
If you have arrived in the middle of this blog series, you might want instead to begin at the beginning.
This post explains the flow of data within the Visual C++ compiler – starting with our C++ source program, and ending with a corresponding binary program. This post is an easy one – dipping our toes into the shallow end of ocean.
Let’s examine what happens when we compile a single-file program, stored in App.cpp, from the command-line. (If you were to launch the compilation from within Visual Studio, the diagram below would have to include higher layers of software; however, these end up emitting the very commands I’m about to describe).
So let’s imagine we just typed: CL /O2 App.cpp
The CL stands from “Compile and Link”. /O2 tells the compiler to optimize for speed – to generate machine code that runs as fast as possible. This command launches a process to execute the CL.EXE program – a “driver” that calls several pieces of software: when joined together, they process the text in our App.cpp and eventually generate a binary file, called App.exe. When executed, this binary will carry out the operations we specified in our original source file.
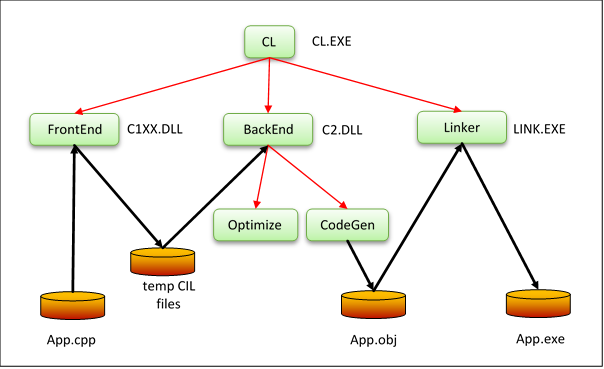
Let’s take a stroll around the diagram above and explain what’s going on.
CL.EXE parses our command-line, and checks that it makes sense. It then calls the C++ “front-end”, located in C1XX.DLL (the “CXX” is meant to suggest “C++”, but dates back to a time when “+” was not a legal character in file names). The FrontEnd is the part of the chain that understands the C++ language. It scans, parses and transforms your App.cpp into an equivalent tree, passed to the next component via 5 temporary files. The “language” represented by these 5 files is called “CIL”, for “C Intermediate Language”. Don’t confuse this with the intermediate code, generated by managed languages such as C#, sometimes called “MSIL” but also, unfortunately, named “CIL” in the ECMA-335 standard.
Next, CL.EXE calls the “back-end”, located in C2.DLL. We call the BackEnd “UTC”, which stands for “Universal Tuple Compiler”, although this name doesn’t show up in any of the binaries included into Visual Studio. The BackEnd starts by converting the information from the FrontEnd into tuples – a binary stream of instructions. If we were to display them, they would look like a kind of high-level assembly language. It’s high-level in the senses that:
- Operations are generic. For example, a BRANCH(LE) instruction versus how it will eventually be translated, into a cmp instruction in x64 machine code
- Operands are symbolic. For example, t66 denoting a temporary variable generated by the compiler, versus eax, the x64 register that will hold its value at runtime
Because we asked the compiler to optimize for speed, via the /O2 switch, the Optimize part of the BackEnd analyses the tuples and transforms them into a form that will execute faster but that is semantically equivalent – that yields the same results as would the original tuples. After this step, the tuples are passed to the CodeGen part of the BackEnd, which decides the final binary code to emit.
The CodeGen module emits App.obj as a file on disk. Finally, the Linker consumes that file, resolves any references to libraries, and produces the final App.exe binary.
In the diagram, black arrows show flow of data – text or binary. Red arrows show flow of control.
(We shall return to this diagram later in the series, when we hit the topic of Whole Program Optimization, specified to the compiler with the /GL switch, and to the Linker with the /LTCG switch. We will see the same set of boxes, but connected in different ways)
In summary:
- The FrontEnd understands C++ source code. Other parts of the chain – BackEnd and Linker – are (mostly) isolated from the details of the original source language. They work upon the tuples, mentioned above, that form a kind of high-level, binary assembly language. The original source program might have been any imperative language, such as FORTRAN or Pascal. The BackEnd really doesn’t care. Well, not much.
- The Optimize part of the BackEnd transforms tuples into more efficient forms that will run faster. Such transformations, we call optimizations. (We should really call them “improvements”, because there may be other improvements that produce even faster-running code – we just aim to get close to that ideal. However, someone coined the term “optimization” a few decades ago, and we’re stuck with it) There are dozens of such optimizations, with names like “constant folding”, “common sub-expression elimination”, “hoisting”, “invariant code motion”, “dead code elimination”, “function inlining”, “auto vectorization”, etc. For the most part, these optimizations are independent of the eventual processor on which the program will execute – they are “machine-independent” optimizations.
- The CodeGen part of the Backend decides how to lay out the runtime stack (used to implement function “activation frames”); how to make best use of the available machine registers; adds details that implement function calling conventions; and transforms the code to make it run even faster, using its detailed knowledge of the target machine. (As one tiny example, if you ever look at assembly code – for example, using the Disassembly window in Visual Studio (Alt+8) whilst debugging code – you may notice instructions like xor eax, eax used to set EAX to zero, in preference to the more obvious move eax,0. Why? Because the XOR form is smaller (2 bytes instead of 5) and executes faster. We might well call this a “micro-optimization”, and wonder whether it’s worth the bother. Recall the proverb: “Look after the pennies and the pounds will look after themselves”). In contrast to the Optimize part, CodeGen is aware of the processor architecture on which the code is going to run. In some cases, it will even change the order in which machine instructions are laid out – a process called “scheduling” – based upon its understanding of the target processor. Oh, I’d better explain that a bit more: CodeGen knows whether it is targeting x86 or x64 or ARM-32; but it’s rare that is can know the specific micro-architecture the code will run on – Nehalem versus Sandy Bridge, for example. (see the /favor:ATOM switch for a case where it knows more detail)
This blog will focus on the Optimize part of the compiler, with scant mention of the other components that make up the chain – FrontEnd, CodeGen or Linker.
This post has introduced lots of jargon. I’m not intending that you make total sense of it all at this point: this post is an overview, sprinkled with ideas that hopefully pique your interest, and ensure you’ll come back next time, where I will start to explain all of that jargon.
Next time, we will look at perhaps the simplest optimization and how it works – the one called “constant folding”.
0 comments