
We’re thrilled to announce the latest refresh of Fabric Mirroring for Azure Cosmos DB, now available with several powerful new features that enhance your data analytics infrastructure. This update significantly improves the experience, making it easier than ever to replicate your Azure Cosmos DB data into OneLake in Microsoft Fabric—giving you more control and flexibility over your mirrored databases.
New Features
Entra ID Authentication Support for Source Connections

Azure Cosmos DB Mirroring now supports authentication via Microsoft Entra ID (formerly Azure AD), in addition to account keys. This enhancement allows organizations to use role-based access control (RBAC) when connecting to the source Azure Cosmos DB account, aligning with enterprise security and identity management best practices. Microsoft Entra ID authentication provides secure, compliant, and streamlined data ingestion into Fabric mirror artifacts.
Container Selection
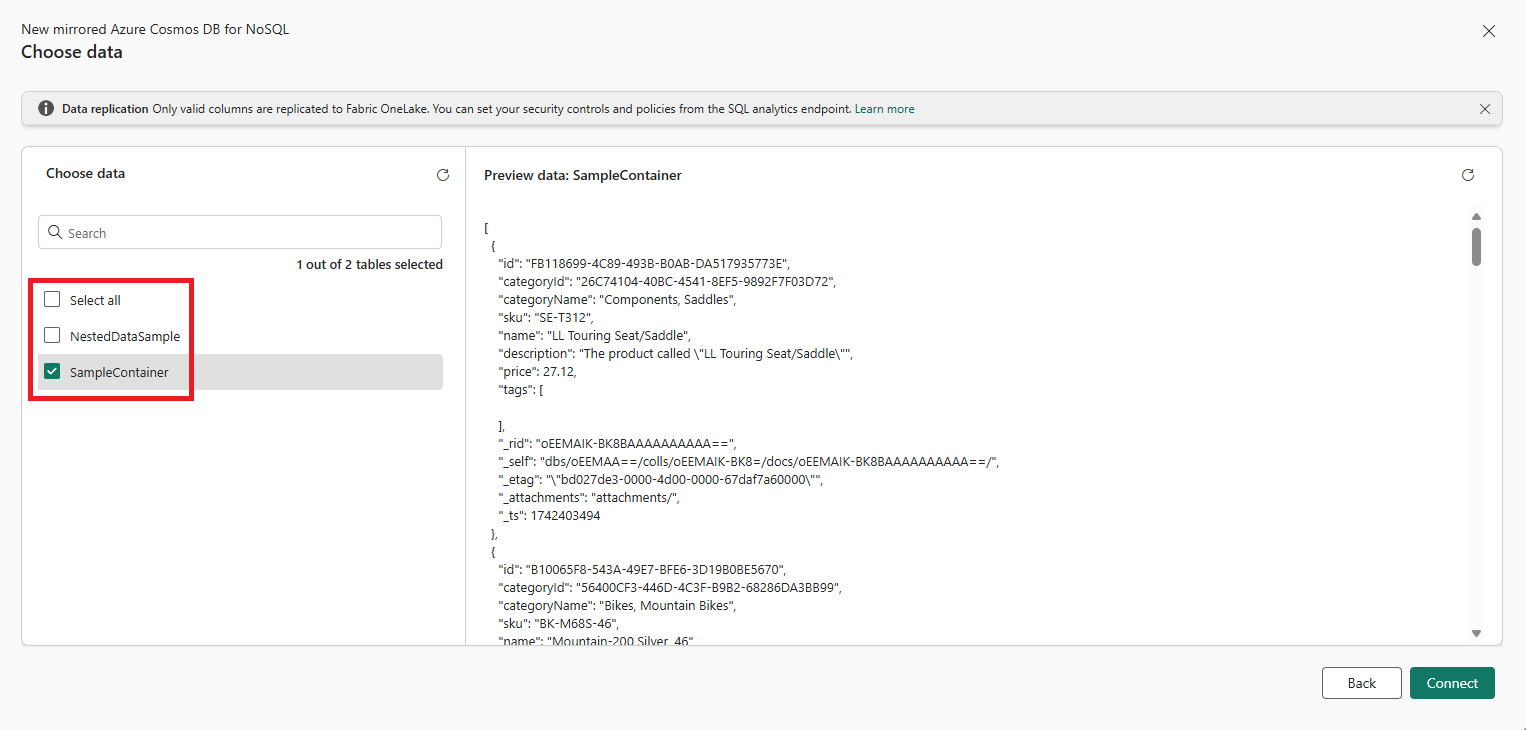
Azure Cosmos DB Mirroring now supports selective container replication, allowing you to specify which containers within a database to mirror into Microsoft Fabric. This enhancement gives you greater control over data movement and improves security granularity by mirroring only selected containers. By replicating only the necessary datasets, you can reduce Fabric storage costs and build a more efficient, fine-tuned data architecture for analytical workloads.
Invalid Column Name Handling / Column Mapping
Azure Cosmos DB Mirroring now supports a broader range of special characters in column names, including white spaces—the most requested capability—as well as wildcards like =, ;, {}, (), \n, \t. With this update, Azure Cosmos DB Mirroring handles complex or non-standard column naming conventions without interruption, enabling seamless mirroring operations across diverse schemas.
Vector Search for NoSQL API Compatibility
Azure Cosmos DB Mirroring now fully supports accounts that use vector search and indexing, allowing AI and machine learning workloads to take full advantage of Microsoft Fabric’s powerful analytics—while continuing to leverage Azure Cosmos DB’s high-performance vector capabilities.
Many AI workloads already store vector embeddings in Azure Cosmos DB and use vector search for semantic retrieval and recommendation systems. With this update, you can now seamlessly integrate those workloads with Microsoft Fabric to unlock advanced analytics, model evaluation, and real-time reporting—all within a unified data platform.
For more details, explore the documentation on Vector Search and Indexing for Cosmos DB and Fabric Data Science and AI Experiences.
CRUD Support
Azure Cosmos DB Mirroring now offers comprehensive REST API support, giving data teams full programmatic control over mirrored artifacts. With this release, you can automate key operations such as mirror creation, deletion, replication start/stop, and table-level status monitoring. The new API surface increases operational flexibility, simplifies large-scale deployment and management, and supports seamless integration into CI/CD workflows.
To learn more about Microsoft Fabric Mirroring Rest APIs, visit the documentation here.
Auto Inference for SQL

With the new auto inference feature, Azure Cosmos DB Mirroring automatically infers the schema for your nested data using OPENJSON, eliminating the need to manually define schemas—saving time and reducing the risk of errors. This intelligent capability is especially valuable for workloads with dynamic or unpredictable structures, as it detects and applies the appropriate schema automatically, streamlining the entire data integration process.
Why Use Fabric Mirroring for Azure Cosmos DB?
Fabric Mirroring for Azure Cosmos DB delivers a seamless, no-ETL experience, enabling near real-time replication of your Azure Cosmos DB data into Fabric OneLake. This integration keeps your data up to date and readily available for analytics—without affecting the performance of your transactional workloads. With these new features, Azure Cosmos DB Mirroring continues to offer a deeply integrated, end-to-end solution for your data analytics needs.
Get Started Today
We invite you to explore these new features and see how they can enhance your data management and analytics workflows. For more information about Azure Cosmos DB Mirroring, visit our documentation.
Please note, to start using the feature, you must enable tenant admin switch. Otherwise, the feature will not be available for your Fabric workspace. For more information, please visit “Enable Mirroring”.
For any questions or feedback, please reach out to our team at fabriccosmosdbmirror@microsoft.com.
Leave a review
Tell us about your Azure Cosmos DB experience! Leave a review on PeerSpot and we’ll gift you $50. Get started here.
About Azure Cosmos DB
Azure Cosmos DB is a fully managed and serverless NoSQL and vector database for modern app development, including AI applications. With its SLA-backed speed and availability as well as instant dynamic scalability, it is ideal for real-time NoSQL and MongoDB applications that require high performance and distributed computing over massive volumes of NoSQL and vector data.
To stay in the loop on Azure Cosmos DB updates, follow us on X, YouTube, and LinkedIn.
0 comments