
The Azure Cosmos DB .NET SDK has recently released Bulk support in version 3.4.0.
What exactly is “Bulk”?
Bulk refers to scenarios that require a high degree of throughput, where you need to dump a big volume of data, and you need to do it with as much throughput as possible.
Are you doing a nightly dump of 2 million records into your Cosmos DB container? That is bulk.
Are you processing a stream of data that comes in batches of 100 thousand items you need to update? That is bulk too.
Are you dynamically generating groups of operations that execute concurrently? Yeah, that is also bulk.
What is NOT “Bulk”?
Bulk is about throughput, not latency. So, if you are working on a latency-sensitive scenario, where point operations need to resolve as quick as possible, then bulk is not the right tool.
How do I enable Bulk in .NET SDK V3?
Enabling bulk is rather easy, when you create the CosmosClient, toggle the AllowBulkExecution flag in the CosmosClientOptions like so:
CosmosClientOptions options = new CosmosClientOptions() { AllowBulkExecution = true };
CosmosClient cosmosClient = new CosmosClient(connectionString, options);
After that, all you need to do is get an instance of a Container where you want to perform the operations, and create a list of Tasks that represent the operations you want to perform based on your input data (I’m removing obtaining the information from the source for simplicity’s sake and because the origin of the data will vary in each case):
Container container = cosmosClient.GetContainer("myDb", "myCollection");
// Assuming your have your data available to be inserted or read
List<Task> concurrentTasks = new List<Task>();
foreach(Item itemToInsert in ReadYourData())
{
concurrentTasks.Add(container.CreateItemAsync(itemToInsert, new PartitionKey(itemToInsert.MyPk)));
}
await Task.WhenAll(concurrentTasks);
Wait, what is happening with those Tasks?
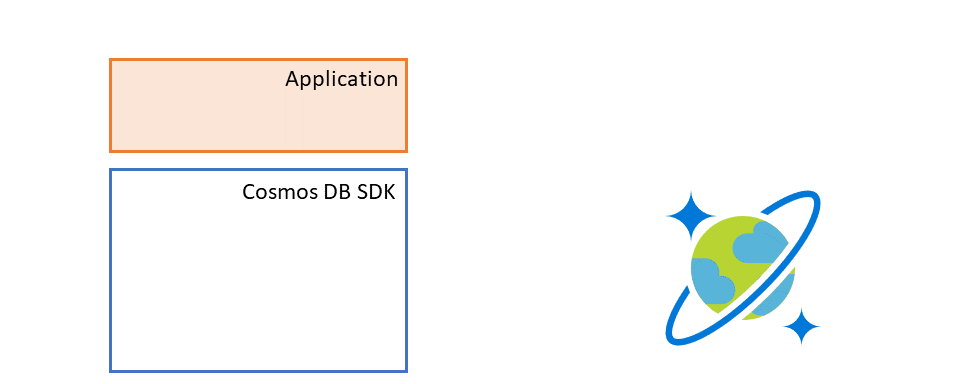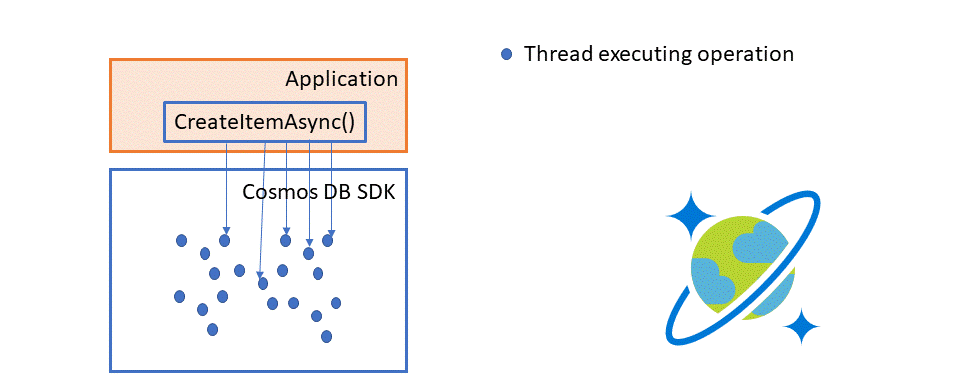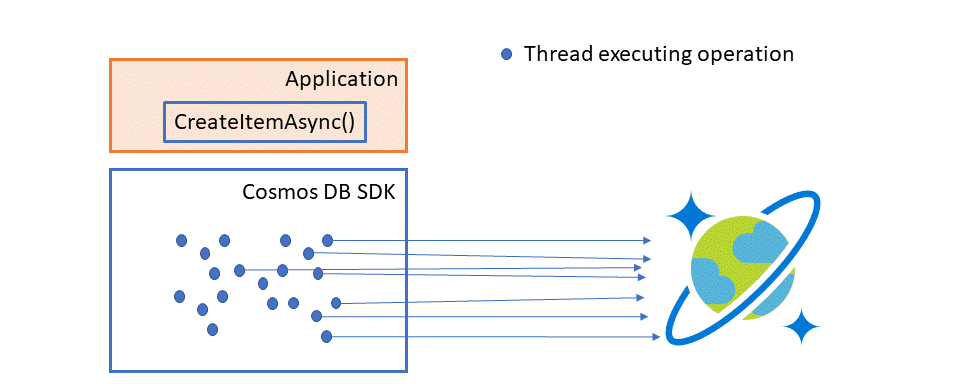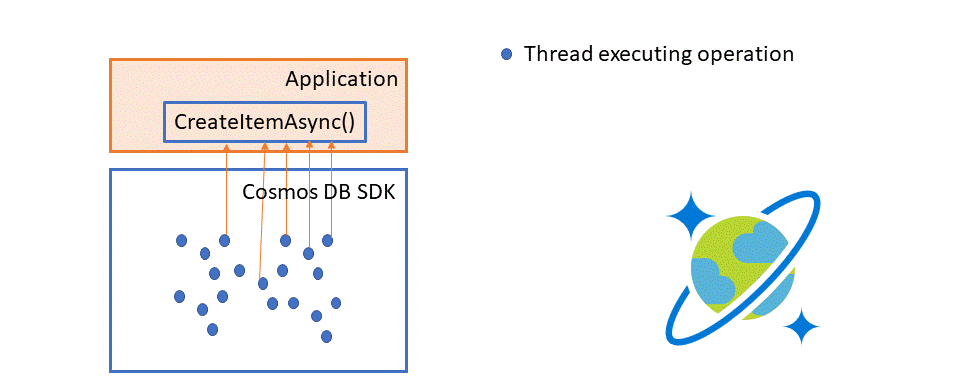
Normally, if you issue a hundred CreateItemAsync operations in parallel, each one will generate a service request and response independently. The illustration below shows what execution looks like when individual threads individually insert new items.
But the magic here happens when the SDK detects that the Bulk mode is enabled.
The SDK will create batches, all the concurrent operations will be grouped by physical partition affinity and distributed across these batches. When a batch fills up, it gets dispatched, and a new batch is created to be filled with more concurrent operations. Each batch will contain many operations, so this greatly reduces the amount of back end requests. There could be many batches being dispatched in parallel targeting different partitions, so the more evenly distributed the operations, the better results.
Now, here comes the best part.
When you (the user) call an operation method (CreateItemAsync in this example), the SDK returns a Task. In a normal, non-bulk CosmosClient, this Task represents the service request for that operation, and completes when the request get the response. But in Bulk, that Task holds the promise of a result, it does not map to a service request. The SDK is grouping and squeezing operations into batches.
When a batch is completed, the SDK then unwraps all the results for all the operations the batch contained and completes the related Tasks with the result. In the illustration below, you can see how batch makes things more efficient and allows you to consume more throughput than you could if done as individual threads.
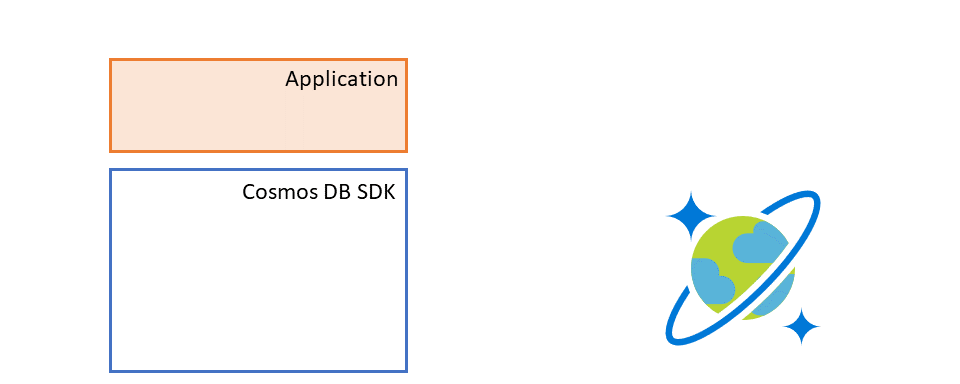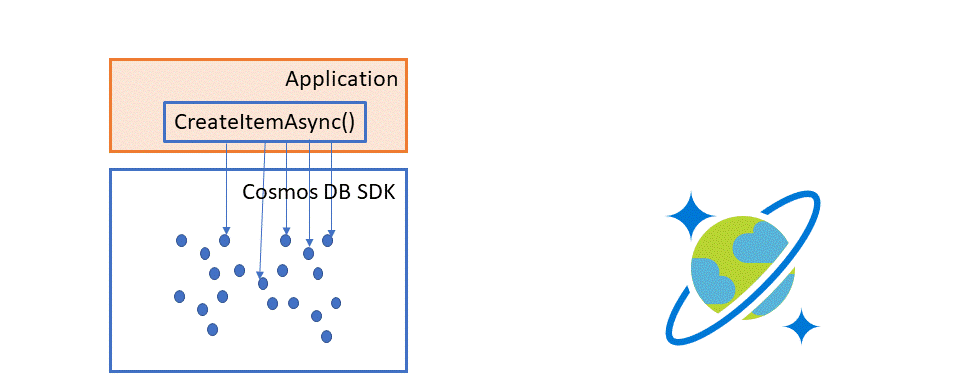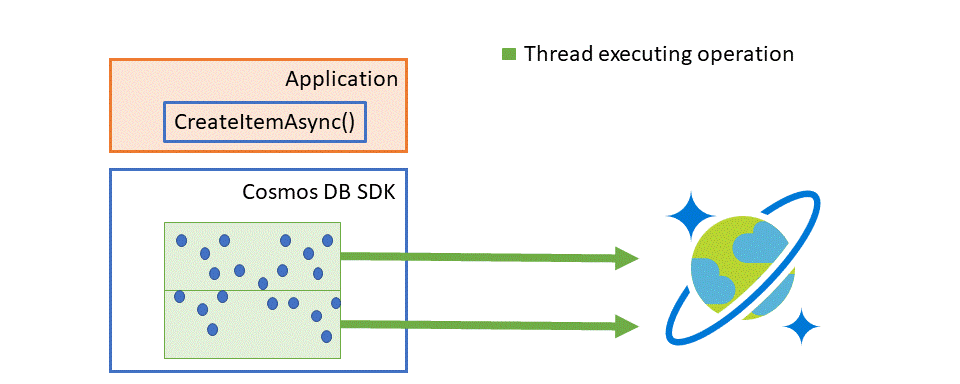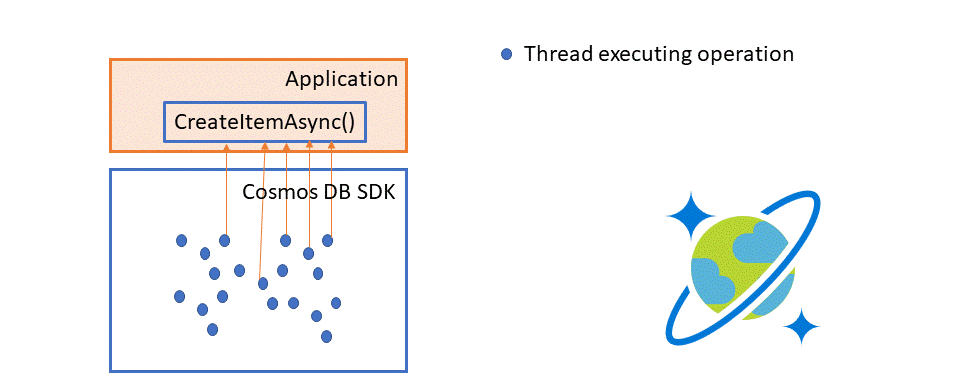
From the user perspective, its transparent.
What are the caveats?
Since Bulk is geared towards obtaining as much throughput as possible, and the volume of data will be higher than executing the operations individually, the provisioned throughput (RU/s) consumed will be higher. Make sure you adjust it based on the volume of operations you want to push.
If your container gets throttled during a Bulk process, it means that now the bottleneck of you getting a higher throughput and pushing even more operations is on the provisioned throughput, raising it will let you push even more operations per second. The .NET SDK will automatically retry when throttling happens, but the overall effect will be that processing the data will be slower.
Another caveat is the size of the documents. The batches that the SDK creates to optimize throughput have a current maximum of 2Mb or 100 operations per batch, the smaller the documents, the greater the optimization that can be achieved (the bigger the documents, the more batches need to be used).
And finally, the amount of operations. As it was mentioned before, the SDK will construct batches and group operations, when the batch is full, it will get dispatched, but if the batch doesn’t fill up, there is a timer that will dispatch it to make sure they complete. This timer currently is 100 milliseconds. So if the batch does not get filled up (for example, you are just sending 50 concurrent operations), then the overall latency might be affected.
In general, to troubleshoot this scenario it is good to:
- Check the metrics on the Azure Portal. A raise in HTTP 429s during the duration of your Bulk operation would indicate throttling.
- Logging the Diagnostics property, would help identify if there are retries happening and understand the dispatch times.
- Collect tracing from the SDK operations as an alternative.
Are there good practices or tips?
Yes! Whenever possible, provide the PartitionKey to your operations, even if you are using the Typed APIs, this avoid the SDK needing to extract it from your data.
If your information comes already as a Stream, use the Stream APIs (for example, CreateItemStreamAsync), this avoids any and all serialization.
In scenarios where your information might already be separated in partition keys, you can choose to create one Worker Task per partition key, and each Worker Task can spawn and coordinate the Tasks that do each item operation, like so:
public async Task Worker(string partitionKey)
{
PartitionKey partitionKey = new PartitionKey(partitionKey);
int maxDegreeOfParallelismPerWorker = 10; // This number is just an example
// Obtain the items from the source, and while there are items to be saved in the container, generate groups of Tasks
while (true)
{
List<Item> itemsToSave = await GetMoreDataForPartitionKeyUpTo(maxDegreeOfParallelismPerWorker);
if (itemsToSave.Count == 0)
{
break; // Nothing more to import
}
List<Task> concurrentTasks = new List<Task>(maxDegreeOfParallelism);
foreach(Item itemToInsert in itemsToSave)
{
concurrentTasks.Add(container.CreateItemAsync(itemToInsert, partitionKey));
}
await Task.WhenAll(concurrentTasks);
}
}
Container container = cosmosClient.GetContainer("myDb", "myCollection");
List<Task> workerTasks = new List<Task>(workerTasks);
foreach(string partitionKey in KnownPartitionKeys)
{
workerTasks.Add(new Worker(partitionKey));
}
await Task.WhenAll(workerTasks);
Next steps
If you want to try out Bulk, you can follow our quickstart. Please share any feedback on our official Github repository.
Hi. Thanks for this blog. It is amazing. I'd like to explain my challenge. We have a service bus consumer. Each message will trigger 5000 document to be inserted in the same partition key. We want to have all of them in the same partition because then we get them from the front end in the fastest possible way.
So, would be enough do this bulk insert for those 5000 documents?
In other hand each message would go to different partition key. Could be interested avoid waiting the bulk for each partition to overlapped those insertion from different message?...
You can absolutely use bulk to do this but you will not be able to fully use your throughput if you try to insert documents into one partition at the same time. You need to ensure you have high enough cardinality of partition key values to spread the load evenly across all the partitions. This is true whether you use bulk or not.
When writing data at very high volumes you want to spread the load across as many partition keys as possible. And in read heavy scenarios you want to be able to answer high volume queries with data on...
How can we control the batch size and is the batch size per partition?
We use azure functions and would like bulk for speeding up times in cosmos triggers when it is necessary to start the change feed from the beginning. Why not just get rid of the 1 second delay and start processing batches immediately, then simply build up batches whilst the previous ones are executing. Could also have a setting to decide whether to immediately dispatch or wait until filled to cater for different scenarios.
In our case, we will likely fill batches when starting the change feed from the...
Hi,
If I understand correctly, you use Change Feed to read changes and would like to use Bulk to write them to another collection? If so: The 1 second delay is just a timer to detect no activity in a half-empty batch, if its removed, then there is no threshold to dispatch the batch other than the size (which is 100 currently).
Keep in mind that, from the post, this Bulk engine works with no context, you are not sending your operations in a package, you are executing concurrent independent threads, they can come from one process, or you could...
Does this essentially replace the Bulk Executor library as well, or are they meant for different use cases? For the Bulk Executor library, it was recommended to only run a single instance at a time (we also personally experienced performance bottlenecks attempting to run multiple instances). Is that restriction removed as well?
Yes, this is the replacement for the separate Bulk Executor library. Definitely no restriction running multiple instances an in fact, when running on a VM or some other compute in Azure, you may find you are maxed out for the amount of throughput you can consume because of limits for networking or cores for the host VM. In those cases, adding more VM’s running Cosmos in Bulk mode will help you better saturate provisioned throughput.
What about inserting bulk amount of data into cosmos db using Durable functions on consumption plan,where throughput is spanned across multiple shared instances.I am afraid it will result in exception whenever Function instances scale out due to heavy and long running workloads
I can’t speak to using Azure Functions as this is better directed at that team regarding how it behaves under certain use cases. Suggest you try this as you described as see if it works for you.
Bulk Mode for Cosmos will always try to saturate your throughput up to the amount provisioned. In some cases, it is necessary to have multiple client instances to do this.
Thanks.