

Hey Azure SQL enthusiasts! 👋
We had a hiring event last week, and as I was going through a stack of digital resumes, I thought, “There has to be an easier way to do this.” That’s when it hit me—why not use Azure SQL DB’s new vector data type to revolutionize our hiring process? Not only could we find the perfect candidate faster, but we could also identify key focus areas for the interview. It’s a win-win!
So, buckle up because today, we’re diving into how Azure SQL DB’s vector capabilities can enable advanced resume matching. We’ll be using Azure Document Intelligence and Azure OpenAI to make this magic happen. Let’s get started!
The Challenge: Finding the Perfect Candidate
Imagine you’re a recruiter with a stack of digital resumes taller than your inbox. You need to find candidates with specific skills and experiences, but manually reviewing each resume is time-consuming and prone to errors. You also need to know what focus areas to address in the interview if a candidate is a match but has some missing skills. What if there was a way to automate this process, ensure you never miss a great candidate, and make your interview process better? Enter Azure SQL DB’s native vector capabilities!

The Solution: Vector Similarity Search
By leveraging Azure SQL DB’s new vector data type, we can store embeddings (vector representations) of resume content and perform similarity searches using built-in vector functions. This allows us to match resumes to job descriptions with incredible accuracy. Here’s how we do it:
Getting Started
For the purpose of this sample tutorial, we’ll use a simple Python notebook so that you can have everything up and running in less than 2 hours. Here’s a quick overview of what you’ll need to get started:
Dataset
We use a sample dataset from Kaggle containing PDF resumes for this tutorial. For this tutorial, we will use 120 resumes from the Information-Technology folder
Prerequisites
- Azure Subscription: Create one for free
- Azure SQL Database: Set up your database for free
- Azure Document Intelligence Create a Free Azure Document Intelligence resource
- Azure OpenAI Access: Apply for access in the desired Azure subscription at https://aka.ms/oai/access
- Azure OpenAI Resource: Deploy an embeddings model (e.g., text-embedding-small or text-embedding-ada-002) and a GPT-4.0 model for chat completion. Refer to the resource deployment guide
- Azure Data Studio: Download here to manage your Azure SQL database and execute the notebook
Step 1: Extract & chunk content from PDF Resumes
First, we use Azure Document Intelligence to extract and chunk content from PDF resumes.
Why Azure Document Intelligence?
AI Document Intelligence is an AI service that applies advanced machine learning to extract text, key-value pairs, tables, and structures from documents automatically and accurately. This means you can turn documents into usable data and shift your focus to acting on information rather than compiling it.
Here is an example of a Resume in PDF format from the dataset:

One of the best parts about using Azure Document Intelligence is how easy it is to get started with prebuilt models. These models are designed to handle common document types like invoices, receipts, and more! Here’s why you’ll love using them:
- No Training Required: Prebuilt models are ready to use out of the box & like having a team of document experts at your disposal. You don’t need to spend time training them on your data.
- High Accuracy: These models are built and maintained by Microsoft, ensuring high accuracy and reliability.
- Easy Integration: With simple API calls, you can integrate these models into your applications quickly and efficiently.
- Scalability: Azure’s infrastructure ensures that your document processing can scale with your needs, handling everything from a few documents to millions.
We define DocumentAnalysisClient to send requests to the Azure Document Intelligence service and receive responses containing the extracted text from the PDF resumes. It provides operations for analyzing input documents using prebuilt and custom models through the begin_analyze_document and begin_analyze_document_from_url APIs.

You can also visualize how the document text extraction is performed using the Document Intelligence Studio

Why are we chunking?
When dealing with content that exceeds the embedding limit of our model, we need to break it into smaller pieces. This is because the model that generates embeddings can only handle a certain amount of text at a time.
Here, we divide the extracted text into fixed chunks of 500 tokens. These chunks are later passed to the text-embedding-small model to generate text embeddings, as the model has an input token limit of 8192
This process breaks down resumes into manageable pieces, making them easier to analyze and process. Think of it as turning a giant pizza into bite-sized slices—much easier to handle!
Note: There are different ways of chunking content, and the method you choose can depend on your specific needs and the structure of the text you’re working with.
We now have our Resumes extracted & chunked:

Step 2: Generating Embeddings
Next, we generate embeddings from the chunked content using the Azure OpenAI API. These embeddings are vector representations of the text, capturing the semantic meaning of the content.

Each chunk now has a text embedding as seen below:

Step 3: Storing Embeddings in Azure SQL DB
We then store these embeddings in Azure SQL DB using the new Vector data type. This allows us to perform similarity searches using built-in vector functions, enabling us to find the most suitable candidates based on their resumes.
We now have our data in the SQL DB which we can use for Vector Search. This means that even if the exact words don’t match, the underlying meaning can still be understood and matched effectively.
For example: If your search query is focused on project management skills, the embeddings can help find candidates with relevant experience, even if they use different terminology:
Search Query: “project management”
Matched Candidate Skills:
- “Led multiple software development projects”
- “Certified Scrum Master with experience in Agile methodologies”
- “Managed cross-functional teams to deliver projects on time and within budget”
The embeddings capture the essence of “project management” and match it with various related skills and experiences. It’s like having a supercharged recruiter at your fingertips!
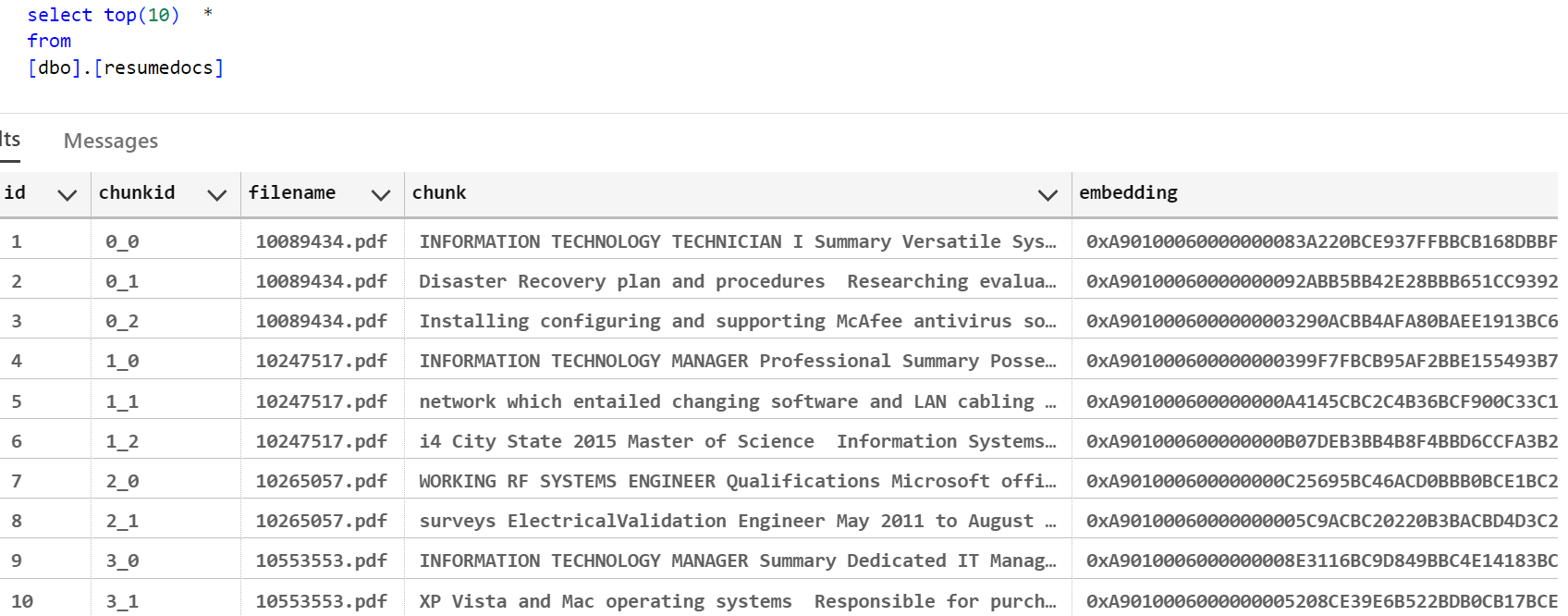
Let’s now query our ResumeDocs table to get the top similar candidates given the User search query.
Vector Search in SQL DB: Given any user search query, we can obtain the vector representation of that text. We then use this vector to calculate the cosine distance against all the resume embeddings stored in the database. By selecting only the closest matches, we can identify the resumes most relevant to the user’s query. This helps in finding the most suitable candidates based on their resumes.
The most common distance is the cosine similarity, which can be calculated quite easily in SQL with the help of the built-in vector distance functions.
VECTOR_DISTANCE(‘distance metric’, V1, V2)

Step 4: Augmenting LLM Generation
Finally, we enhance language model generation with the Vector Search results from our Azure SQL Database. By informing a GPT-4o chat model with the results of our Vector search, we can provide rich, context-aware answers about candidates based on their resumes.
The function generate_completion is defined to help ground the gpt-4o model with prompts and system instructions. Note that we are passing the results of the vector_search_sql we defined earlier

We can now create interactive loop where you can pose questions to the model and receive information grounded in your data.
 Let’s look at Candidate 2:
Let’s look at Candidate 2:


We also can get a short summary at the end along with a Fun Microsoft fact about the technology we are hiring for as we had defined in the prompt:

Hence by utilizing Azure SQL DB’s vector capabilities along with the power of Azure Document Intelligence and Azure OpenAI, you can totally transform your hiring game.
No more missing out on the perfect candidate, and your interviews will be more on point than ever. But why stop at resumes? Dive into your own documents—whether they’re project reports, research papers—and uncover hidden gems. This cool approach not only saves you time but also boosts the quality of your recruitment and document analysis. Happy exploring and hiring! 🚀
Private Preview Sign-up
We are currently accepting requests from customers who would like to participate in the private preview and try out the Native Vector Support for SQL feature. If you are interested, please fill out https://aka.ms/azuresql-vector-eap

i have applied for preview feature and still i didnot get any response. please let us know when we will get access to this preview feature in our subscription
Hi Naga. Please drop me an email at pookam@microsoft.com
Excellent article and a good choice of Use Case.