
For Visual Studio 2013 we have continued to improve the analysis performed by the Visual C++ compiler so it can produce code that runs faster than before. In this blog we highlight some of the many improvements that Visual Studio 2013 has in store for you. This blog is intended to provide you an overview on all the goodies we have added recently which will help make your code run faster. We have bucketed these improvements into a couple primary scenarios enlisted below, but before we get started let us take a recap of existing performance.
Recap of free performance
The Visual C++ Compiler offers many optimization flags (/O flags, except /Od). The /O optimization flags perform optimizations on a per module (compliand) basis which means no inter-procedural optimizations are performed when making use of /O flags. This is primarily done to provide users a balance between performance/code-size and compilation time.
Visual Studio 2013 out of the box ships with Whole Program Optimization (WPO) enabled (/GL or /LTCG build flags) for ‘release’ build configurations. Whole program optimization allows the compiler to perform optimizations with information on all modules in the program. This in particular among other optimizations allows for inter-procedural inlining and optimize the use of registers across function boundaries. WPO does come at a cost of increased build times but provides the maximum performance for the application.

Figure 1: Compilation Unit and Whole Program Optimizations (/O2 and /GL)
As a part of this scenario all the user needs to do is re-compile their application with Visual Studio 2013 to benefit from all the smarts mentioned below. So let us get started!
Permutation of perfect loop nests
Memory (Working set, caching and spatial/temporal locality of accesses) *really* matters when it comes application performance. If you have a nested loop and you are processing large arrays which are too big to fit in the processor’s L3 cache, then the speed at which your code runs is mostly dominated by the time it takes to fetch from memory, rather than the actual calculations performed inside the loop body and sometimes, by changing the order of the nested loops, we can make it speed up dramatically. To know more about this optimization please refer to Eric Brumer’s presentation at //build, Native Code Performance and Memory: The Elephant in the CPU.
Auto-vectorization++
The Visual C++ 2013 compiler continues to evolve the patterns of code that we can vectorize, as a result the compiler now vectorizes loops containing min/max and other operations. The compiler is also now able to successfully ‘reduce’ (taking the sum or product, for example) into an array element, rather than a simple variable. The compiler also pays special attention to where the code says “restrict” and this helps elide runtime checks previously emitted to check against potential pointer overlap inhibiting vectorization. Lastly, we have also introduced a technique we call “statement-level” vectorization that we’ll take a deeper look at in a moment. To provide you a little more understanding on how all these improvements come into play, let us take a look at a couple of examples:
Example 1: Vectorize C++ Standard Template Library code patterns
We have spent effort to make auto-vectorization be ‘friendly’ to the kinds of code pattern the C++ Standard Template Library uses in its implementation. In describing auto-vectorization for the last release, our examples all showed counted for loops, iterating thru arrays. But look at example 1 above – a while loop rather than a counted for loop – no eyes, or jays there! And no square brackets to denote array indexing – just a bunch of pointers! And yet, we vectorize this successfully for you.
Example 2: Statement level vectorization

If you take a look at this example, there is no loop here but the compiler recognizes that we are doing identical arithmetic (taking the reciprocal on adjacent fields within a struct) and it vectorizes the code, by making use of processor’s vector registers and instruction.
Range Propagation
Another optimization we have added is called ‘Range Propagation’. With this optimization in place the compiler now keeps track of the range of values that a given variable may take on, as a function executes. This allows the compiler to sometimes omit entire arms of a case statement, or nested if-then-else block, thereby removing redundant tests.
/Gw Compiler Switch
A compiler can optimize away data or a function if a compiler can prove the data or function will never be referenced. However, for non WPO builds the compiler’s visibility is only limited to a single module (.obj) inhibiting it from doing such an optimization. The Linker however has a good view of all the modules that will be linked together, so linker is in a good position to optimize away unused global data and unreferenced functions. The linker though manipulates on a section level, so if the unreferenced data/functions are mixed with other data or functions in a section, linker won’t be able to extract it out and remove it. In order to equip the linker to remove unused global data and functions, we need to put each global data or function in a separate section, and we call these small sections “COMDATs“.
Today using the (/Gy) compiler switch instructs the compiler to only package individual functions in the form of packaged functions or COMDATs, each with its own section header information. This enables function-level linkage and enables linker optimizations ICF (folding together identical COMDATs) and REF (eliminating unreferenced COMDATs). In VS2013 (download here), we have introduced a new compiler switch (/Gw) which extends these benefits (i.e. linker optimizations) for data as well. It is *important* to note that this optimization also provides benefits for WPO/LTCG builds. For more information and a deep dive on the ‘/Gw’ compiler switch, please take a look at one of our earlier blog posts.
Vector Calling Convention (/Gv Compiler Switch)
For Visual C++ 2013, we have introduced a new calling convention called ‘Vector Calling Convention’ for x86/x64 platforms. As the name suggests Vector Calling Convention focuses on utilizing vector registers when passing vector type arguments. Use __vectorcall to speed functions that pass several floating-point or SIMD vector arguments and perform operations that take advantage of the arguments loaded in registers. Vector calling convention not only saves on the number of instructions emitted to do the same when compared to existing calling conventions (for eg., fastcall on x64) but also saves on stack allocation used for creating transient temporary buffers required for passing vector arguments. One quick way for validating the performance gain by using Vector Calling Convention for vector code without changing the source code is by using the /Gv compiler switch. However the ideal way, remains to decorate the function definition/declaration with the __vectorcall keyword as shown in the example below:

Figure 5: Vector Calling Convention example
To know more about ‘Vector Calling Convention’ please take a look at one of our earlier blog posts and documentation available on MSDN.
Profile, Compile and Smile a little bit extra
So far we have talked about the new optimizations that we have added for Visual C++ 2013 and in order to take advantage of them all you need to do is recompile your application but if you care about some added performance then this section is for you. To get the maximum performance/code-size for your application make use of Profile Guided Optimization (PGO) (figure 6.). Again, this added performance does come at the cost of additional build time and requires Whole Program Optimization enabled for your application.
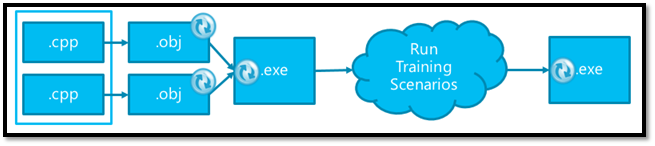
Figure 6: Profile Guided Optimization
PGO is a runtime compiler optimization which leverages profile data collected from running important or performance centric user scenarios to build an optimized version of the application. PGO optimizations have some significant advantage over traditional static optimizations as they are based upon how the application is likely to perform in a production environment which allow the optimizer to optimize for speed for hotter code paths (common user scenarios) and optimize for size for colder code paths (not so common user scenarios) resulting in generating faster and smaller code for the application attributing to significant performance gains. For more information about PGO please take a look at some of the earlier blog posts.
In Visual C++ 2013, we have continued to improve both PGO’s ability to do better function and data layout, and as a result the generated PGO code runs faster. In addition to this we have improved the optimizations performed for code segments that PGO determines cold or scenario dead. As a result of this the risk of hurting performance for cold or untrained code segments is further diminished.
A consistent pain point for traditional PGO users has been their inability to validate the training phase of carrying out PGO, given performance gains achieved with PGO are directly proportional to how well the application is trained this becomes an extremely important feature that has been missing in previous Visual C++ releases. Starting with Visual Studio 2013 if a user creates a sample profile for a PGO-optimized build extra columns light up in the ‘call tree’ which specify whether a particular function was PGO’ized and in addition to that, whether a particular application was optimized for size or speed. PGO compiles functions which are considered to be scenario hot for speed and the rest are compiled for size. Figure 7. Below enlists the extra PGO diagnostic information that lights up in a vspx profile. To learn more about how to enable this scenario please take a look at this blog which was published earlier.
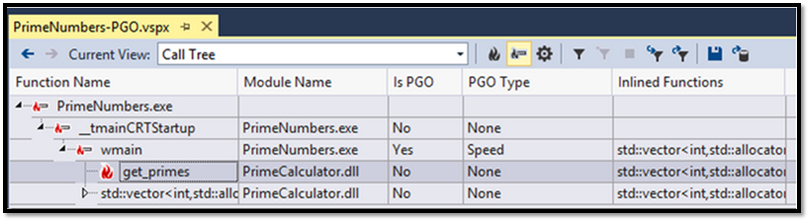
Figure 7: Profile Guided Optimization diagnostic information in VSPX profile
Lastly, on the subject of Profile Guided Optimization, an out of the box prototype plugin has also been launched recently and is now available at VSGallery for download (download here). The plugin installs and integrates into the ‘Performance and Diagnostics’ hub. The tool aims at improving the experience of carrying out PGO for native applications in Visual Studio in the following ways:
- Aims at providing a guided experience through the various phases of the PGO process (Instrument, Train and Optimize)
- In addition to this, the PGO tool will also provide functionality currently only exposed when using PGO from the command line. This includes being able to train disjoint training sets and making use of PGO utilities such as ‘pgomgr‘ to view and analyze the quality of training performed for the training phase of PGO.
- The tool introduces the ability to perform PGO for Windows Store applications targeting x86 and x64 applications.
Following is a snapshot from the Profile Guided Optimization tool which depicts extra diagnostic information that is emitted to further validate the training phase of Profile Guided Optimization.
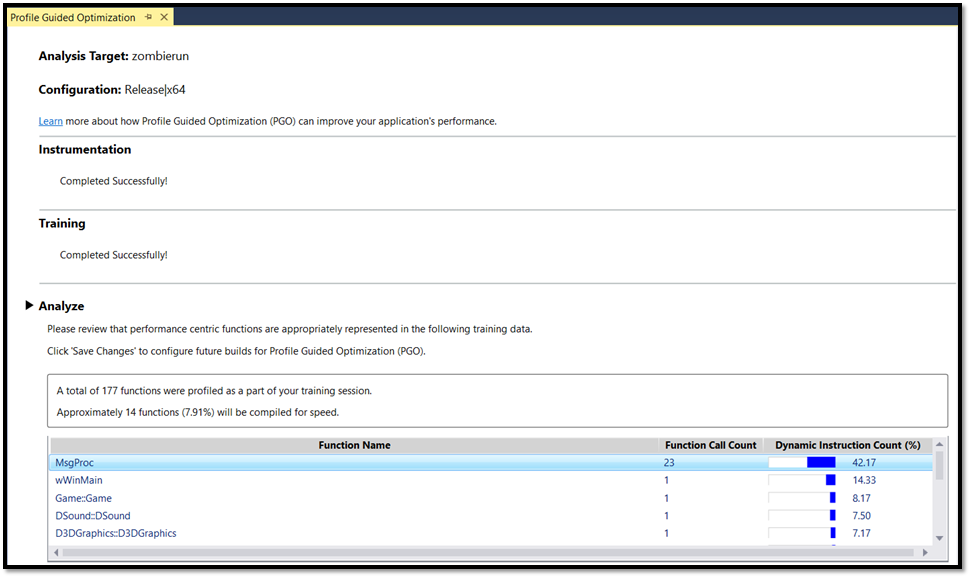
Figure 8: Profile Guided Optimization tool in VSGallery
Wrap up
This blog should provide an overview for some of the goodies we have added in the Visual C++ Compiler which will help your application faster. For most of the work we have done (notably Auto-vectorization++) , all you need to do is rebuild your application and smile, having said that if you are looking for some added performance boosts, give Profile Guided Optimization (PGO) a try! At this point you should have everything you need to get started! Additionally, if you would like us to blog about some other compiler technology or compiler optimization please let us know we are always interested in learning from your feedback.
0 comments