

Embeddings and vectors are becoming common terms not only for engineers involved in AI-related activities but also for those using databases. Some common points of discussion that frequently arise among users familiar with vectors and embeddings include:
- How can I quickly “vectorize” the content already present in my database? (this post)
- How can I keep the vectors updated whenever there is a change to the content from which they have been generated?
- What if I have more than one column that I would like to use for generating embeddings?
- Are there any best practices for storing and querying vectors in modern relational databases?
Let’s tackle each one of these questions one by one starting from the very first. In the next blog posts I’ll discuss about the other questions.
Quickly vectorize existing data
This is a straightforward question. While the answer is often “it depends,” in this case, there is a clear and direct solution: to efficiently vectorize data, batching requests is essential. The OpenAI API—and by extension, the Azure OpenAI service—supports receiving an array of strings for vectorization, thereby minimizing REST call overhead:
https://platform.openai.com/docs/api-reference/embeddings
The OpenAI API is rapidly becoming the standard, so it is highly likely that even if you plan to use your own model with an on-premises inference server, batch support for embedding processing is also available. For instance, Ollama already supports this feature:
https://github.com/ollama/ollama/blob/main/docs/api.md#generate-embeddings
Having established the optimal strategy, how can it be implemented? Several options exist, ranging from Azure Data Factory to Apache Spark. Essentially, any tool capable of reading from Azure SQL, batching requests, and making REST calls is suitable.
Parallelize and scale
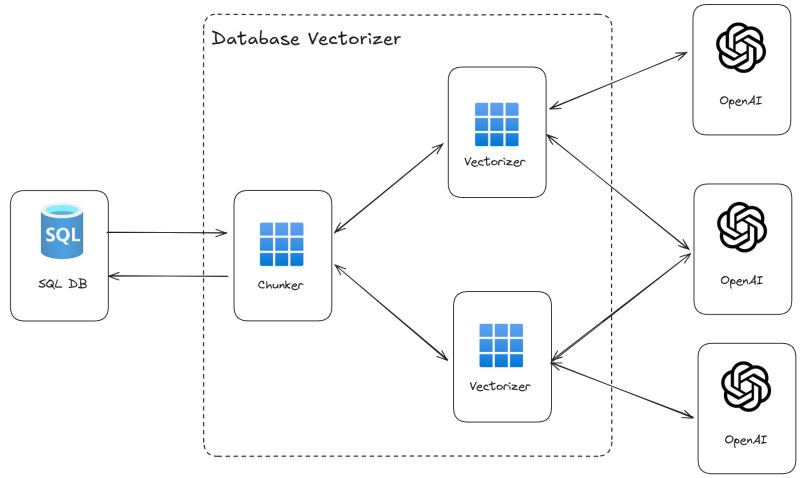
However, turning text into embeddings at scale presents complexities. For instance, if the text to be vectorized is too lengthy, it must be chunked to ensure the generated embeddings accurately represent the underlying concepts. Additionally, embedding models may have inherent limitations, such as restrictions on the amount of text (in terms of tokens) that can be vectorized simultaneously.
To address these limitations and enhance scalability, one option is to scale out by deploying multiple embedding models in parallel. By distributing arrays of text to different models simultaneously, the solution can easily be scaled by adding more instances of the desired embedding model.
A working example
At a certain point, I was required to vectorize approximately 10 million rows of text and needed to complete this task as efficiently as possible. Therefore, I developed a sample to facilitate all the necessary processes. To ensure maximum customization and adaptability to various scenarios, I opted to use .NET and implemented everything from scratch utilizing the ConcurrentQueue class, which supports scaling out and parallelism to the greatest extent possible.
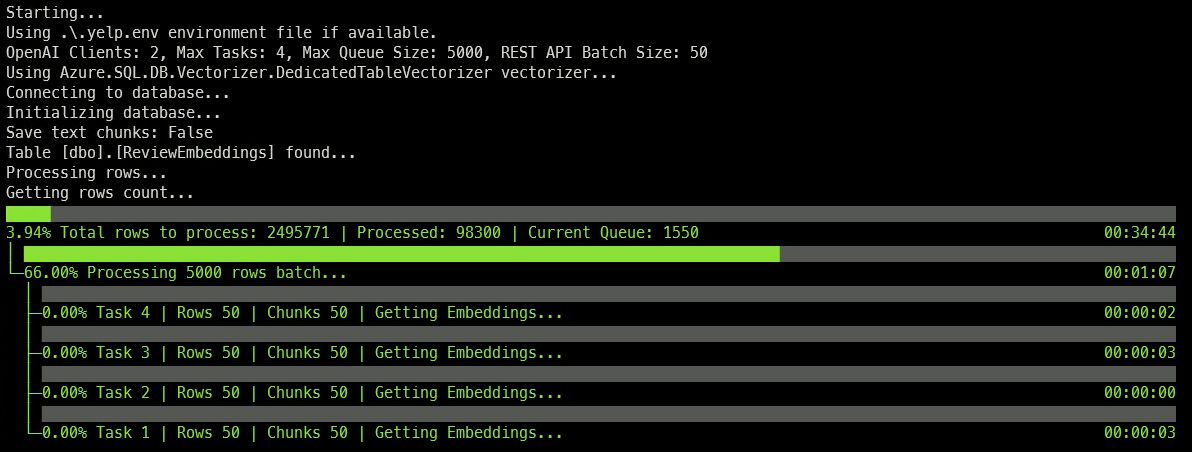
The sample – that can be used as a standalone tool if you don’t need any custom behavior, otherwise feel free to contribute to it 🙂 – is available on GitHub:
https://github.com/Azure-Samples/azure-sql-db-vectorizer
The reason why vectorized data is stored in a dedicated table will be explained in the next blog post. Stay tuned!
Thanks Davide for the prompt response and support! – I opened an issue in the repo as suggested.
Hi Davide,
Thank you very much for your amazing working examples. I have been following your articles and am eager to get a proof of concept (POC) up and running to search and interact with our data stored in a SQL database. I plan to try your latest example, but I am struggling to get your previous example (azure-sql-db-session-recommender-v2) up and running. Specifically, I am encountering an issue where the 'json_array_to_vector' function is not recognized as a built-in function.
Could you please update the repository to reflect how it is currently working live at https://ai.microsofthq.vslive.com/? I have also reported this issue...
Thanks a lot for bringing this up, I just fixed the code that I completely forgot to update. Thanks and enjoy, and make sure to check out the latest samples here (AI search powered too! :)) : https://ai.awesome.azuresql.dev/
Hi Devide,
It is so exciting to go through the working examples. As Mohammad mentioned in the other conversation, I was trying to get the Azure SQL DB Session Recommender(V2) up and running for PoC purposes. However, I'm encountering a 'runtime version' error, and none of the functions are getting deployed.
I tried fixing the runtime error by updating the code to use the 'dotnet' runtime instead of 'dotnet-isolated'. Although this fixed the runtime version error, it still didn't create functions in the function app, nor is it connecting to the static web app.
I'm wondering if you have any quick solution suggestions...
Hi, using the “dotnet-isolated” is the recommender runtime for Azure Functions…so it should work just fine. Can you please open an Issue in the repo so that we can move the conversation there (so that it will be easier for other to chime in end help if needed) Thanks!
Thank you very much Davide for the prompt response. I will try it and let you know.
Unfortenatly the link https://ai.awesome.azuresql.dev/ is not working for me.
Uh…I just checked and the website seems to be working fine. Maybe can you check again? Anyway, the repo for the sample is here: https://github.com/yorek/azure-sql-db-ai-samples-search. You can run the sample offline (on Azure SQL needs to be in the cloud)