
In Visual Studio 2012 we introduced the ability to create visualizations for native types using natvis files. Visual Studio 2013 contains several improvements that make it easier to author visualizations for classes that internally make use of collections to store items. In this blog post I’ll show an example scenario that we wanted to improve, show you what you have to do in VS2012 to achieve the desired results, and then show you how the natvis authoring gets easier with VS2013 by exploring some of our new enhancements.
Example scenario
Let’s consider the following source code and suppose we are interesting in writing a visualizer for the CNameList class:
#include <vector>
using namespace std;
class CName
{
private:
string m_first;
string m_last;
public:
CName(string first, string last) : m_first(first), m_last(last) {}
void Print()
{
wprintf(L"%s %s\n", (const char*) m_first.c_str(), (const char*) m_last.c_str());
}
};
class CNameList
{
private:
vector m_list;
public:
CNameList() {}
~CNameList()
{
for (int i = 0; i < m_list.size(); i++)
{
delete m_list[i];
}
m_list.clear();
}
void AddName(string first, string last)
{
m_list.push_back(new CName(first, last));
}
};
int _tmain(int argc, _TCHAR* argv[])
{
CNameList presidents;
presidents.AddName("George", "Washington");
presidents.AddName("John", "Adams");
presidents.AddName("Thomas", "Jefferson");
presidents.AddName("Abraham", "Lincoln");
return 0;
}
Our goal is to get ‘presidents’ to display like this:
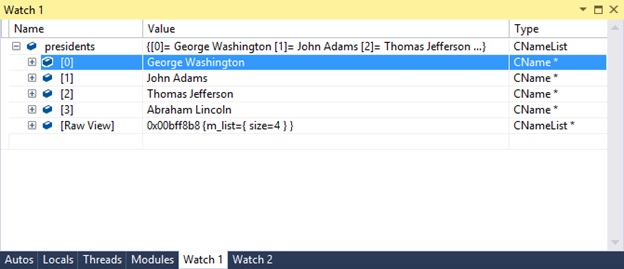
CNameList visualizer for Visual Studio 2012
In Visual Studio 2012, it can be tricky for some to author the visualization for the CNameList class. The most obvious natvis authoring:
<?xml version="1.0" encoding="utf-8"?>
<AutoVisualizer xmlns="http://schemas.microsoft.com/vstudio/debugger/natvis/2010">
<Type Name="CNameList">
<Expand>
<ExpandedItem>m_list</ExpandedItem>
</Expand>
</Type>
<Type Name="CName">
<DisplayString>{m_first} {m_last}</DisplayString>
<Expand>
<Item Name="First">m_first</Item>
<Item Name="Last">m_last</Item>
</Expand>
</Type>
</AutoVisualizer>
Would display like this:

While the first and last names of the presidents are there, the view is a lot more cluttered than we may like. Since we want to visualize the content of the CNameList object, rather than its implementation details, we may not care about the size or capacity of the internal vector, nor about the memory address of each CName object in the list, or the quotes around the first and last names to indicate that they are stored as separate strings. With Visual Studio 2012, removing this clutter is possible, but it is rather cumbersome, and requires the visualization for CName and CNameList to be coupled with implementation details of the STL. For example, in VS2012 we could get rid of the size and capacity of the vector, as well as the memory addresses of the CName objects, by replacing the visualizer for CNameList with this:
<Type Name="CNameList">
<Expand>
<IndexListItems>
<Size>m_list._Mylast - m_list._Myfirst</Size>
<ValueNode>*m_list._Myfirst[$i]</ValueNode>
</IndexListItems>
</Expand>
</Type>
And we could get rid of the quotes around the first and last names by replacing the CName visualizer with this, which uses the “,sb” format specifier to remove the quotes around the characters in the string:
<Type Name="CName">
<DisplayString Condition="m_first._Myres < m_first._BUF_SIZE && m_last._Myres < m_last._BUF_SIZE">{m_first._Bx._Buf,sb} {m_last._Bx._Buf,sb}</DisplayString>
<DisplayString Condition="m_first._Myres >= m_first._BUF_SIZE && m_last._Myres < m_last._BUF_SIZE">{m_first._Bx._Ptr,sb} {m_last._Bx._Buf,sb}</DisplayString>
<DisplayString Condition="m_first._Myres < m_first._BUF_SIZE && m_last._Myres >= m_last._BUF_SIZE">{m_first._Bx._Buf,sb} {m_last._Bx._Ptr,sb}</DisplayString>
<DisplayString Condition="m_first._Myres >= m_first._BUF_SIZE && m_last._Myres >= m_last._BUF_SIZE">{m_first._Bx._Ptr,sb} {m_last._Bx._Ptr,sb}</DisplayString>
<Expand>
<Item Condition="m_first._Myres < m_first._BUF_SIZE" Name="First">m_first._Bx._Buf,sb</Item>
<Item Condition="m_first._Myres >= m_first._BUF_SIZE" Name="First">m_first._Bx._Ptr,sb</Item>
<Item Condition="m_last._Myres < m_last._BUF_SIZE" Name="Last">m_last._Bx._Buf,sb</Item>
<Item Condition="m_last._Myres >= m_last._BUF_SIZE" Name="Last">m_last._Bx._Ptr,sb</Item>
</Expand>
</Type>
While these visualizations certainly work in the sense that they yield the desired clutter-free output in the watch window, they require more work to write and maintain. First, the visualizers for both CNameList and CName now take dependencies on private members of classes in the STL. As implementation details the STL are subject to change, these visualizers are at risk of not working in a future version of Visual Studio if the STL implementation changes something that these entries depend on. Furthermore, if CNameList is distributed as a header file that could potentially be included from any version Visual Studio, you might need to include a separate natvis entry for CName, for each implementation of the STL, then have to update all of them, any time in the future that the implementation of CName changes.
Furthermore, when the visualizer for the internal class has conditionals in it, the conditionals end up multiplying in ways that make the visualizer a mess. For instance, the built-in visualizer for std::basic_string has two possible display string cases:
<Type Name="std::basic_string<char,*>">
<DisplayString Condition="_Myres < _BUF_SIZE">{_Bx._Buf,s}</DisplayString>
<DisplayString Condition="_Myres >= _BUF_SIZE">{_Bx._Ptr,s}</DisplayString>
<StringView Condition="_Myres < _BUF_SIZE">_Bx._Buf,s</StringView>
<StringView Condition="_Myres >= _BUF_SIZE">_Bx._Ptr,s</StringView>
<Expand>
<Item Name="[size]">_Mysize</Item>
<Item Name="[capacity]">_Myres</Item>
<ArrayItems>
<Size>_Mysize</Size>
<ValuePointer Condition="_Myres < _BUF_SIZE">_Bx._Buf</ValuePointer>
<ValuePointer Condition="_Myres >= _BUF_SIZE">_Bx._Ptr</ValuePointer>
</ArrayItems>
</Expand>
</Type>
However, because CName contains both a first name and a last name, there are now four cases, instead of two, based on whether the first and last names are contained in _Bx._Buf or _Bx._Ptr. If we were to enhance CName to store middle names as well, now the visualizer would be up to eight cases, as the number of cases doubles for each new name you want to display. So we wanted to offer a cleaner way.
CNameList Visualizer for Visual Studio 2013
In Visual Studio 2013, you can achieve an uncluttered view of CNameList in the watch window by writing your visualizer like this:
<?xml version="1.0" encoding="utf-8"?>
<AutoVisualizer xmlns="http://schemas.microsoft.com/vstudio/debugger/natvis/2010">
<Type Name="CNameList">
<Expand>
<ExpandedItem>m_list,view(simple)na</ExpandedItem>
</Expand>
</Type>
<Type Name="CName">
<DisplayString>{m_first,sb} {m_last,sb}</DisplayString>
<Expand>
<Item Name="First">m_first,sb</Item>
<Item Name="Last">m_last,sb</Item>
</Expand>
</Type>
</AutoVisualizer>
This view visualization works by taking advantage of three new natvis features in Visual Studio 2013: multiple views of an object, a format specifier to suppress memory addresses of pointers, and the ability of format specifiers to propagate across multiple natvis entries. Let’s examine all three next.
Multiple Object Views
In Visual Studio 2012, a <Type> entry can only describe one way to view an object. For example, because the default view of a vector includes child nodes for the size and capacity, every natvis entry that wants to show a vector must either also include child nodes for the size and capacity or inline the vector visualizer into the visualizer of the type that uses the vector.
In Visual Studio 2013, each type still has only one default view, and it is now possible for a natvis entry to define additional views that can be accessed through an appropriate format specifier. For example, the Visual Studio 2013 visualization of std::vector does so like this:
<Type Name="std::vector<*>">
<DisplayString>{{ size={_Mylast - _Myfirst} }}</DisplayString>
<Expand>
<Item Name="[size]" ExcludeView="simple">_Mylast - _Myfirst</Item>
<Item Name="[capacity]" ExcludeView="simple">_Myend - _Myfirst</Item>
<ArrayItems>
<Size>_Mylast - _Myfirst</Size>
<ValuePointer>_Myfirst</ValuePointer>
</ArrayItems>
</Expand>
</Type>
The <DisplayString> and the <ArrayItems> elements are used always, while the “[size]” and “[capacity]” items are excluded from a view that has a name of “simple”. Normally, objects are displayed using the default view, which will show all the elements. However, the “,view” format specifier can be used to specify an alternate view, as shown this example of a simple vector of integers. Note that “vec,view(xxx)” behaves exactly the same as the default view because the natvis entry for vector does not contain any special behavior for a view of “xxx”.

If you want a natvis element to be added to, rather than removed from a particular view, you can use the “IncludeView” attribute, instead of “ExcludeView”. You may also specify a semi-colon delimited list of views in “IncludeView” and “ExcludeView” attributes, if you want the attribute to apply to a set of views, rather than just one. For example, this visualization will show the display text of “Alternate view” using either “,view(alternate)” or “,view(alternate2)”, and “Default View” in other cases.
<Type Name="MyClass">
<DisplayString IncludeView="alternate; alternate2">Alternate view </DisplayString>
<DisplayString>Default View</DisplayString>
</Type>
So, going back to our example, our CNameList visualizer takes advantage of the “simple” view defined in the “vector” visualizer to eliminate the clutter of the size and capacity nodes:
<Type Name="CNameList">
<Expand>
<ExpandedItem>m_list,view(simple)na</ExpandedItem>
</Expand>
</Type>
Skipping Memory Addresses
Visual Studio 2013 adds a new format specifier, “,na”. When applied to a pointer, the “,na” format specifier causes the debugger to omit the memory address pointed to, while still retaining information about the object. For example:

In our CNameList example, we use the “,na” format specifier to hide the memory addresses of the CName objects, which are unimportant. Without the “,na” format specifier, hiding the memory addresses would have required copy-pasting and modifying the visualizer for std::vector to make it dereference the elements inside of the vector, like this:
<Type Name="CNameList">
<Expand>
<IndexListItems>
<Size>m_list._Mylast - m_list._Myfirst</Size>
<ValueNode>*m_list._Myfirst[$i]</ValueNode>
</IndexListItems>
</Expand>
</Type>
In our CNameList example, we use the “,na” format specifier to hide the memory addresses of the CName objects, which are unimportant. Without the “,na” format specifier, hiding the memory addresses would have required copy-pasting and modifying the visualizer for std::vector to make it dereference the elements inside of the vector, as illustrated here.
It should also be noted that the “,na” format specifier is not quite the same as the dereferencing operator “*”. Even though the “,na” format specifier will omit the memory address of the data being pointed to, any available symbolic information about that address will still be displayed. For example, in the function case, “*wmain” would be a syntax error, but “wmain,na” shows the module and signature of the “wmain” function, omitting the memory address. Similarly, “&myGlobal,na” still shows you that the pointer is pointing to the symbols “int myGlobal”. The “,na” format specifier can also be used on memory addresses in the middle of a function, as illustrated in the “(void*)eip,na” example. This can make the “,na” format specifier quite attractive for visualizing stack traces that have been logged inside of objects, for debugging purposes.
Propagating Format Specifiers
Even though the “,sb” format specifier already exists in Visual Studio 2012, authoring the CName visualizer like this does not work in VS2012:
<Type Name="CName">
<DisplayString>{m_first,sb} {m_last,sb}</DisplayString>
<Expand>
<Item Name="First">m_first,sb</Item>
<Item Name="Last">m_last,sb</Item>
</Expand>
</Type>
The reason is that “m_first” is not actually a char*, but rather an std::basic_string. Because of this, Visual Studio 2012 actually obtains the format specifier for the underlying char* from the std::basic_string visualizer, not the CName visualizer. While the use of “m_first,sb” is still legal syntax, under Visual Studio 2012, the “,sb” in CName’s visualizer actually gets completely ignored.
In the meantime, because the visualizer for std::basic_string is designed to work for the common case, the std::basic_string uses “,s”, not “,sb”, causing the quotes to be included. Hence, while your intention was to get stripped out, they are actually still there . In Visual Studio 2012, the only workaround without changing std::basic_string, and potentially messing up other visualizations, not related to CName, is to inline the contents of std::basic_string into CName’s visualizer, so the string being used with “,sb” is actually a direct char*, rather than an std::basic_string.
In Visual Studio 2013, format specifiers used on visualized objects get merged with format specifiers of the object’s visualizer itself, rather than getting thrown out. In other words, in Visual Studio 2013, the “b” in “m_first,sb” propagates to the strings shown in the std::basic_string visualizer, allowing the quotes to be nicely and easily stripped out, without needing to modify or inline the visualizer for std::basic_string.
Another example of propagation of format specifiers is our new visualizer for CNameList. Even if the “,na” format specifier did exist in Visual Studio 2012, without the propagation of format specifiers, “m_list,na” would still not work, as the “,na” would simply be ignored due to std::vector’s visualizer not using “,na”. In Visual Studio 2013, the “,na” format specifier automatically propagates to the elements of the vector and things just work.
Yet another good example of propagation of format specifiers is displaying the elements of an integer collection in hexadecimal. The “,x” format specifier to display an integer in hex is already present in Visual Studio 2012, but only when applied directly to an integer value. When applied to a vector object, Visual Studio 2012 will simply ignore it, like this:
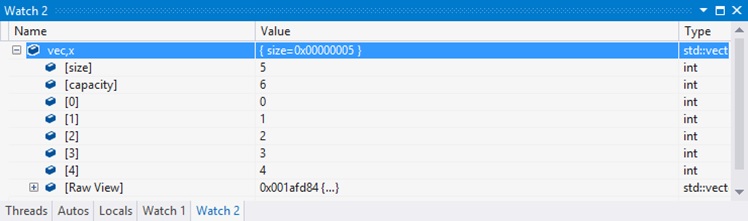
In Visual Studio 2012, showing the vector elements in hex would have required either modifying the visualizer for std::vector so that every vector would have its elements in hex, or toggling the global “hexadecimal display” option, which would cause every watch item to be formatted in hex, not just that one vector.
In Visual Studio 2013, “,x” simply propagates down to the children of the vector automatically, like this:
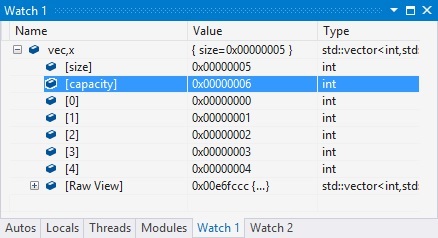
Other Visualization improvements
While the above features are all that is necessary to make our CNameList example work, there are a few other natvis-related improvements that have been asked for and are worth mentioning as well:
Using the final implementation name of a class inside a display string:
In Visual Studio 2013, a natvis entry for a base class may make use of the name of the object’s implementation class the $(Type) macro inside of a element. For example, if we have this source code:
class Room
{
private:
int m_squareFeet;
public:
Room() : m_squareFeet(100) {}
virtual void Print() = 0;
};
class Bedroom : public Room
{
public:
virtual void Print() { printf("Bedroom"); }
};
class LivingRoom : public Room
{
public:
virtual void Print() { printf("Living room"); }
};
class DiningRoom : public Room
{
public:
virtual void Print() { printf("Dining room"); }
};
int _tmain(int argc, _TCHAR* argv[])
{
Bedroom br;
LivingRoom lr;
DiningRoom dr;
br.Print();
lr.Print();
dr.Print();
}
We can write one visualizer for class “Room” like this:
<?xml version="1.0" encoding="utf-8"?>
<AutoVisualizer xmlns="http://schemas.microsoft.com/vstudio/debugger/natvis/2010">
<Type Name="Room">
<DisplayString>{m_squareFeet}-square foot $(Type)</DisplayString>
</Type>
</AutoVisualizer>
that will display which type of room we have, like this:
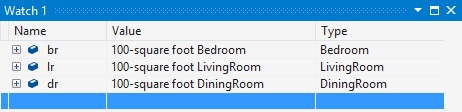
In Visual Studio 2012, achieving this display would have required creating a separate <Type> element for each type of room.
Note that the use of $(Type) is case-sensitive. $(TYPE) will not work. Also, the use of $(Type) requires the base class to contain at least one virtual function because, without the existence of a vtable, the debugger has no way to know what the object’s implementation class actually is.
Support for Circular Linked Lists
In Visual studio 2013, the <LinkedListItems> element adds support for circular lists that point back to the head of the list to indicate termination. For example, with the following source code:
class CircularList
{
private:
struct Node
{
int m_value;
Node* m_pNext;
};
Node* m_pFirst;
Node* GetTail()
{
if (!m_pFirst)
return NULL;
Node* pNode = m_pFirst;
while (pNode->m_pNext != m_pFirst)
pNode = pNode->m_pNext;
return pNode;
}
public:
CircularList() : m_pFirst(NULL) {}
~CircularList()
{
Node* pNode = m_pFirst;
while (pNode != m_pFirst)
{
Node* pNext = pNode->m_pNext;
delete pNode;
pNode = pNext;
}
}
void AddTail(int i)
{
Node* pNewNode = new Node();
if (m_pFirst)
GetTail()->m_pNext = pNewNode;
else
m_pFirst = pNewNode;
pNewNode->m_value = i;
pNewNode->m_pNext = m_pFirst;
}
};
int _tmain(int argc, _TCHAR* argv[])
{
CircularList list;
list.AddTail(1);
list.AddTail(2);
list.AddTail(3);
return 0;
}
We can display the value of ‘list’ with a simple element, like this:
<?xml version="1.0" encoding="utf-8"?>
<AutoVisualizer xmlns="http://schemas.microsoft.com/vstudio/debugger/natvis/2010">
<Type Name="CircularList">
<Expand>
<LinkedListItems>
<HeadPointer>m_pFirst</HeadPointer>
<NextPointer>m_pNext</NextPointer>
<ValueNode>m_value</ValueNode>
</LinkedListItems>
</Expand>
</Type>
</AutoVisualizer>
In Visual Studio 2013, the output is this:

In Visual Studio 2012, the list would be assumed to go on forever, since the “next” pointer of a list node is never NULL, thereby producing output like this:
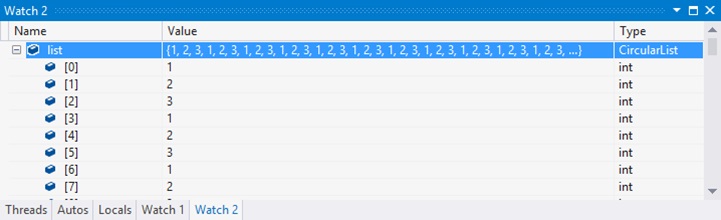
Circular list support in Visual Studio 2013 only applies when an element’s “next” pointer points directly back to the head of the list. If a “next” pointer points back to a prior node in the list, that is not at the head, Visual Studio 2013 will still treat the list as continuing forever, just as Visual Studio 2012 does.
Because the “next” pointer expression does have access to fields in the underlying list object, the is no reasonable workaround for Visual Studio 2012.
In Closing
Visual Studio 2013 seeks to address the most common cases in which deficiencies in the natvis framework require compromises in the quality of the visualized view of an object and/or the maintainability of the natvis entries behind it. For feedback on this or any other diagnostics-related features please visit our MSDN forum and I also look forward to your comments below.
0 comments