

Written by: Maggie Liu, Thiago Rotta, Vinicius Souza, James Tooles, & Microsoft AI Co-Innovation Labs
1. Introduction
Generative AI is moving from proof‑of‑concept pilots to mission‑critical workloads at a velocity rarely seen in enterprise technology. The first wave of projects typically stood up a single “do‑everything” agent, a large language model wrapped with prompt‑engineering, a vector store, and a handful of API connectors. That pattern is excellent for narrow FAQ bots, yet it collapses under the weight of real‑world enterprise constraints:
- Domain expertise that spans dozens of business lines
- Strict data‑sovereignty and model‑access policies
- The need to plug in new capabilities or swap models without redeploying the entire stack overnight
Enterprises adopting the latest advancements in AI are therefore pivoting toward multi‑agent system, collections of autonomous, task‑specialized agents that coordinate through an orchestrator, mirroring how cross‑functional human teams tackle complex work. Each agent couples:
- LLM or SLM core (large or small language model)
- Domain‑specific toolset (APIs, knowledge graphs, proprietary data)
- Short‑and long‑term memory to refine plans over time
The breakthrough is not an individual agent’s intelligence, but the emergent behavior that surfaces when many agents share context, divide labor, and merge results into a cohesive answer.
2. Problem Statement
Despite the rapid adoption of LLM-powered assistants across sectors, most enterprise implementations remain anchored in single-agent architectures, systems where a single, generalized agent is tasked with understanding every request, invoking every tool, and adhering to every policy. While this “centralized intelligence” model is adequate for constrained use cases (e.g., internal FAQs or chatbot front doors), it fundamentally breaks down under the demands of modern enterprise workflows.
Organizations attempting to scale this model encountered several structural challenges:
- Over generalization: A single agent attempting to serve multiple lines of business—each with its own regulatory, linguistic, and decision-making nuances—leads to brittle prompts, generic responses, and degraded model performance across the board.
- Performance bottlenecks: When everything runs through a single agent, the system slows down—especially as more users send requests or the tasks get more complex and require multiple steps or tools.
- Security and Compliance exposure: Centralized access to diverse datasets such as financial, healthcare, PII, etc, violates core principles like data minimization and least-privilege access, making it difficult to satisfy regulatory frameworks.
- Change management complexity: Because all logic, tools, and memory are coupled in one agent, adding a new feature or domain use case requires regression testing the full stack. This dramatically slows time-to-value and creates risk-aversion among platform teams.
- Inflexibility to specialize: As use cases evolve, new tools, APIs, and models (e.g., lightweight SLMs for local inference or fine-tuned vertical models) could be integrated to incorporate the latest innovations by monolithic agents resist this modularity, stalling innovation.
Enterprises that continued down this path found themselves constrained, not by the capabilities of AI itself, but by the rigidity of the systems they’ve wrapped around it with a single agent handling multiple domains. This has resulted in slower innovation, higher operating risk, and growing divergence from best-in-class architectures now being adopted in competitive sectors.
The shift toward modular, multi-agent systems is no longer a research aspiration, it’s a strategic imperative for organizations seeking to operationalize AI at scale, which has been growing in adoption as enterprises refactor their existing single-agent to multi-agent architectures.
3. Solution
Instead of stretching a single agent past its breaking point, the solution is to distribute the workload across specialized agents, each focused on a specific domain or function, while a central keeps the system coordinated and contextually aware. This shift leads directly to a multi‑agent architecture, where domain‑expert agents handle tasks independently within their domain boundaries, and the orchestrator ensures seamless integration across the different components.
At a foundational level, this architecture is composed of:
- Multiple domain agents that focus on specialized functions (e.g., payments agent for wire transfers, investment advisor agent for portfolio guidance)
- An orchestrator responsible for intent routing, context preservation, and task routing, ensuring that each query lands with the right expert agent
- A context-sharing mechanism that allows agents to collaborate effectively while presenting a unified experience to the user
To support the modular, scalable, and specialized behavior required by enterprise-grade AI systems, enterprises are adopting a hierarchical multi-agent architecture that combines centralized orchestration with distributed intelligence. As demonstrated below, this architecture is designed to mirror the structure of real-world organizations: A central coordinator (the orchestrator) delegates tasks to specialized agents, each equipped with domain-specific capabilities, tools, and memory. The system is divided into clear functional layers, including orchestration, classification, agent execution, knowledge retrieval, storage, and integration, allowing for flexibility, governance, and performance at scale.
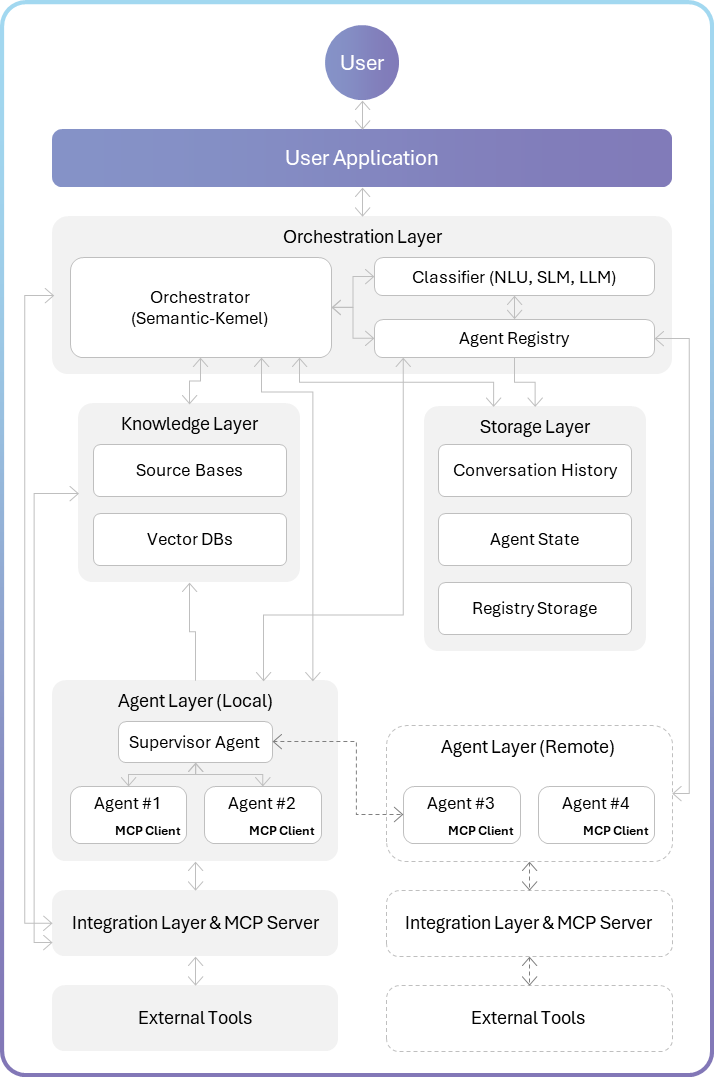
3.1 Components breakdown
Orchestrator (Semantic Kernel)
- The central coordination component that manages the flow of requests and responses throughout the system. It provides unified management, ensuring appropriate routing, maintaining context, and handling the lifecycle of requests.
- How it works: The orchestrator receives requests from the User Application, determines how to process them, coordinates with the appropriate components, maintains state, and eventually returns responses.
Classifier (NLU, SLM, LLM)
- The component is responsible for understanding user inputs and determining the appropriate routing within the system. It ensures that user requests are properly understood and directed to the most suitable agent, improving response quality and system efficiency.
- How it works: Analyzes the content, context, and intent of user inputs to categorize them and determine appropriate handling. The approach involves using options ranging from less to more expensive ones, NLU 🡪 SLM 🡪 LLM | SML based on certainty to determine the use of intent or continuation. If no intent is detected by the end of the process, return “IDK” (I Don’t Know).
Agent Registry
- A directory service that maintains information about all available agents, their capabilities, and operational status. It enables dynamic discovery and utilization of agents, supporting scalability and system evolution without hard-coded dependencies.
- How it works: Maintains a database of agent metadata, including capabilities, endpoints, and operational parameters. Provides look-up and selection functions to identify appropriate agents for specific tasks.
- Subcomponents
- Discovery Module
- Actively identifies and registers new agents
- Implements discovery protocols
- Handles administrator-initiated agent registration
- Performs network scanning to locate potential agents
- Manages the agent onboarding workflow
- Maintains discovery history and retry logic
- Validation Module
- Verifies agent capabilities and interfaces
- Performs security validation and authentication
- Tests agent functionality through probe requests
- Ensures compatibility with system requirements
- Generates agent metadata for classification
- Registry Storage
- Persistent storage for agent information
- Maintains version history and capability evolution
- Stores security credentials and access policies
- Logs agent interaction metrics and performance data
Supervisor Agent (Optional considering scalability requirements)
- A specialized agent responsible for coordinating the activities of other agents to solve complex tasks. It enables decomposition of complex tasks into subtasks that can be handled by specialized agents, then synthesizes their outputs into coherent responses.
- How it works: Receives high-level tasks, breaks them down, delegates to appropriate specialized agents, monitors progress, aggregates results, and ensures overall task completion.
- Best Practices:
- Monitor agent overlap in terms of knowledge domain and action scope to prevent redundancy and confusion
- Avoid keeping highly similar agents separate, as this can degrade the performance of the orchestrator or intent classifier
- Refactor or group similar agents under a shared interface or capability to streamline classification and routing
- Introduce agent supervisors as the architecture scales across domains—these components help manage and abstract groups of related agents.
- Use hierarchical organization (e.g., supervisor 🡪 agent group) to maintain clarity, scalability, and ease of intent resolution.
Agent #1, #2, #3, #4 (with MCP Client)
- Specialized AI agents designed to handle specific domains, tasks, or capabilities. Domain specialization allows for deeper expertise and better performance in specific areas compared to general-purpose agents.
- How it works: Each agent focuses on a particular domain (e.g., finance, healthcare, coding) or function (e.g., summarization, research, creative writing), applying specialized knowledge, models, or techniques to user requests.
- Differences between Local and Remote Agents:
- Local agents run within the same environment as the orchestrator
- Remote agents operate across network boundaries
- Agent to Agent communication should be implemented by using specific standardized protocols such as A2A
- Remote agents require additional security and reliability considerations
- Communication patterns differ (in-memory vs. network protocols)
- Deployment and scaling strategies vary significantly
- Resource management approaches differ substantially
Conversation History
- A persistent store of user-agent interactions and conversation flows. It enables context-aware responses, supports learning from past interactions, and provides an audit trail of system behavior.
- How it works: Records each turn in a conversation, maintaining user inputs, agent responses, and associated metadata in a structured, queryable format.
Agent State
- Persistent storage of agent operational status, configuration, and runtime state. It enables continuity across sessions, recovery from failures, and adaptation based on past experiences.
- How it works: Maintains both static configuration and dynamic runtime state for each agent, allowing them to resume operations and maintain learned behaviors.
Registry Storage
- Specialized storage for the Agent Registry, maintaining agent metadata, capabilities, and operational history. It provides the persistent data layer for the Agent Registry, ensuring consistent agent information across system restarts and updates.
- How it works: Stores comprehensive information about each agent, including capabilities, endpoints, security credentials, performance metrics, and version history.
Integration Layer & MCP Server
- A standardized interface layer that connects agents to external tools, services, and data sources. It provides a consistent way for agents to access external capabilities without needing to implement custom integrations for each tool.
- How it works: Implements the Model Context Protocol (MCP) to expose tools as a standardized service that agents can discover and invoke.
3.2 Key Benefits
- Modularity and Extensibility: The modular nature of the architecture enables organizations to evolve their AI systems incrementally without disrupting the entire stack. New agents, whether focused on new domains or tasks, can be introduced seamlessly through agent registration and orchestration without requiring retraining or redeploying existing components.
- Domain Specialization: Instead of relying on a generalist model or single-agent to tackle all the users’ requests, each agent is purpose-built and fine-tuned to its domain-specific subject, rules and data. This ensures deeper accuracy, better alignment with requirements and mitigate more nuanced outputs.
- Scalability: The separation of roles and responsibility across orchestration, agents, knowledge and storage layer, to mention a few of the foundational layers, allows the system to scale horizontally across domains and use-cases. Agents can run locally, or the system can integrate with remote agents, and a supervisor can manage agent clusters as the number of specialized knowledges grows within the system. This enables enterprises to support hundreds of task-specific agents over time.
- Resilience: Failures in one agent do not cascade across the entire system and the orchestrator or agents’ supervisor can re-route, retry or fallback to other agents, making the system resilient.
4. Implementation of Multi-Agent Systems
When designing a multi-agent system, it is essential to begin with an internal assessment. This includes evaluating existing assets, the capabilities of the team(s), and, most importantly, the business scenarios that would benefit from such a system. While the allure of new technology is strong, especially in this rapidly evolving space, success hinges on aligning the system with a meaningful business use case. Without a clear return on investment (ROI), the project risks failure.
Many organizations have opted to build agent platforms on top of existing conversational systems, as chat-based interfaces are often the first application of Generative AI. Others have chosen to align with broader company strategies, such as Microsoft Copilot or Azure Foundry, either by building around these platforms or fully adopting their capabilities. This strategic decision is significant but beyond the scope of this paper.
Regardless of the path chosen, this document shares our experience implementing a multi-agent system and the challenges we encountered along the way. Our insights are applicable no matter what your architectural direction.
4.1 Architectural Models
A multi-agent system can be designed as either a monolith or a distributed system. Each approach involves trade-offs in performance, scalability, maintainability, team coordination, and operational complexity.
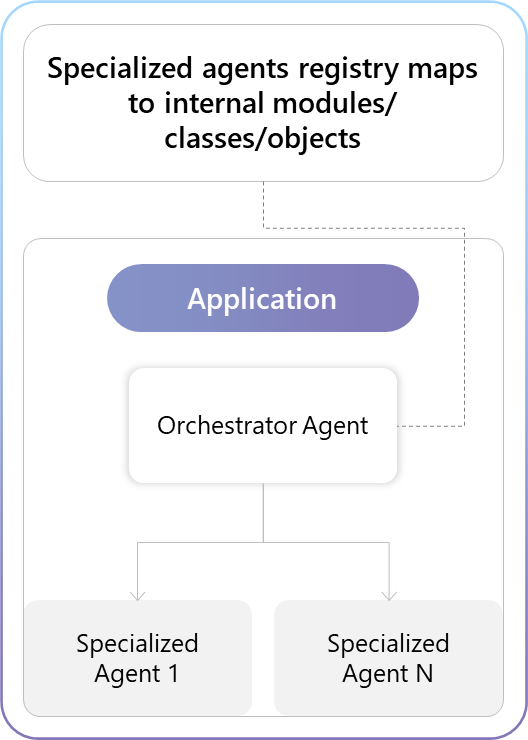
Modular Monolith
A self-contained application where the orchestrator and specialized agents are structured as well-defined modules. This approach favors simplicity, shared memory, and low-latency communication.
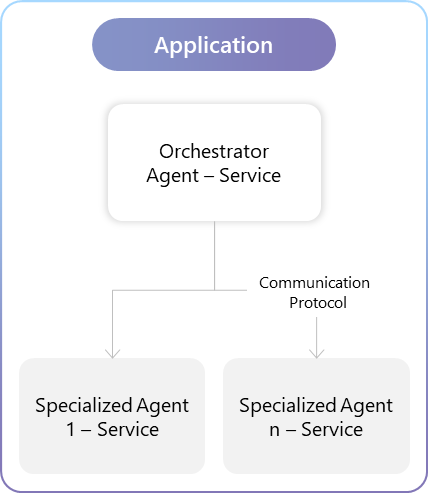
Microservices
A distributed architecture where each agent (or group of agents) is encapsulated as an independent service. This model supports independent deployment, granular scalability, and the flexibility to use diverse tools, frameworks, or programming languages.
System Evaluation and Governance
It is also critical to define how the system will be evaluated and to identify the components that directly influence its behavior. The same structured practices applied to individual agents—such as LLMOps, data pipelines, continuous evaluation, and CI/CD—should be extended to the system level to ensure robustness and alignment with business objectives.
As an example of how the different aspects of the system are connected and the impact it can generate, to illustrate let’s think about a Knowledge Base Agent that uses RAG (Retrieval-Augmented Generation). Usually, those agents use vector databases. The databases or indexes are populated by a different team in general, and changes on it can impact the behavior of our Knowledge Base Agent. When different changes happen, we lose track of the changes and their impact. Amplifying that for all the possible changes, the end user may have a broken experience. To avoid it, we suggest from the very beginning having a versioning strategy and ensuring that the production environment is sealed.
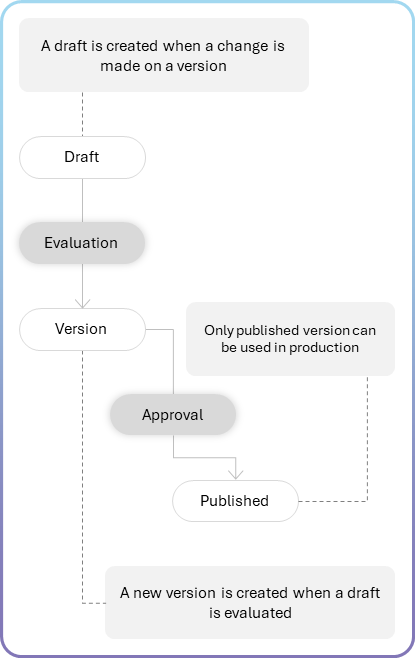
This is a suggestion for a state machine for agent’s versioning. OBS: Do not use the state field to track versions, versions are a different type of data.
Agent Registry and Orchestration
The central part of a multi-agent system is the Agent Registry. This service will be responsible for generating the metadata that describes the agent, validating if the agent is implementing the supported protocol(s). The registration process can happen in two ways:
- Registry-Initiated Agent Register: In a scenario where the Agent is available, and has a way to get the Agent Information, the register mechanism can make a request to the target agent URL to get the Agent Information. To implement this mechanism, the register mechanism needs to know where and how to request the different Agent Info endpoints
- Agent-Initiated Self Register: Alternatively, the register mechanism can be an API endpoint, where the Agents can register “themselves” into the registry. To implement this mechanism, the register mechanism needs to provide an endpoint where the Agents can reach to provide their Agent Information.
In a highly regulated market is hard to think about having a self-registration path, especially when there is also a route to onboarding external agents, there are ways to handle it, as using an approval workflow each use case will determine the most suitable option or both if this is the case.
Once the agents are registered, it is time to define the agent orchestration configuration, The Orchestrator Agent Service will use another metadata that describes the agents and their versions that compose the orchestrator. It basically defines the agents and their version, like a Docker compose configuration.
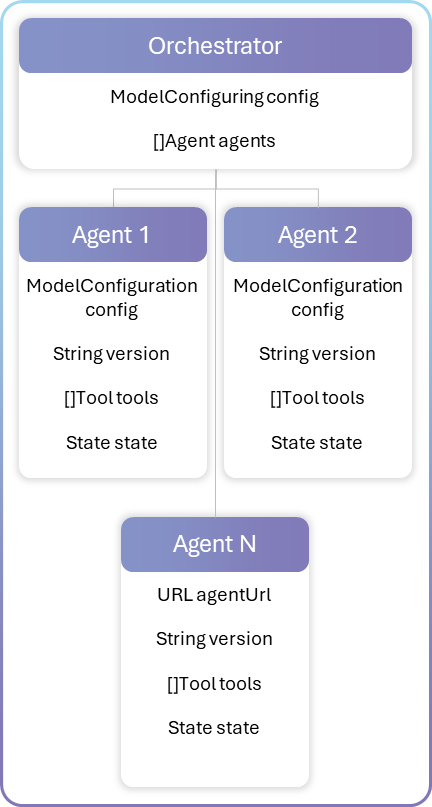
Just reinforcing that it is highly recommended to version the Orchestrator’s and the agent’s metadata, avoiding that any change impacts the user experience.
Operational Resilience
Operational resilience in a multi-agent system begins with observability. While this paper does not explore observability in depth, given the extensive coverage available elsewhere, it is important to acknowledge that without it, resilience cannot be achieved.
Assuming observability is in place, the next step is to define what should be measured and how the system should respond to ensure resilience. This includes monitoring agent health, detecting failures, and implementing recovery mechanisms.
Health checks are foundational. Agents must be monitored continuously, regardless of whether they are deployed locally or remotely. In the event of an outage or failure, retry strategies should be triggered automatically. These are common in resilient architecture and help maintain service continuity.
For Generative AI applications, additional considerations are required:
- Token consumption monitoring is essential to avoid unexpected cost spikes or degraded performance. Systems should track usage patterns and enforce thresholds or alerts.
- Fallback mechanisms must be in place to handle scenarios where token limits are exceeded, or model responses fail. This could include switching to a smaller model, using cached responses, or gracefully degrading functionality.
Resilience should also be considered across the entire agent’s lifecycle. This includes:
- Version control of agents and their dependencies
- Isolation of production environments to prevent unintended side effects
- Impact tracking for upstream and downstream changes (e.g., updates to vector databases used by RAG-based agents)
By proactively designing failure and recovery and ensuring that system behavior is observable, measurable, and actionable teams can build multi-agent systems that are robust, reliable, and aligned with business continuity goals.
References:
- Monitoring and Alerts: Azure AI Foundry includes built-in dashboards and integrates with Azure Monitor for tracking metrics (e.g., token usage, agent performance) and setting proactive alerts. Monitor Azure AI Foundry Agent Service – Azure AI services | Microsoft Learn
- Multi-Agent Reference Architecture
Security
Generative AI applications introduce a new set of security risks that go beyond traditional software systems. These include threats such as model hallucinations, prompt injection attacks, data leakage, and adversarial inputs designed to manipulate model behavior.
One particularly concerning vector is prompt injection, where malicious users craft inputs that alter the intended behavior of an agent or bypass safeguards. These attacks can be subtle and difficult to detect, especially in systems that rely heavily on natural language inputs.
At Microsoft, our team has been actively addressing these challenges through the work of the AETHER (AI and Ethics in Engineering and Research) committee. As part of this initiative, we developed a threat modeling framework tailored specifically for AI systems, which we apply across our development lifecycle. This framework helps identify and mitigate risks early, ensuring that security is embedded into the design of multi-agent systems.
We have also published guidance on secure deployment practices and responsible AI usage, which includes:
- Input validation and sanitization
- Role-based access control for agents and orchestration layers
- Logging and audit trails for agent interactions
- Isolation of sensitive data and model outputs
- Rate limiting and abuse detection mechanisms
While this paper does not cover the full scope of AI security, we strongly recommend integrating threat modeling and secure development practices from the outset. Security should not be an afterthought; it must be a foundational pillar of any GenAI system architecture.
- Token Quota Increases: Customers should request increased token quotas for Azure OpenAI models (e.g., GPT-4o, GPT-4o-mini, O-series) to avoid rate limits as usage scales.
- Regional Resource Deployment: Deploy multiple Azure OpenAI resources across different regions to handle API requests, reduce latency, and mitigate rate limits.
- Private Networking and Security: The Azure AI Foundry Agent Service supports private network isolation, enabling customers to securely host agents, integrate with user-managed identities, and enforce strict “deny-by-default” network rules. How to use a virtual network with the Azure AI Foundry Agent Service – Azure AI Foundry | Microsoft Learn.
Customer Use Cases
ContraForce
The following three case studies come from customer partnerships with the Microsoft AI Co-Innovation Labs, a global team of AI experts who co-build gen AI solutions that accelerate customers toward deployment. ContraForce, Stemtology, and SolidCommerce, built their multi-agent prototypes in the AI Co-Innovation Lab in San Francisco, where the lab team engineers bespoke gen AI solutions using multimodal, multi-agentic workflows optimized for Azure Cloud.

ContraForce provides MSSPs with a multi-tenant, multi-agent system running on Azure.
ContraForce is a cybersecurity software company delivering an Agentic Security Delivery Platform (ASDP) that enables Managed Security Service Providers (MSSPs) to operate at scale by automating the delivery of managed services for Microsoft Security applications across tens or even hundreds of customer environments. By centralizing tools such as Microsoft Sentinel and Microsoft Defender XDR into a unified, multi-tenant platform, ContraForce equips MSSPs with the infrastructure, workflows, and orchestration layers necessary to drive efficient, high-margin managed security services.
Instead of following the conventional model, where a single agent is hosted and operated by the software vendor, ContraForce adopted a multi-tenant, multi-agent system. This design allows MSSPs to instantiate dedicated, context-aware agents for each managed tenant and customer, with each agent grounded in tenant-specific context and workflows. These agents act as virtual security service delivery analysts, autonomous extensions of the MSSP’s team, tailored specifically to the context, workflows, and service-level requirements of each customer. ContraForce abstracts away the complexity of agent orchestration, coordination, and hosting. MSSPs do not need to manage AI infrastructure themselves; they simply define the service intent and requirements per customer. ContraForce handles the rest.

ContraForce ASDP: A multi-tenant, multi-agent system
When ContraForce evaluated Microsoft’s AI Agent Service in its preview phase, the highly scalable and multi-tenant-friendly architecture aligned perfectly with this model. It enabled ContraForce to deploy independent, intelligent agents that operate in isolation in each customer’s environment while remaining part of a coordinated, shared framework. This capability made it possible to deliver consistent, high-quality security automation across diverse customer environments without introducing operational bottlenecks or risking service degradation. Coordinated by a central orchestration layer, the multi-tenant, multi-agent system provides the foundation for an ecosystem of specialized agents, with some focused-on detection, others on response, and others on preserving institutional knowledge.
In less than a month, ContraForce launched a prototype of the first multi-tenant Service Delivery Agent purpose-built for MSSPs. This Service Delivery Agent for Microsoft Security automates alert triage, incident investigation, malicious intent determination, and guided response execution using proprietary ContraForce Gamebooks.
The Service Delivery Agent has allowed MSSPs to manage 3 times more customers per analyst, double incident investigation capacity, and unlock new business models without the need for dedicated security and AI engineering teams. For ContraForce, it has also validated that applying multi-agent AI systems through domain-specific workflows, user interfaces, and service logic is key to transitioning AI from the lab into real-world professional services; and given us a clear sightline to achieve our projected 300% year-on-year top-line growth.
Stemtology uses AI to Treat Osteoarthritis

This case study is a reprint of an original story from the Microsoft AI Co-Innovation Labs.
The biggest benefit of working with the Microsoft AI Co-Innovation Labs was being able to rapidly reach POC and begin testing. We were able to quickly design with engineers from the Lab team, create infrastructure for efficient data cleaning, and coordinate seamlessly to build something out that would have taken our team ~3 months in a matter of weeks.”
– Annalina Che, CEO, Stemtology
Regenerative medicine is a quickly evolving field that promises therapies for previously incurable diseases and helps advance medical research. Stemtology is an innovator in this critical space, accelerating effective disease treatments with AI-driven technologies. Their AI platform integrates large language models (LLMs) and graph neural networks (GNNs) to hypothesize, simulate, and optimize treatment plans for inflammatory, immune, and degenerative diseases.
Stemtology’s work addresses known limitations in their industry, like slow experiment times, siloed research publishing, and overwhelming data complexity. Even as they address these challenges, the Stemtology team needed to partner with the “best of the best”1 to build a scalable prototype and get backend support on a solution in Azure.
They partnered with Microsoft AI Co-Innovation Labs to build a generative AI solution that could find and analyze medical research data and generate treatments for osteoarthritis, with a plan to apply this solution across other diseases later.
In the Lab
Our AI Co-Innovation Lab team in San Francisco brought our extensive experience in building gen AI prototypes using Microsoft Azure and AI technologies to collaborate on a multi-agent research and development solution.
The Lab team leveraged Azure OpenAI GPT and Azure Cognitive Search for data processing, hypothesis generation, and validation. They also used their extensive knowledge of cutting-edge Microsoft technologies to use the brand-new Azure AI Agent Service, empowering Stemtology with a more powerful and scalable agentic AI.
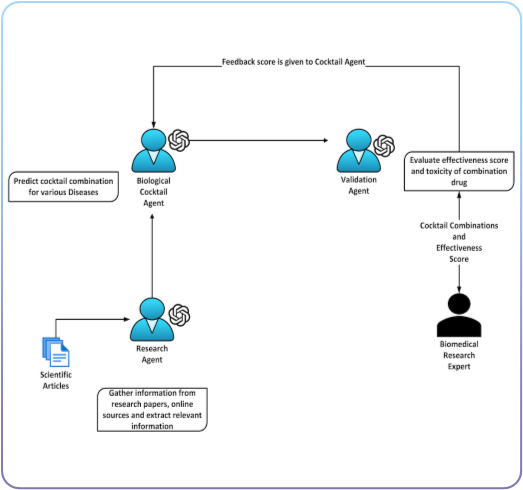
Stemtology Agents Workflow
The first set of agents act as research assistants, searching for medical studies from the PubMed database and pulling that data for insights and reports. The next agent takes that research and generates osteoarthritis treatment plans based on disease-specific research studies that the science team can then analyze and test.
This solution integrates directly into Stemtology’s business model, acting as a research and development engine and working in tandem with scientists in the lab team to accelerate design, testing, and optimization of synthetic cell therapies.
Solution Impact
Stemtology is already seeing the benefits of their solution with their science team, including significant operational cost savings and reduced time spent on labor-intensive tasks like reading and analyzing research papers. As a result, scientists can shift their focus to higher-level design tasks and explore other disease treatments.
In deploying the solution, Stemtology expects to achieve even greater outcomes:
- Cut experimental timelines by up to 50%
- Achieve ≥90% predictive accuracy for treatment outcomes, ensuring feasible and effective therapeutic solutions
- Scale the solution to manage over 100 diseases
- Improve regenerative outcomes for each disease treated
This advanced application of gen AI positions Stemtology as a leader in regenerative medicine, offering transformative benefits for healthcare providers, researchers, and patients by accelerating drug discovery and improving access to personalized treatments.
By collaborating with our team of experts in the AI Co-Innovation Labs, Stemtology can realize and scale this solution with the power of agentic AI in Azure.
Quoted from Annalina Che, CEO, Stemtology.
Use case 3: SolidCommerce
SolidCommerce: AI Solutions for the Retail Industry
SolidCommerce specializes in providing artificial intelligence solutions tailored specifically for the retail industry. The company focuses on leveraging AI and machine learning technologies to help retailers optimize operations, enhance customer experiences, and drive sales growth. By utilizing data-driven insights, SolidCommerce empowers retailers to make informed decisions and maintain a competitive edge in the market.
Mission:
SolidCommerce’s mission is to enable retailers to unlock the power of AI and machine learning to streamline operations, improve customer engagement, and achieve sustainable growth. Through innovative solutions, they aim to transform the retail landscape and help businesses thrive in a rapidly changing environment.
Key Features of SolidCommerce’s Offerings:
- Predictive Analytics for Inventory Management: SolidCommerce provides tools that enable retailers to forecast demand, optimize stock levels, and reduce costs. By analyzing large datasets, their predictive analytics platform helps retailers make informed decisions about inventory, supply chain, and pricing strategies.
- Customer Behavior Analysis: SolidCommerce’s solutions analyze customer interactions and behaviors to uncover actionable insights. This enables retailers to better understand their audience and adapt strategies to improve satisfaction and loyalty.
- Personalized Marketing Strategies: By segmenting customers based on preferences, behaviors, and purchase history, SolidCommerce helps retailers deliver tailored promotions and product recommendations. These personalized interactions enhance the shopping experience and contribute to increased sales.
SolidCommerce’s focus on integrating AI-driven technologies with retail processes ensures businesses can efficiently adapt to evolving market trends, optimize their operations, and create meaningful customer experiences. By helping retailers harness the power of data, SolidCommerce is shaping the future of the industry and driving growth for businesses of all sizes.
AI use case
SolidCommerce: AI-Powered Merchant Assistance Platform
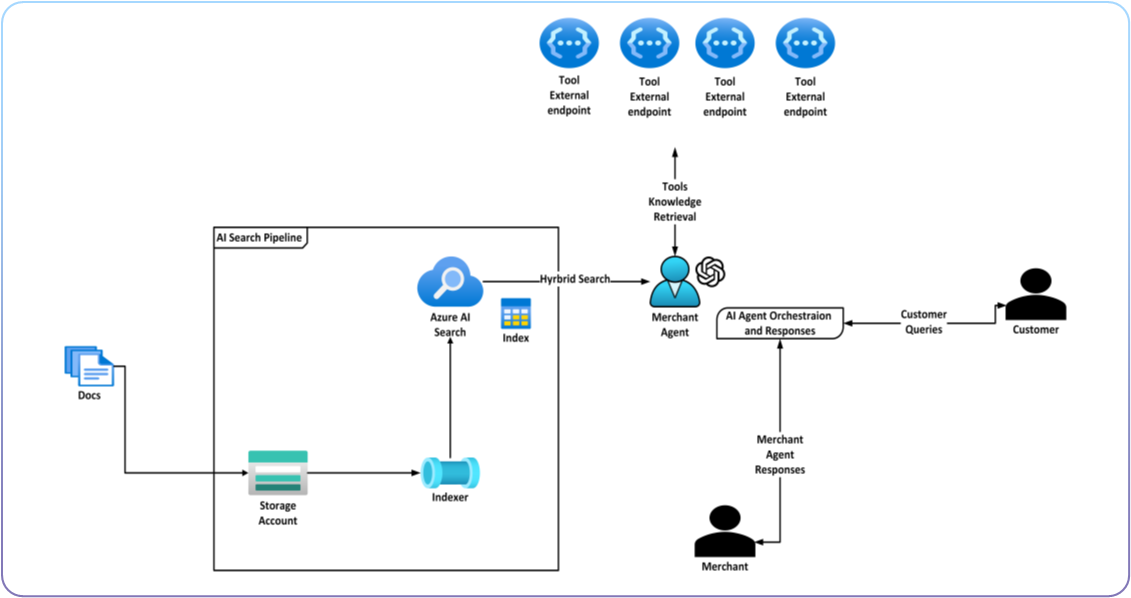
SolidCommerce is developing an AI Agent-powered platform designed to assist merchants in efficiently responding to customer inquiries. The platform leverages Azure Blob Storage, Azure AI Search, and Function Apps to retrieve and process data from multiple sources, ensuring accurate and context-specific responses. By automating data retrieval, response generation, and merchant approval workflows, this system improves productivity while maintaining high response relevance and accuracy.
Our first AI innovation
The first AI innovation is a multi-modal merchant assistance platform for Managed Data Retrieval and Response Generation. The platform integrates multiple Azure AI services to:
- Retrieve data from various sources, including product listings, shipment tracking, and merchant policies
- Generate responses to customer inquiries using AI Search and vector embeddings for contextual grounding
- Enable merchant approval workflows to ensure responses align with business policies before being sent
Development Approach
The merchant assistance platform is being developed using Azure cloud technologies, leveraging cutting-edge AI capabilities and services to enable seamless data integration, intelligent processing, and scalable workflows. The platform incorporates:
- Azure Blob Storage: Files containing product and order data are uploaded and indexed.
- Azure AI Search: Indexer processes the data to create embeddings, enabling efficient vector and keyword search capabilities.
- Function Apps: APIs provide real-time data retrieval, such as shipment tracking, order details, and merchant policies.
- Azure AI Agent Service: The AI agent orchestrates these services to, Query indexed data for precise information retrieval. Process customer inquiries and generate draft responses grounded in reliable data sources. Filter search results and tailor responses by sales channel (e.g., eBay, Amazon).
Value and Impact
The SolidCommerce AI platform is designed to empower merchants by:
- Improving efficiency: Automates data retrieval and response generation, reducing the time required for customer service tasks
- Enhancing accuracy: Combines vector search and keyword search for precise, contextually relevant responses
- Scalability: Supports multiple companies with separate indexes and sales channel-specific filtering
- Streamlining workflows: Enables merchant review and approval of AI-generated responses to ensure compliance and quality
Architecture diagram
Conclusion
For technical architects and developers scaling generative AI across the enterprise, the limitations of single-agent systems have become increasingly evident. While useful for rapid prototyping, these early architectures quickly become rigid, difficult to govern, and incapable of meeting enterprise demands such as cross-domain intelligence, evolving toolchains, and strict compliance and security standards.
Multi-agent architecture presents a scalable, resilient, and future-ready foundation for building enterprise-grade AI systems. By distributing responsibilities across specialized agents, each with its own model, tools, and memory and coordinating their actions through a central orchestrator, organizations gain modularity, improved fault tolerance, and clearer separation of concerns. This approach not only aligns with established software engineering practices but also enables better interoperability with existing enterprise systems and APIs.
Critically, multi-agent systems enhance observability, auditability, and compliance, enabling enterprises to enforce policies, monitor performance, and maintain governance at scale. They also support human-in-the-loop collaboration, where agents can augment, rather than replace, human expertise, especially in high-stakes domains.
From a strategic perspective, this architectural shift empowers enterprises to retain domain-specific knowledge within agents, optimize computational costs by dynamically allocating workloads, and accelerate time-to-value through reusable, composable agent patterns. Over time, agents evolve into intelligent components that encode institutional memory, providing sustained business differentiation.
Ultimately, adopting a multi-agent platform is more than a technical evolution it’s a long-term investment in building adaptive, compliant, and intelligent systems that can scale with business needs, deliver tangible value, and evolve alongside enterprise priorities.
0 comments
Be the first to start the discussion.