
This is the second in a two-part series in which we walk through the steps for realizing your first Azure Cosmos DB implementation. In this post, we will optimize the queries we created in part 1.
The table below shows the RUs consumed for each query.
| Query | Loops | Items returned | RU consumption |
| 1 | 6 | 5001 | 208 |
| 2 | 1 | 10 | 3 |
| 3 | 6 | 5002 | 191 |
| 4 | 1 | 1 | 3 |
Performance tuning
Now that we have created the first version of our application, our next step is optimizing RU consumption. The first step in this process is to optimize the Indexing policy which is set on the container level. The default Indexing Policy indexes all the property paths of our JSON.
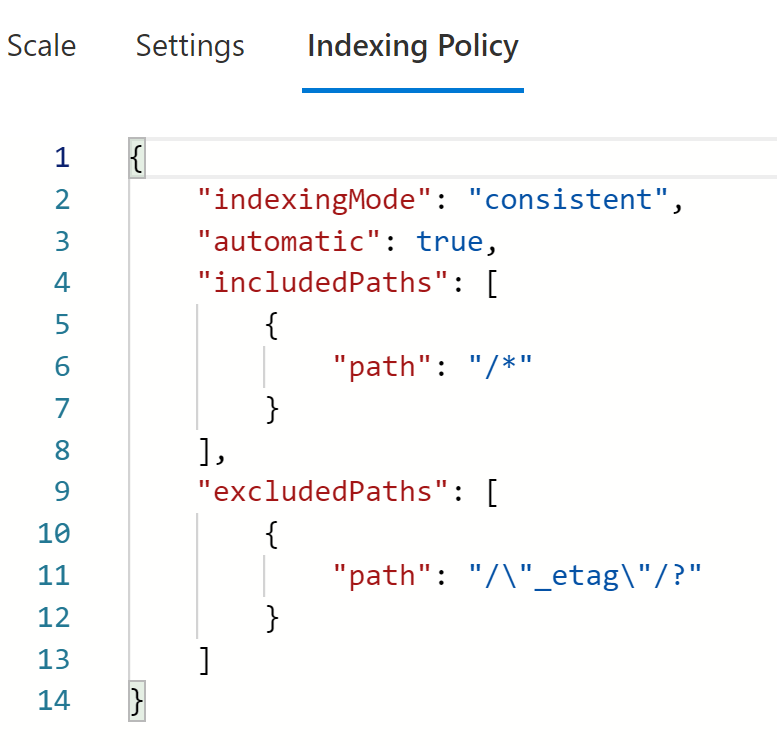
This has a negative impact on write operations since index management also consumes RUs. To optimize the Indexing Policy we need to examine which property paths are used as filters in our read queries. Only these property paths will be included in the policy as you can see below.
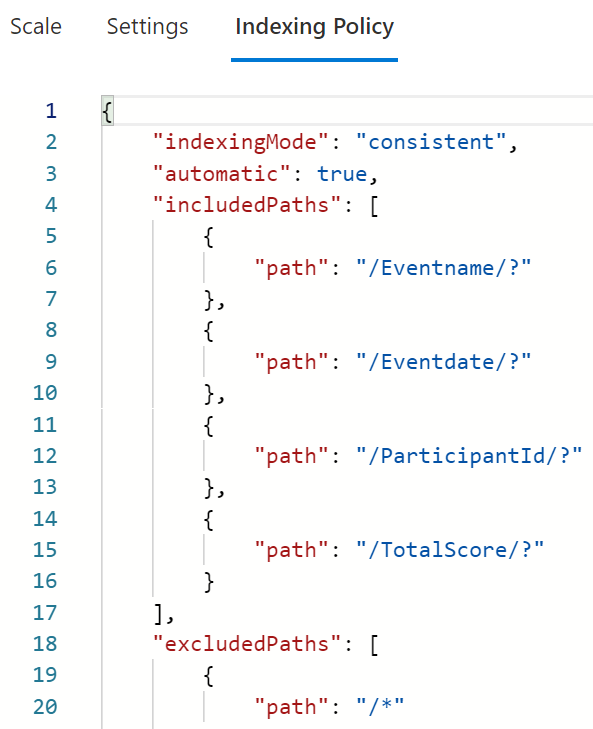
We now repeat the Insert operation which initially consumed 9 RUs. With the optimized Index Policy, this operation now takes 7 RUs – saving 2 RUs per item written to Azure Cosmos DB. This may seem not much, but in scenarios where an application is writing thousands of items every minute, optimizing the Index Policy can have a huge impact. For more information, see Manage indexing policies in Azure Cosmos DB.
Now that we have optimized writing items to Azure Cosmos Dhttps://docs.microsoft.com/azure/cosmos-db/how-to-manage-indexing-policyB we will now take a look at optimizing our read queries.
Optimizing Query 1
The purpose of query 1 is to return all top-ranked participants for a selected event. This is our initial query:
SELECT * FROM c WHERE c.Eventname = '<eventname>' AND c.Eventdate = '<eventdate' ORDER BY c.TotalScore asc
However, for our use case, we don’t need to see all items. All we need to see is the first 100 participants. By using TOP and Order By we can optimize our query.
The TOP keyword returns the first N number of items in an undefined order. It will simply stop processing any other items. By adding Order By to our query the items TOP touches become predictable: it’s always the 100 highest scores. For more information, see SQL keywords for Azure Cosmos DB
SELECT TOP 100 * FROM c WHERE c.Eventname = '<eventname>' AND c.Eventdate = '<eventdate' ORDER BY c.TotalScore asc
When running our test again the results quite different:
| Query | Items returned | Initial RU charge | Optimized RU charge |
| 1 | 100 | 208 | 7 |
Optimizing Query 2
The purpose of query 2 is to return all events for a year a person participated in.
SELECT c.Eventname FROM c WHERE c.Eventdate > '<startdate>' AND c.Eventdate < '<enddate>' AND c.ParticipantId = '<id>'
This query doesn’t use the partition key and therefor hits all physical partitions. However, we only have at most 100 GB of data in our container, which means a maximum of two physical partitions. The latency for querying two physical partitions is very minimal. Since it’s also highly unlikely that a person will participate in hundreds of events in a single year, we will not optimize this query to use the partition key as a filter. For more information, see Partitioning and horizontal scaling in Azure Cosmos DB
Optimizing Query 3
The purpose of query 3 is to return all participants for a given event.
SELECT c.ParticipantFirstname, c.ParticipantLastname, c.ParticipantId FROM c WHERE c.Eventname = '<eventname>'
In this case, we cannot use the TOP statement since we might need to show all the participants. However, it’s very likely a user will not always browse through the entire list of participants. Therefor we can optimize this query by using pagination in our application and by using query pagination in Azure Cosmos DB.
Query pagination for Azure Cosmos DB can be implemented by using a continuation token in our application. Continuation tokens can be used as a bookmark for the query’s progress. Query executions in Azure Cosmos DB are stateless on the server side and can be resumed at any time using this token. For more information, see Pagination in Azure Cosmos DB
Our application will implement pagination and show 100 items per page. A user can click next to view the next 100 items. The first time Query 2 is executed we retrieve and store the continuation token in our application. We also make sure we set the MaxItemCount to 100. For any subsequent calls we will pass the continuation token to retrieve the next 100 items.
QueryDefinition query = new QueryDefinition("SELECT c.ParticipantFirstname, c.ParticipantLastname, c.ParticipantId FROM c WHERE c.Eventname = @Eventname")
.WithParameter("@Eventname", eventName);
string continuationToken = string.Empty;
using (FeedIterator<dynamic> resultset = _container.GetItemQueryIterator<dynamic>(query, null, new QueryRequestOptions() { MaxItemCount = 100 }))
{
FeedResponse<dynamic> response = await resultset.ReadNextAsync();
Console.WriteLine("Q3 took {0} ms. RU consumed: {1}, Number of items : {2}", response.Diagnostics.GetClientElapsedTime().TotalMilliseconds, response.RequestCharge, response.Count);
foreach (var item in response)
{
list.Add(item);
}
continuationToken = response.ContinuationToken;
}
The code snippet above shows that we set MaxItemCount property of QueryRequestOptions object to 100. This instructs Azure Cosmos DB to only return 100 items. From the FeedResponse object, we grab the ContinuationToken value and cache this in our application. When the user decides to view the next 100 items in the application the query will be executed again. However, this time we add the continuation token value instructing Azure Cosmos DB to return the next 100 items.
QueryDefinition query = new QueryDefinition("SELECT c.ParticipantFirstname, c.ParticipantLastname, c.ParticipantId FROM c WHERE c.Eventname = @Eventname")
.WithParameter("@Eventname", eventName);
using (FeedIterator<dynamic> resultset = _container.GetItemQueryIterator<dynamic>(query, continuationToken, new QueryRequestOptions() { MaxItemCount = 100 }))
{
FeedResponse<dynamic> response = await resultset.ReadNextAsync();
Console.WriteLine("Q3 took {0} ms. RU consumed: {1}, Number of items : {2}", response.Diagnostics.GetClientElapsedTime().TotalMilliseconds, response.RequestCharge, response.Count);
foreach (var item in response)
{
list.Add(item);
}
continuationToken = response.ContinuationToken;
}
When running our test again the results are:
| Query | Items returned | Initial RU charge | Optimized RU charge |
| 3 | 100 | 191 | 6 |
Optimizing Query 4
The purpose of query 4 is to show the total score for a single participant per event. This always returns one item.
SELECT c.ParticipantFirstname, c.ParticipantLastname, c.TotalScore FROM c WHERE c.ParticipantId = '<id>' AND c.Eventname = '<eventname>'
When a query always returns one item and also uses the partition key as a filter we can optimize this by using a point read. A point read is a key value look up based on partition key value and item Id. This is the most efficient way of retrieving a single item in Azure Cosmos DB and always consumes 1 RU. Executing a point read can only be done in the SDK by using the ReadItemAsync method. For more information see, Optimizing the cost of your requests in Azure Cosmos DB
ItemResponse<Marathon> response = await _container.ReadItemAsync<Marathon>(id, new PartitionKey(eventName));
When running our test again the results are:
| Query | Items returned | Initial RU charge | Optimized RU charge |
| 4 | 1 | 3 | 1 |
Optimizing Indexing policy
Now our queries are optimized greatly, we can tune the index policy by optimizing our range indexes. When analyzing Query 1 we see that two filters in the WHERE clause and an Order By is used. In case of multiple filters we can leverage composite indexes to achieve faster index lookup time. For more information, see Azure Cosmos DB indexing policies | Microsoft Docs.
"compositeIndexes": [
[
{
"path": "/Eventname",
"order": "ascending"
},
{
"path": "/Eventdate",
"order": "ascending"
},
{
"path": "/TotalScore",
"order": "ascending"
}
]
]
When running our test again the results are:
| Query | Items returned | Initial RU charge | Optimized RU charge |
| 1 | 100 | 7 | 6 |
We can see the RU consumption is slightly less and the index lookup time is around 10% faster. The differences will become even more noticeable on larger scale scenarios, where you might have over a million of documents in your container.
Monitoring
Once our application is finished we need to understand how to monitor Azure Cosmos DB to detect any issues or performance bottlenecks. The following metrics are very useful to monitor :
- Total Request Units. This metric shows the average amount of RUs consumed. When you see the average amount increasing this might indicate there are more requests executed by Azure Cosmos DB.
- Total Requests. Using this metric we can exactly see how many requests are processed by Azure Cosmos DB. We can even split this by operation type to understand which operation is executed the most.
- Normalized RU consumption. This metric shows you how much percent of the provisioned RUs are used. When this value reaches 100% any subsequent requests in that second might be throttled, depending on how many physical partitions you are having. A root cause could be that more requests are being executed per second. In this case, you should provision more RU’s. Another root cause could be inefficient queries are executed. For more information, see Troubleshoot Azure Cosmos DB request rate too large exceptions
- Provisioned Throughput and Auto scale max throughput. In case you have configured autoscale throughput you might want to monitor how many RU’s are being used to determine the effectiveness of auto scale. Auto scale max throughput metric shows the max autoscale limit you have configured. Provisioned throughput shows how many RU are used for any given second. For more information, see Create Azure Cosmos containers and databases in autoscale mode.
All the information above and more can be viewed using Insights for Azure Cosmos DB. This is a pre-created Azure Monitor Workbook that brings all these metrics together. For more information, see Monitor Azure Cosmos DB with Azure Monitor Cosmos DB insights – Azure Monitor
Get started
- Find out more about Azure Cosmos DB
- Four ways to dev/test free with Azure Cosmos DB
- The code used is published in GitHub
0 comments