
This blog post was co-authored by Revin Chalil, Rodrigo Souza and Anitha Adusumilli from the Azure Cosmos DB Team.
Today, we are excited to announce that custom partitioning is in preview for Azure Synapse Link for Azure Cosmos DB. This capability improves query performance by enabling you to partition Azure Cosmos DB analytical store data using keys that are frequently used as query filters.
In addition to custom partitioning, this blog post also covers two Azure Synapse Link capabilities that have been enabled in the last few months: serverless compatibility and full fidelity schema.
Custom partitioning for analytical workloads
You can now use custom partitioning to improve analytical query performance. By default, data in Azure Cosmos DB analytical store is not partitioned. If your analytical queries have frequently used filters, you now have the option to partition based on these fields.
Partitioned data from the Azure Cosmos DB analytical store is written to the partitioned store, which points to the primary storage account linked to your Azure Synapse workspace. Analytical queries with filters on the partition columns can benefit from partition pruning and avoid scanning any partition that does not satisfy the filters. The pruned data from the partitioned store is then automatically merged with the most recent non-partitioned data from the analytical store, returning near real-time results for your queries.
By compacting and optimizing the analytical data written to the partitioned store, custom partitioning also helps to improve the query performance when there is a high volume of update or delete operations on the underlying Azure Cosmos DB container. Instead of keeping track of multiple versions of records in the analytical store and loading them during each query execution, the partitioned store only contains the latest version of the data.
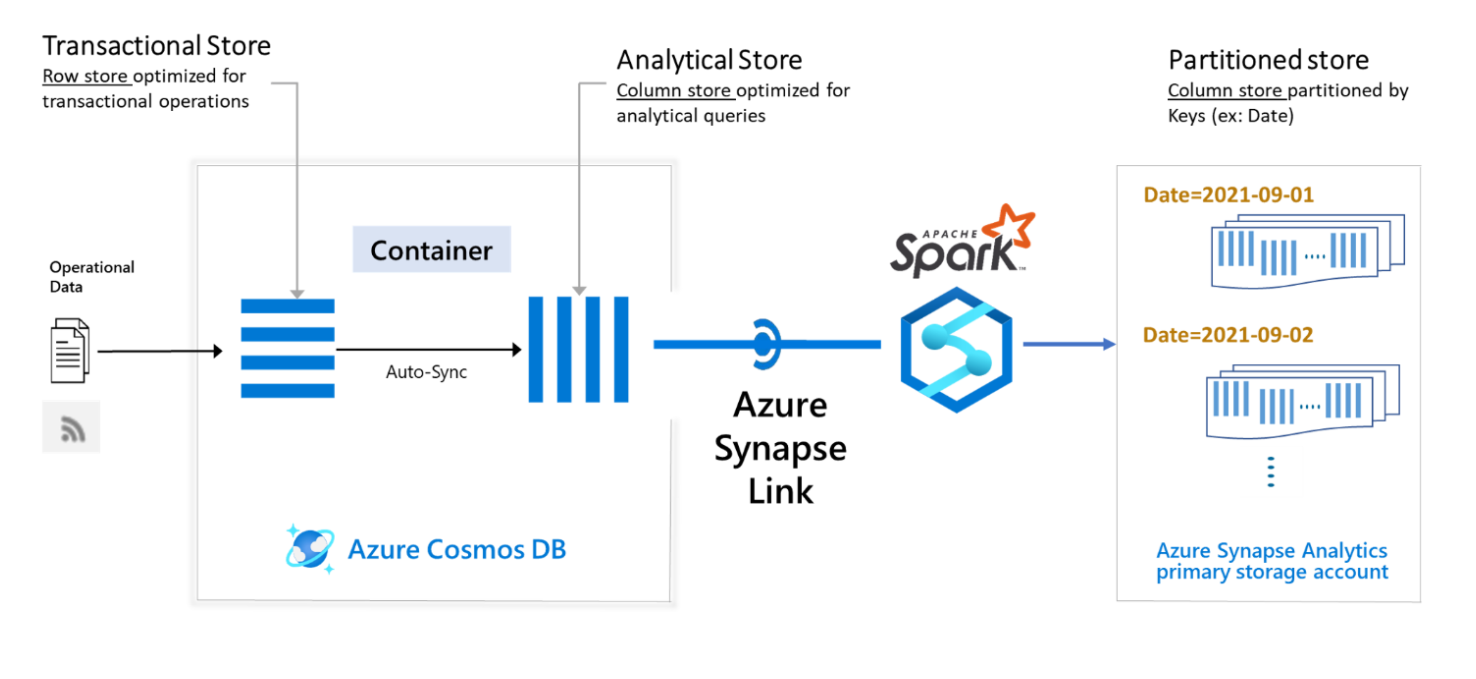
Triggering a custom partitioning job
Partitioning can be triggered from an Azure Synapse Spark notebook using Azure Synapse Link. You can schedule it to run as a background job, once or twice a day, or it can be executed more often if needed. You can also choose one or more fields from the dataset as the analytical store partition key.
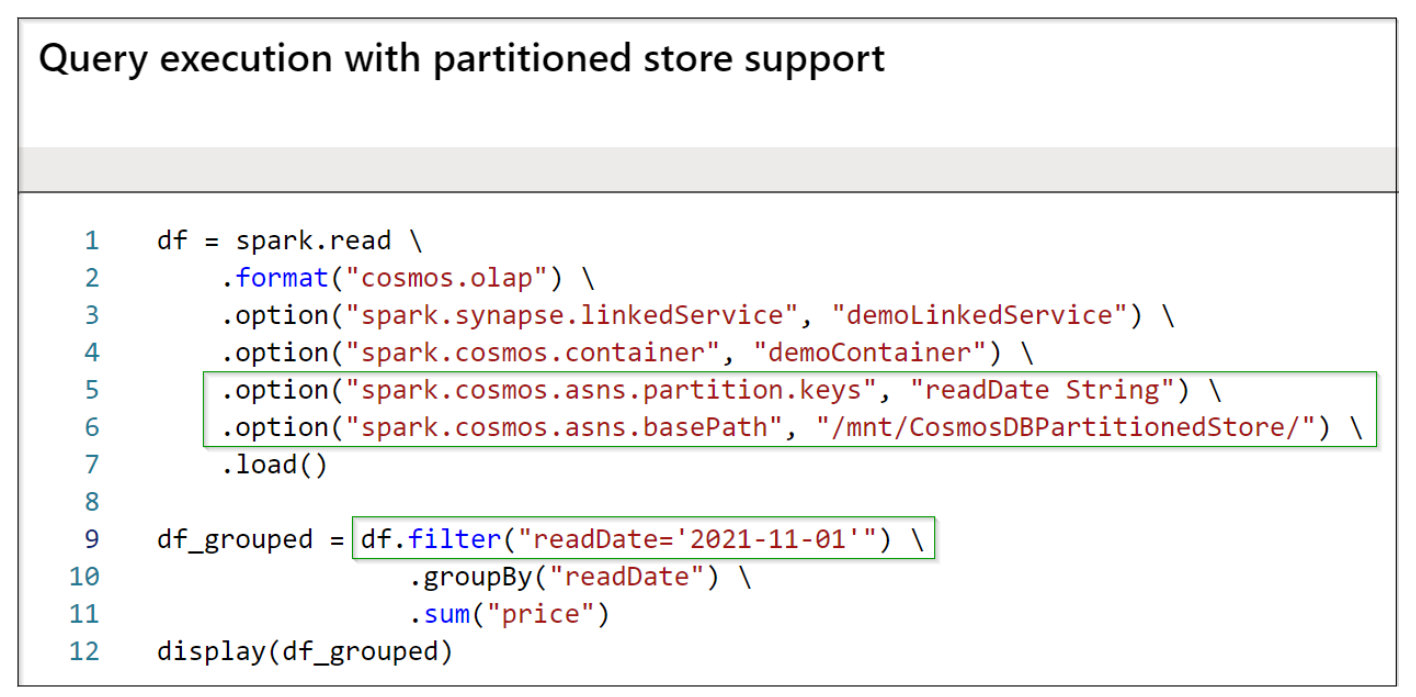
In the below sample, the ”readDate” is chosen as the partition key. Each time you trigger the partitioning job, the incremental analytical store data will be partitioned and written to the partitioned store, which is indicated by the “basePath” config. Please see configure custom partitioning to understand the different configurations, which can be used with custom partitioning.

Analytical query execution on partitioned store
While querying, specify the same ”partition.keys” and ”basePath” configs, as defined in the partitioning job, to make use of the partitioned store in the query path.
Below filter will avoid scanning partitions other than “readDate = ‘2021-11-01’” partition:
In summary, custom partitioning can help improve analytical query performance when partition column(s) are used as query filters. To learn more, refer to our documentation.
What customers say about Azure Synapse Link for Azure Cosmos DB
“AEMO leverages Azure and Azure Cosmos DB to ingest terabytes of critical metering data. With the significant amounts of data that our system brings in, the capability to do custom partitioning in Azure Cosmos DB’s HTAP functionality was essential for us to provide performant insights to our internal stakeholders.”
– Australian Energy Market Operator
Azure Synapse Link compatibility with Azure Cosmos DB serverless
You can now use Azure Synapse Link with Azure Cosmos DB serverless accounts. Serverless is ideal for developing, testing, and running production applications where the traffic pattern is unknown. These accounts are billed on consumption, meaning that you are charged only for the Request Units consumed by database operations and the GBs of transactional and analytical storage consumed by your data. Visit our pricing page for details on Azure Cosmos DB options.
This feature is generally available in all Azure regions, using Azure Powershell or CLI.
Full fidelity schema for Azure Cosmos DB Core (SQL) API accounts
Now you can use full fidelity schema for Azure Cosmos DB Core (SQL) API containers. This provides you with more flexibility to run analytical queries against Core (SQL) API containers with mixed data types for properties or nested structures. Here is some important information on this capability:
- By default, Azure Synapse Link supports well-defined schema for Core (SQL) API containers. If you want this to be changed to full fidelity schema, you should specify this option, when you are enabling Azure Synapse Link on your account.
- Once set, this setting cannot be changed. Existing accounts with Azure Synapse Link-enabled can’t have their schema option changed.
- If you enable Azure Synapse Link in your Core (SQL) API database account using the Azure portal, it will always be well-defined. You must use PowerShell or Azure CLI to override the default option and use full-fidelity schema in Core (SQL) API database accounts.
- This is an account-level configuration, meaning that all containers in all databases in that database account will have the same schema inference method defined when Azure Synapse Link was enabled.
This feature is generally available in all Azure regions.
About Azure Synapse Link for Azure Cosmos DB
Run near-real-time analytics and AI on the operational data within your Azure Cosmos DB NoSQL database, to reduce time to insight. Azure Synapse Link for Azure Cosmos DB seamlessly integrates with Azure Synapse Analytics without data movement or diminishing the performance of your operational store.
0 comments