

We’re excited to announce dynamic scaling per region and per partition (public preview) for all new Azure Cosmos DB accounts to help optimize and lower costs for your workload!
By default, Azure Cosmos DB autoscale scales workloads based on the most active region and partition. For non-uniform workloads that have different workload patterns across regions and partitions, this can cause unnecessary scale-ups.
Over the years, we’ve heard feedback from our autoscale customers that this can be pretty unforgiving for unpredictable workloads. With this improvement to autoscale, the per region and per partition autoscale feature now allows your workloads’ regions and partitions to scale independently based on usage.
What is dynamic scaling per region and per partition?
As you may already know, Azure Cosmos DB’s autoscale automatically and instantly scales your throughput (RU/s) based on the workload’s usage. This is well-suited for mission-critical applications that have variable or unpredictable traffic patterns.
Previously, multi-region accounts were billed based on your hottest region. Now, autoscale per region and per partition bills you for the consumption of all regions independently.
This also applies to partitions. Previously, all partitions scaled uniformly based on the most active partition which causes unnecessary scale-ups if only one or few partitions were active. With this new feature, we’re excited to announce that partitions now scale independently, improving cost efficiency for non-uniform large-scale workloads with multiple partitions.
Example scenario
To dig into the benefits of this feature even more, let’s go through an example scenario:
Alice is currently suffering from a hot partition problem in her autoscale workload and her workload is scaling to this one partition and region. Her workload consists of a collection with 1000 RUs and 2 partitions – each partition can go up to 500 RU/s. For one hour of activity, let’s see what her bill would look like.
Today with 2 regions:
- Region 1 (Write Region)
- P1: Scales up to 500 RU/s (100% utilization) – 50 RU/s for writes & 450 RU/s for reads
- P2: Scales up to 200 RU/s (40% utilization) – 200 RU/s for all reads
- Region 2 (Read Region)
- P1: Scales up to 150 RU/s (30% utilization) – 50 RU/s for write replication & 100 RU/s for reads
- P2: Scales up to 50 RU/s (10% utilization) – no writes or reads at all (10% minimum rule applied)

Total Bill: 2000 RUs since region 1 reached 100% utilization (1000 RU/s) at some point during the hour and we multiply this by the number of regions which is 2.
Alice is frustrated as she was only able to use one of her partitions to max utilization (500 RU/s) but is getting charged for her whole offer. Moreover, one of her regions was more idle than the other but is getting charged at its full offer, for a total charge of 2000 RU/s.
Let’s see how Alice can benefit from this new feature.
With both dynamic scaling per region and per partition feature:
- Region 1 (Write Region)
- P1: Scales up to 500 RU/s (100% utilization) – 50 RU/s for writes & 450 RU/s for reads
- P2: Scales up to 200 RU/s (40% utilization) – 200 RU/s for all reads
- Region 2 (Read Region)
- P1: Scales up to 150 RU/s (30% utilization) – 50 RU/s for write replication & 100 RU/s for reads
- P2: Scales up to 50 RU/s (10% utilization) – no writes or reads at all (10% minimum rule applied)
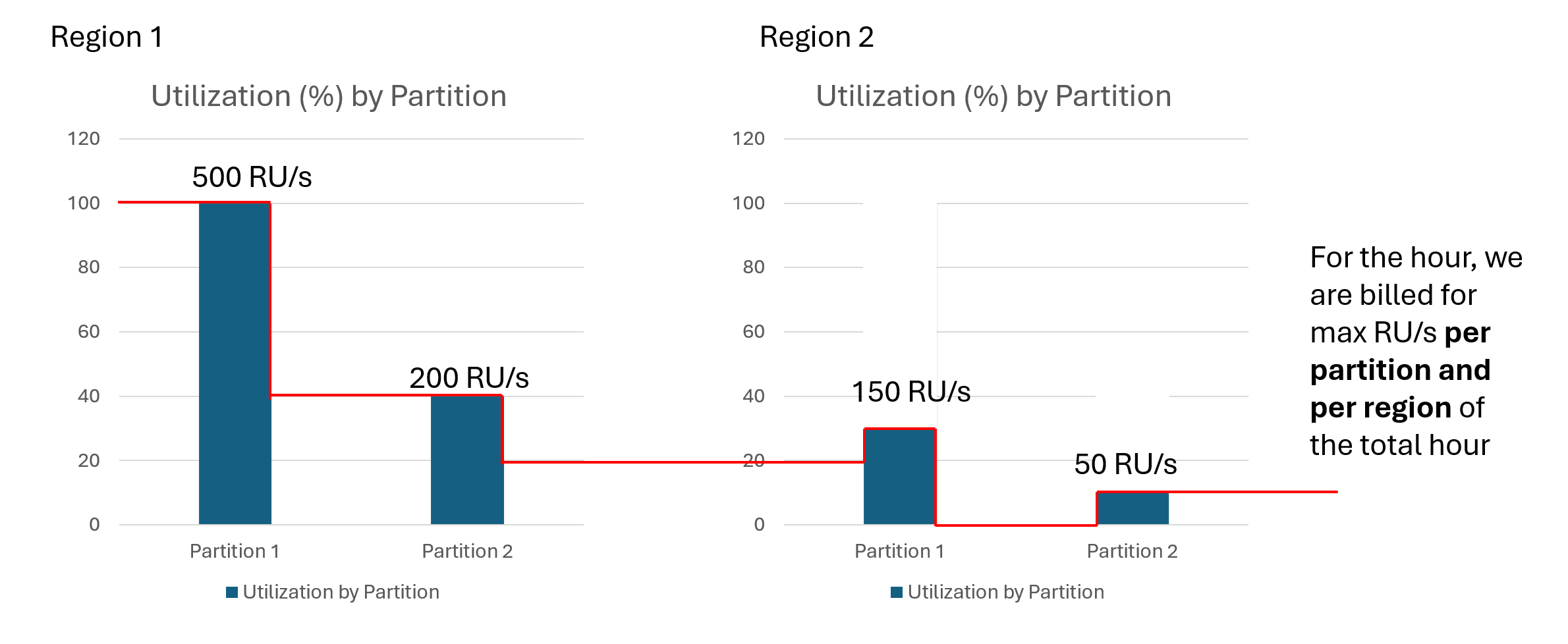
Total Bill: 900 RUs since we sum up all max RU/s utilized per hour per region per partition.
Alice is much happier with the overall consumption of her workload!
Ideal use cases
We recommend this feature to all new customers interested in autoscale, but there are two specific use cases that can benefit the most from dynamic scaling per region and per partition:
- Database workloads that have a highly trafficked primary region and a secondary passive region for disaster recovery.
- By enabling autoscale per region and partition, you can now save on costs as the secondary region will independently and automatically scale down while idle and automatically scale-up as it becomes active and while handling write replication from the primary region.
- Multi-region database workloads.
- These workloads often observe uneven distribution of requests across regions due to natural traffic growth and dips throughout the day (e.g. a database might be active during business hours across globally distributed time zones).
Getting started
To get started, create a new Azure Cosmos DB autoscale account. Use this guide to learn how to enable autoscale on a new or existing workload.
Once your account is created, head over to the Features pane in Azure Portal. Here, you’ll be able to enable to feature. Please note that this enables the feature on all autoscale collections within the account.

For more information, please visit our documentation on dynamic scaling per region and partition.
About Azure Cosmos DB
Azure Cosmos DB is a fully managed and serverless distributed database for modern app development, with SLA-backed speed and availability, automatic and instant scalability, and support for open-source PostgreSQL, MongoDB, and Apache Cassandra. Try Azure Cosmos DB for free here. To stay in the loop on Azure Cosmos DB updates, follow us on Twitter, YouTube, and LinkedIn.
Hello,
Is the “accounts created after November 15, 2023” restriction just whilst it is in preview and something that will be lifted when GA?
Thanks.