
Source and sink Apache Kafka connectors for Azure Cosmos DB are now generally available, in collaboration with Confluent. The connectors can also be used in self-managed clusters if preferred, with no code changes needed in the application tier and controlled fully through configurations.
Kafka Connector Use Cases
Microservice Architectures
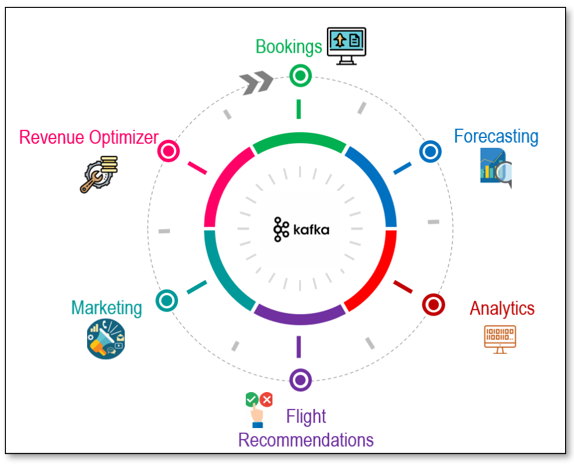
Figure 1: Microservices communicating with one another in a database agnostic manner by leveraging Kafka
Microservice architectures involve multiple services operating independently to serve a business function. These microservices may be built on different data stores, with a variety of formats and schemas. Some may be backed by relational data stores, some on horizontally scalable NoSQL services like Azure Cosmos DB and others on analytical and warehousing stores.
However, these microservices will need to communicate with one another and share data for serving additional business functions. Furthermore, data from these microservices may be needed for serving downstream functions such as analytics, aggregations and archiving among others.
In the absence of a common platform like Kafka, communication pipelines between services cannot be data and format agnostic, with the need for deeply complex and intertwined dependencies. With Kafka’s rich ecosystem of source and sink connectors for a plethora of database services, microservices can communicate with each another and other downstream services seamlessly, while continuing to operate independently on a database that best fits their immediate function.
Data Migration
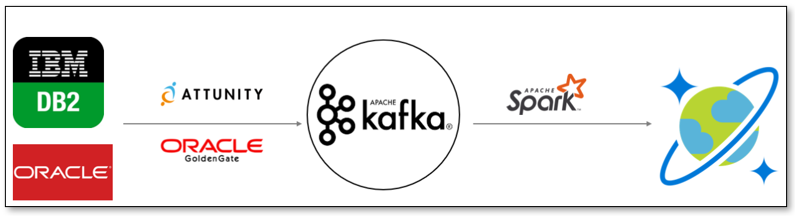 Figure 2: Data migration architecture leveraging Kafka as a middle-man
Figure 2: Data migration architecture leveraging Kafka as a middle-man
Data modernization efforts frequently involve migrations from to highly scalable and highly available services like Azure Cosmos DB. Tables from relational data stores are moved into Kafka topics either through CDC functionality or source Kafka connectors. Once staged, they can be converted into JSON documents through varying degrees of transformations before being ingested into Azure Cosmos DB at scale.
Smaller migrations may involve a simple movement of data with minimal transformations, while the more common large scale migrations will involve additional components in the Kafka ecosystem such as Kafka Streams and ksqlDB in conjunction with Kafka Connect.
Source & Sink Connector Architecture
Source Connector
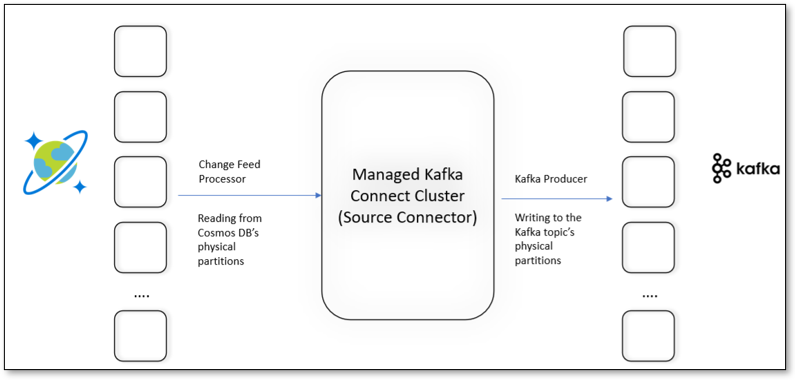
Figure 3: Architecture of the Kafka Source Connector for Azure Cosmos DB
The source connector for Azure Cosmos DB is built using the Java v4 client by leveraging the inbuilt Change Feed Processor as well as the Apache Kafka Producer library.
Much like a Kafka Consumer that is responsible for retrieving changes from each broker for the topic, handle offsets and periodically checkpoint progress, the Change Feed Processor for Azure Cosmos DB is responsible for picking up changes across the underlying physical partitions for the container, managing lease ownership and publishing continuation tokens (equivalent of offsets in Kafka) to track progress.
With a Kafka Connect cluster configured with the Azure Cosmos DB source connector, the following operations are performed seamlessly under the covers:
- A new instance of the Java client is instantiated per Worker in the Kafka Connect cluster
- A list of physical partitions for the Azure Cosmos DB container is retrieved by each client instance
- Ownership of physical partitions is assigned to each of the client instances across the cluster through a lease container
- Each client instance retrieves changes from the physical partitions it owns
- Periodic checkpointing is done to track progress made by the Azure Cosmos DB clients
- Periodic health checks are made to ensure a new owner is assigned if a worker in the Kafka Cluster becomes unavailable
- Data retrieved from the Azure Cosmos DB source container is converted into the format specified in the converter through Single Message Transforms (SMTs) and written to the Kafka topic
- Error handling and dead letter queues are also handled within the source connector
Sink Connector
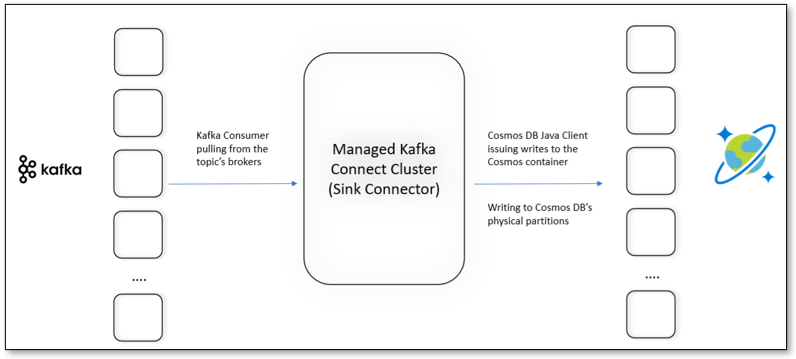
Figure 4: Architecture of the Kafka Sink Connector for Azure Cosmos DB
The sink connector for Azure Cosmos DB is built using the Apache Kafka Consumer library in conjunction with the Azure Cosmos DB Java v4 client.
With a Kafka Connect cluster configured with the Azure Cosmos DB sink connector, the following operations are performed seamlessly without the need for manual intervention:
- Consumers within the Consumer Group retrieve the broker partitions for the source Kafka topic
- The Consumer Group assigns the topic’s partitions to each of the Consumers (Workers) within the cluster
- The Consumers poll the broker partitions for incoming messages for the topic
- Offsets are periodically committed to capture state
- If a Consumer becomes unavailable, other Consumers will resume picking up changes from the last committed offset for the partitions owned by the original Consumer
- Messages retrieved from the Kafka cluster are converted to JSON if needed and written to the Azure Cosmos DB container through the Azure Cosmos DB client
Getting Started
- Download the source and sink connectors from Confluent
- Find examples on configuring the source connector in a self-managed or fully managed Kafka Connect cluster
- Find examples on configuring the sink connector in a self-managed or fully managed Kafka Connect cluster
- Find examples in Confluent’s blog here to create a fully managed Connect cluster with the Azure Cosmos DB sink connector on Confluent Cloud
- Register for the online talk on 08/30 for a technical deep dive and demo of the Azure Cosmos DB sink connector
0 comments