

We are delighted to announce Cassandra 5.0 in public preview for Azure Managed Instance for Apache Cassandra, with vector search capabilities enabled!
Vector Database in Cassandra 5.0
In Cassandra 5.0, the integrated vector database is backed by storage-attached indexes that represent data as vectors in a multi-dimensional space. We use DiskANN, a Microsoft Research-born algorithm that allows for adding new vectors to an index without the need for reindexing, which causes downtime in other vector stores. DiskANN enables fast and accurate similarity-based searches, which can be used to build next-generation AI apps that use Azure OpenAI and other LLMs.
With the integrated vector database, your applications find similar items based on their data characteristics rather than exact matches on a property field. They work by taking the vector representations (lists of numbers) of your data that you have created using an ML model, or an embeddings API such as Azure OpenAI Service Embeddings or Hugging Face on Azure. They then measure the distance between the data vectors and your query vector. The data vectors that are closest to your query vector are the ones that are found to be most similar semantically.
Create a Vector Index
In Cassandra, first create a keyspace and table which has the new vector data type. The second parameter represents the number of dimensions that the vector can hold. In this case, we’ll only add 2 dimensions. However, the dimensionality of your vectors may be different. For example, if you were using OpenAI Embeddings, this would be set to 1536.
CREATE KEYSPACE testWITH replication = {'class': 'NetworkTopologyStrategy', 'dc1': '3'}; use test; CREATE TABLE s (k int PRIMARY KEY, v vector<float, 2>);
Next, create an index on the vector field:
CREATE CUSTOM INDEX ON s(v) USING 'StorageAttachedIndex';Add vectors to your table
To add vectors to your table, you can use the OpenAI Embeddings model to generate embeddings from the data. In this example, we’ll insert a few rows that contain sample embeddings:
INSERT INTO s (k, v) VALUES (1, [1, 1.8]);
INSERT INTO s (k, v) VALUES (1, [1, 2.1]);Perform a vector search
Finally, you can order by the vector column, with an Approximate Nearest Neighbour (ANN) search:
SELECT k, v FROM s WHERE k = 1 ORDER BY v ANN OF [2, 2] LIMIT 4 ALLOW FILTERING;
Generative AI Apps
Lets put this all together in an app that uses vector search in Azure Managed Instance for Apache Cassandra! To get you started, we’ve created a Java-based ChatGPT-like sample app that integrates with Cassandra 5.0 using vector search. The sample allows you to load a file containing your own private contextual data, and uses Azure OpenAI features to create a chat experience.
Included in the sample are:
- Azure OpenAI embedding with vector dimensionality of 1536. Azure OpenAI will automatically create embeddings from the data loaded into the vector store.
- Loading and searching the data from a vector store table in Cassandra 5.0, and performing a similarity search using Approximate Nearest Neighbour (ANN).
- Generating prompts and marshalling chat history (in memory).
- Chat completion using Azure OpenAI.
How it works
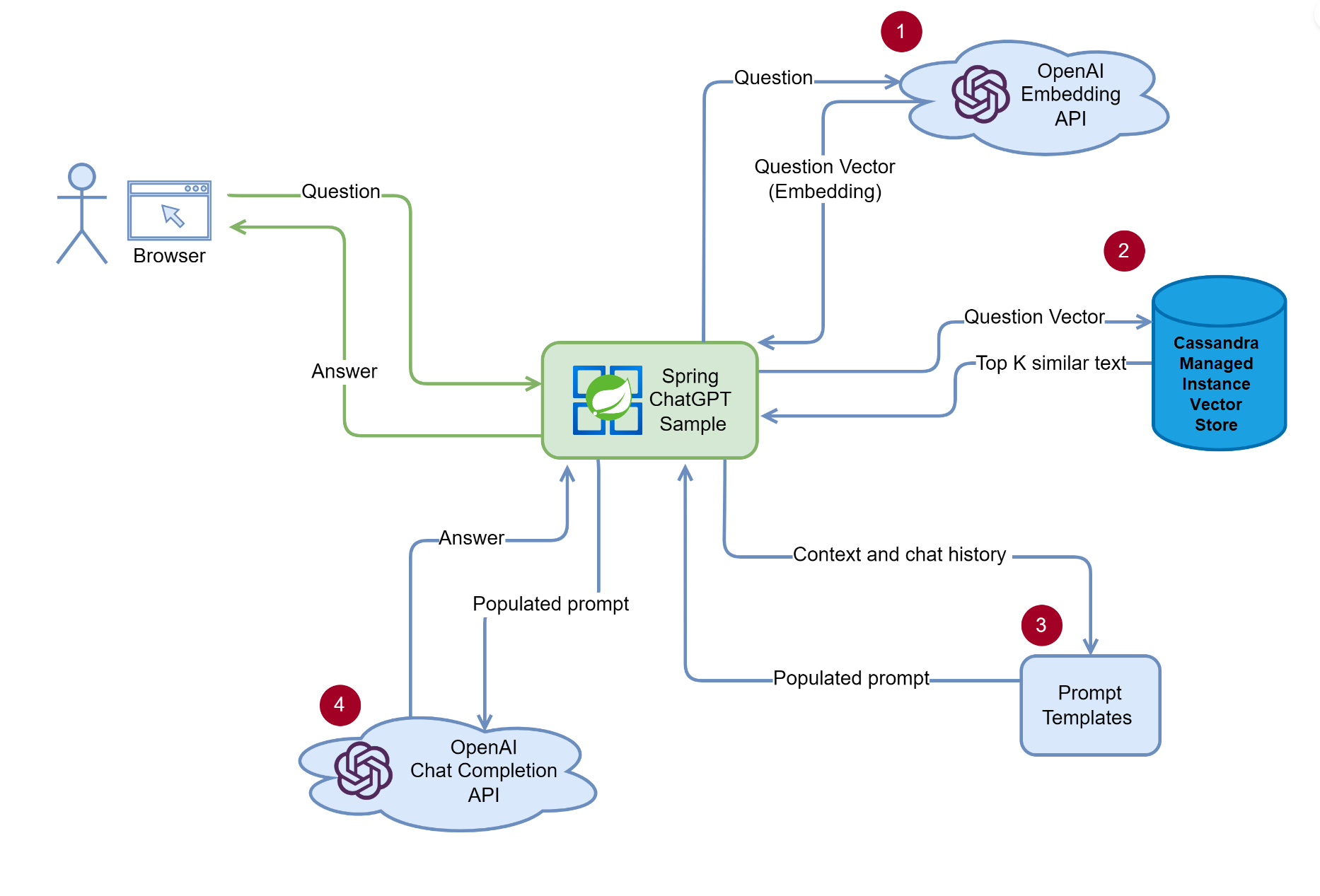
Follow the instructions in the repo to create a generative AI chat experience using vector search in Azure Managed Instance for Apache Cassandra! Once you’ve loaded your data, you can ask the app questions and it will answer based on the private contextual data you provided.
Be careful not to use data that’s too biased! 🙂
Vector search at scale
Apache Cassandra is a massively scalable database with transparent partitioning that stores data across many independent, fault-tolerant nodes in a cluster. Vector searches in Cassandra 5.0 will perform much better if searches are directed towards vectors stored in a single partition.
In the app sample above, by default, each data file you load into the vector store will generate 1 partition of vectors in the table. If you load multiple files, this will result in cross-partition key queries when the app attempts to perform a vector search against your contextual data.
For large-scale apps that leverage vector search, you should design your approach so that, as much as possible, similarity searches are scoped to a single partition or a small number of partitions.

Getting started
- Find Azure Managed Instance for Cassandra in Azure Portal
- Get started easily using Quickstart documentation
- Check out the ChatGPT sample for Azure Managed Instance for Apache Cassandra here!
- Find out about pricing here!
- Read all our technical documentation here
About Azure Cosmos DB
Azure Cosmos DB is a fully managed NoSQL, relational, and vector database service for modern app development with SLA-backed speed and availability, automatic and instant scalability, and support for open-source PostgreSQL, MongoDB, and Apache Cassandra. Try Azure Cosmos DB for free here. To stay in the loop on Azure Cosmos DB updates, follow us on Twitter, YouTube, and LinkedIn.
Don’t use Cosmos unless you like broken SDKs and lying product managers.
https://github.com/Azure/azure-cosmos-dotnet-v3/issues/3697