

The largest external customers of Azure Cosmos DB API for NoSQL, running some of the biggest and most mission critical workloads in Azure, are primarily Java users!
In this blog we’ll give you a quick run-down of all our supported Java-based client libraries, including our battle-tested core Java SDK, its key supported features, and where to go to find out more!
The Spring Data Client Library
Built on top of the Java SDK, the Azure Cosmos DB Spring Data Client Library allows developers to build Java applications more rapidly on Azure Cosmos DB using Spring Boot, one of the most popular application development frameworks for Java.
We’ve created a starter guide on building Java applications using Spring and Cosmos DB. If you’re already well versed in Spring, head over to our Spring Data samples repo to get started, or use Spring Initializr to generate a sample based on the dependencies you need, including Azure Cosmos DB!
The OLTP Spark Connector
Apache Spark is a powerful framework for distributed in-memory processing and computation, popular for analytics and massive scale data movement use cases.
Build on top of the Java SDK for Azure Cosmos DB, the OLTP Spark Connector allows users to read and write data to Azure Cosmos DB’s transactional data store and manipulate it using Spark Dataframes. Check out our OLTP Spark Connector documentation, and OLTP Spark Connector samples repo!
Structured Streaming
The OLTP Spark Connector supports streaming of data from Azure Cosmos DB by leveraging the change feed and processing changes in micro-batches. The Connector has built-in checkpointing, allowing processing to be picked up from the last processed document when streaming is stopped, or if a problem causes a crash. The write stream leverages bulk support in the Java SDK to saturate throughput when writing data to the desired target. Check out our Scala Notebook samples and PySpark Notebook samples to get started with structured streaming.
Throughput Control
The OLTP Spark Connector includes a feature called throughput control, which allows you to provide a level of performance isolation between large Spark jobs that might be running against the Cosmos DB transactional store, and the steady state workload of everyday applications that use the database. The feature works by limiting the amount of request units that can be consumed by a given Spark client. Learn more with our OLTP Spark Connector throughput control documentation.
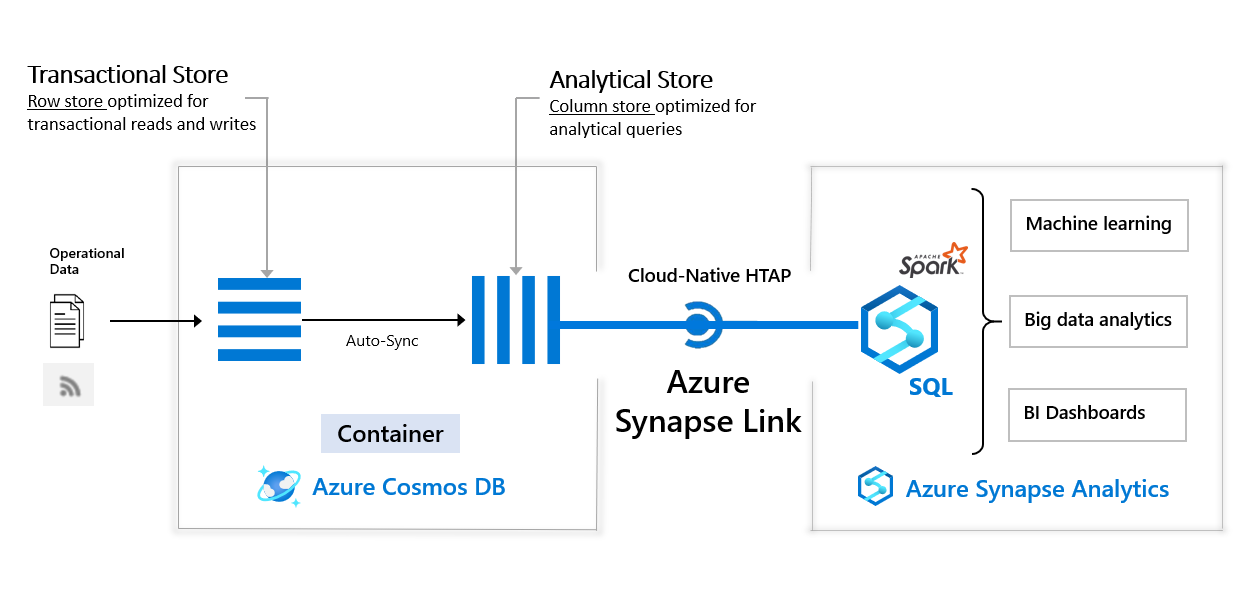
Cloud-native hybrid transactional and analytical processing (HTAP)
The OLTP Spark Connector is a standalone connector, which interacts with the Azure Cosmos DB transactional store using spark.read.format("cosmos.oltp"). However, it is also built-in to Apache Spark for Azure Synapse, where you can also use a separate OLAP Spark Connector built-in to the platform to query the Azure Cosmos DB analytical store, using spark.read.format("cosmos.olap").
The analytics store is a fully isolated, column-oriented data store that leverages Azure Synapse Link and is automatically kept in sync with the transactional store (max 2 minutes latency). This allows near real time analytics with total performance isolation in Azure Synapse Analytics against your operational data in Cosmos DB at planet scale!
Check out our Spark OLAP Connector documentation and samples!
The Apache Kafka Source and Sink Connectors
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. In partnership and collaboration with Confluent, we maintain source and sink Apache Kafka connectors for Azure Cosmos DB. As with all our Java-based libraries, these are built on top of the Java SDK for Azure Cosmos DB.
Check out our blog on the Kafka connectors describing the architecture and use cases. You can also take a look at our Azure Cosmos DB Kafka Connector documentation, the Azure Cosmos DB Kafka Connectors GitHub repository, as well as instructions on how to setup, and Confluent trial (Quick start)!
The Java SDK
The Java SDK for Azure Cosmos DB is our core library for building Java applications on Cosmos DB from the ground up. All major features in Azure Cosmos DB are surfaced in this library first, and all our other supported Java-based libraries use it to communicate with Azure Cosmos DB.
The Java SDK includes many advanced capabilities, and was designed for reactive programming, using project reactor. You can find documentation on the latest supported Java SDK here, and a checklist of Java SDK best practices. If you’re new to reactive programming, you may also want to check out our reactor pattern guide. You can also find a comprehensive array of Azure Cosmos DB Java SDK samples covering the majority of capabilities in our SDK.
Some important additional helper features built into the SDK include the following:
Change Feed Support
Azure Cosmos DB provides a persistent, distributed record of changes to a container in the order they occur, known as the change feed. You can interact with the change feed at massive parallel scale in Java using one of two models:
-
- The “pull model” – you have more flexibility on how to manage state changes, as well as orchestrating processing of the change feed across many partitions in parallel. However, you need to build you own mechanisms for handling this. Find out more on the change feed pull model or check out this Change Feed pull model sample.
- The “push model” (aka the “change feed processor”) – handling state processing across many partitions in parallel is done automatically with the change feed processor, which is a built-in capability for the Java SDK. Find more detail on how to implement the change feed processor in your applications.
Bulk Support
Bulk refers to scenarios where you need to dump a big volume of data in to Azure Cosmos DB, with as much throughput as possible. The Java SDK provides a built-in library for bulk support. Bulk is about throughput, not latency. Read our blog on when the readMany method can help balance between latency and client-side resources!
Transaction Support
Azure Cosmos DB supports full ACID compliant transactions with snapshot isolation for operations within the same logical partition key. In the Java SDK, the TransactionalBatch class is used to define a batch of point operations that need to either succeed or fail together with the same partition key in a container. Read all about Transaction batch support for Java SDK in Cosmos DB or check out the Java SDK Transaction batch sample.
Patch Support (partial update)
Patch support in the Java SDK allows the client to send only the fields that require update/addition/removal over the wire, instead of sending the entire document. This features also ensures there is no eTag contention from highly concurrent updates. Read about Java SDK patch support in our documentation or check out our Java SDK patch sample.
Hierarchical partition key support
Azure Cosmos DB distributes your data across logical and physical partitions based on your partition key to enable horizontal scaling. With hierarchical partition keys, or sub-partitioning, you can configure up to a three-level hierarchy for your partition keys to further optimize data distribution and enable higher scale. This can help in scenarios where synthetic keys are otherwise required but difficult to maintain, or in scenarios where the logical partition key storage limit would otherwise be reached. Check out documentation and sample code here!
Direct mode connectivity
The Java SDK supports two forms of connectivity: direct and gateway mode (see available connectivity modes for more information). In direct mode, applications connect directly to backend replicas in Azure Cosmos DB, facilitating maximal performance. This allows the service to fulfil a single-digit millisecond latency SLA for reads and writes within a given region – still unparalleled for any database service in the cloud. The SDK maintains complex routing, retry, and error handling logic for communication with backend replicas.
Get Started with Java in Azure Cosmos DB
- Azure Cosmos DB Java SDK v4 technical documentation
- Diagnose and troubleshoot Azure Cosmos DB Java SDK v4
- Java SDK v4 getting started sample application
- Azure Cosmos DB Spring Data Sample
- Cosmic Works Java
- Release notes and additional resources
- Exploring the Async API (reactor programming)
About Azure Cosmos DB
Azure Cosmos DB is a fast and scalable distributed NoSQL database, built for modern application development. Get guaranteed single-digit millisecond response times and 99.999-percent availability, backed by SLAs, automatic and instant scalability, and open-source APIs for MongoDB and Cassandra. Enjoy fast writes and reads anywhere in the world with turnkey data replication and multi-region writes.
To easily build your first database, watch our Get Started videos on YouTube and explore ways to dev/test free
0 comments