communication is needed over the network, so more efficient use of hardware resources is possible. Figure 5 shows a more efficient use of hardware resources at 128 GPUs than standard distributed Tensorflow, due to less communication overhead provided by ring-allreduce.
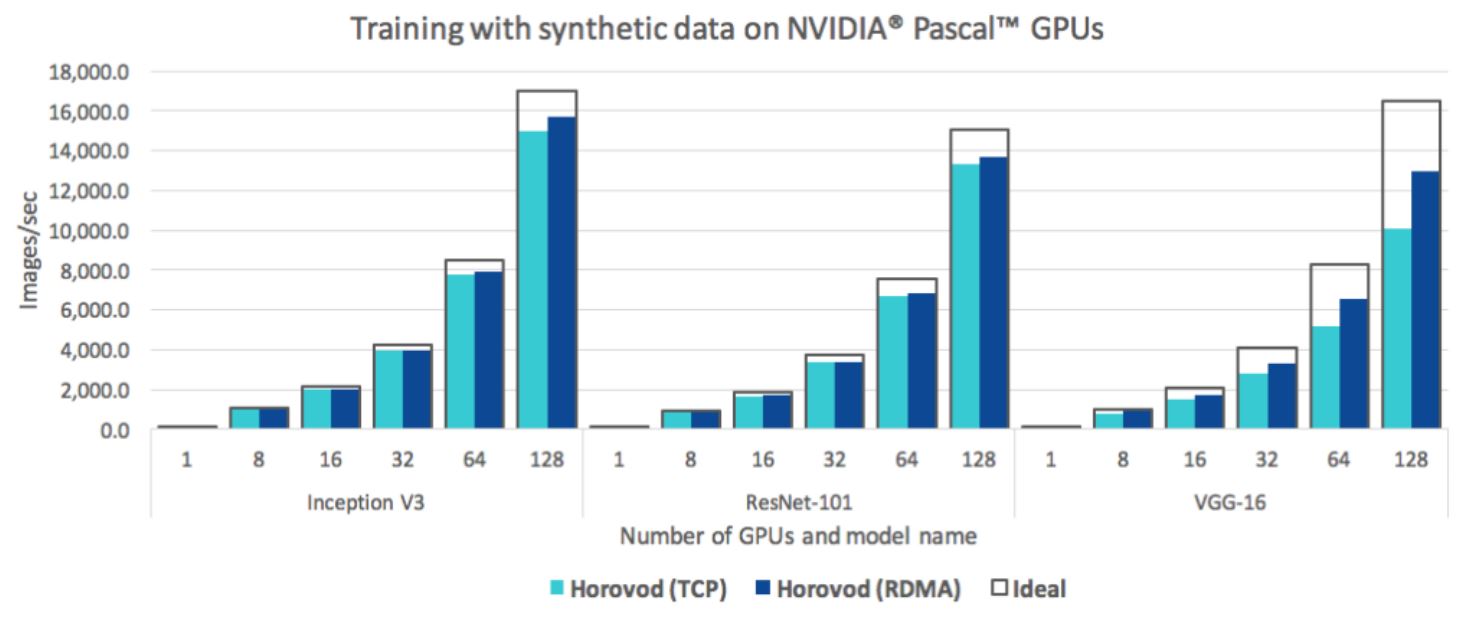
In addition to the performance boost gained from ring-allreduce, Horovod also uses the Tensor Fusion algorithm to optimize tensor computation. Tensor Fusion works by going through each tensor that is ready for reduction and merges tensors with the same data type into a 64 MB buffer. For each buffer that has not been reduced yet, ring reduction is applied and then data is copied from the fused buffer to output tensors. Merging tensors into a buffer helps with models that have a large number of tensors such as ResNet-101. Ring reduction is more optimal for large tensors, but is not as efficient with many small tensors, thus adding many small tensors to a buffer will help alleviate this inefficiency. Therefore, Tensor Fusion is an operation that should be run before ring-allreduce, which can optimize calculations by reducing the number of times allreduce needs to be invoked through its use of a Fusion buffer.
In summary, when working with Tensorflow, it is best to use Horovod to provide distribution as it is easier to make Tensorflow code distributed and also Horovod has more efficient use of hardware resources due to the absence of parameter servers and the use of optimizations like ring-allreduce and tensor fusion. Horovod’s support of CNTK is also in progress.
Conclusion
https://github.com/Azure/BatchAI
https://github.com/Smarker/batchai-benchmark
https://github.com/Smarker/batchai-workshop
https://arxiv.org/pdf/1802.05799.pdf
https://eng.uber.com/horovod/
Featured photograph by Juan Pablo Garcia Galguera