

As a developer, I often attend conferences to learn new skills and network with other professionals. However, conferences can be overwhelming, especially when they offer dozens of sessions on different topics. How can I decide which ones are worth my time and attention?
That’s why I decided to use OpenAI to create a tool that can help me find the most relevant sessions for my interests. I used the session abstracts of a conference as input and converted them into embeddings using OpenAI’s natural language processing capabilities. Then, I used vector search to compare the embeddings with a query topic and rank the sessions by similarity.
This way, I can quickly and easily discover the sessions that match my goals and preferences, without having to read all the abstracts manually. I built this tool in a couple of hours during the weekend, using simple, scalable, and fast technologies.
Here’s how I did it. I hope you’ll find it useful.
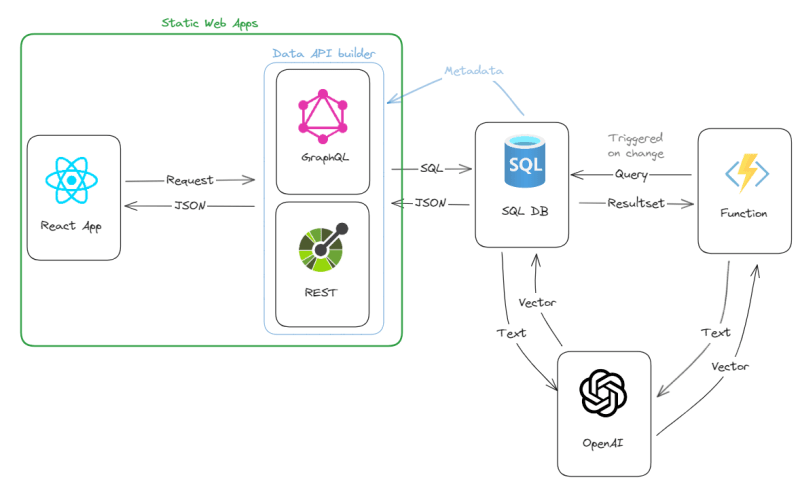
The Architecture
The entire solution is a mix of fullstack, jamstack to be more precise, and event-driven architecture pattern.
Sessions’ data, which is structured by nature, is saved into a relational database and the tables and stored procedures are made available to the fronted via REST and GraphQL.
Each time a new session is added, a serverless function is executed to turn abstracts into a vector by using OpenAI model via a REST call.
A (minimal) web frontend allows end users to type a text that will also be converted into a vector using OpenAI and then the most similar vectors – and thus the associated sessions – will be found using cosine similarity.
That’s all. Simple, easy, elegant, and scalable: the architecture I love.
Implementation Details
I used Azure for everything. Thanks to the various free and trial offers it is possible to create such a solution completely for free.
The Frontend
I used Azure Static Web Apps to host the fronted, written using React. Simple, well-known and easy to create. I’m new to React, so using this project was an effective way to ramp-up my skills while doing something funny and cool at the same time. I’ve learned a lot around the ecosystem around it (for example react-router-dom, vite) and the way it works internally.
Azure Static Web Apps provides a fantastic on-prem development experience, and it is heavily integrated with GitHub, so that deployment is just a push to the target repository. Kind of obvious choice.
The Backend
Azure Static Web Apps comes with a cool feature named Database Connections that does a lot of heavy lifting for you. It automatically takes the database objects you configure and make them available via GraphQL and REST.
Database Connections is powered by Data API builder, which is open-source and available also on-premises. It is heavily integrated with Static Web Apps, and the on-prem development experience that they provide is honestly unmatched. I was able to do everything on my machine with no friction at all, no CORS worries, authentication provider emulation, integration with vite tools…it is absolutely amazing! Same as for the frontend, the deployment to Azure is done via a simple git push.
The Database
I used Azure SQL database. It now has a free offer, and it can easily scale to terabytes of data if needed. Not that I think I need a terabyte of data for now…but you never know 🙂
About vectors
Azure SQL database doesn’t have a native vector type, but a vector is nothing more than a list of numbers. Relational databases are in general pretty good at managing list of things (otherwise known as sets 😊, otherwise known as relations 😁) efficiently.
With a dataset the size of the one I’m using, doing a full scan of all available vectors is desirable approach, as it performs exact nearest neighbor search, which provides perfect recall. There is no need to specialized indexes, so Azure SQL looks like a great choice.
In fact, even if the amount of data is not huge, is not insignificant either. OpenAI text embeddings return a vector with 1536 (float) values, so even with just 100 sessions to store the number of calculations to do in order to compute the cosine distance quickly approaches hundreds of thousands, and they should be done in the quickest way possible to accommodate as many requests per second as possible.

Azure SQL uses vector calculations internally (SIMD and AVX512 CPU instructions), to speed up operations on sets of data, and offers a columnstore index that can make operations on sets of data even faster. Not that a columnstore would be really needed for the small amount of data I have, but I wanted to give it a try to see how it would perform. And you’ll see that the performances are great. The CPU usage is minuscule, and vector search is done in less than 50 msec on 100 of session abstracts. Impressive performance, and I don’t have to install, manage, and integrate another database or a third-party library. Perfect: simplicity for the win!
If you want to dig more into in doing vector search with Azure SQL, read the Vector Similarity Search with Azure SQL database and OpenAI article.
OpenAI integration
Finally, I wanted to keep the solution as simple as possible and as efficient as possible, so I wanted to use the new capability of Azure SQL to call a REST API directly to call OpenAI directly from inside the database to convert the searched text into a vector.
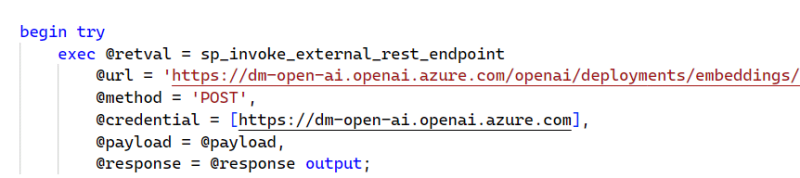
By doing it inside the database, I don’t have to create yet another Azure Function just for the purpose of calling the OpenAI REST endpoint and then storing the resulting vector in the database. This approach is something I can switch to in case I need more scalability, but there is no proof that such additional scalability is needed right now, so I decided to start with a simpler architecture.
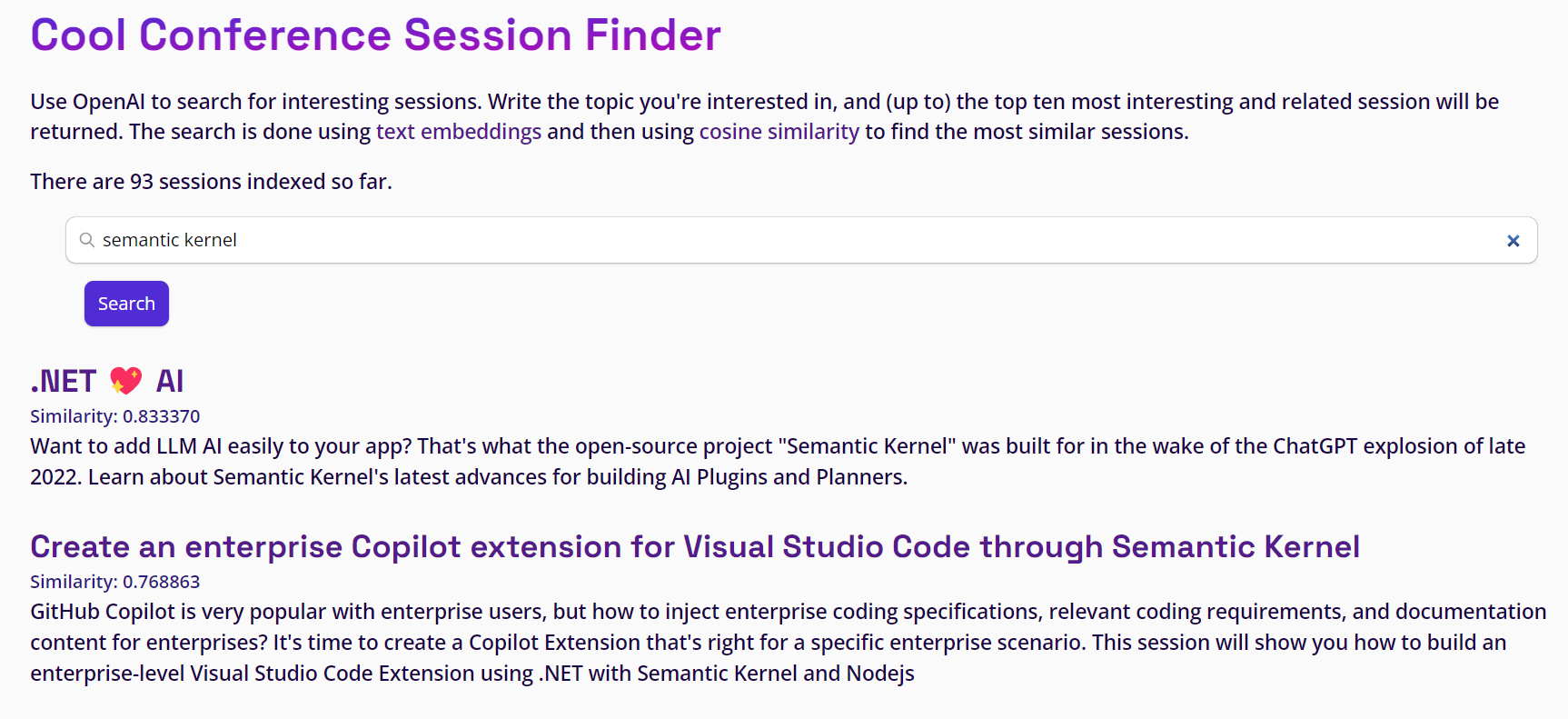
The Result
The result is here for you to test out, which is something it will not only be interesting but also helpful if you plan to attend the .NET Conf 2023. In fact, I populated the database of the published sample solution with their session abstracts.
I spent more or less one hour building everything, mostly on React and the frontend side. Creating the database and publishing it as REST endpoint took probably no more than 10 minutes. 😍
Try it out yourself here:
https://aka.ms/dotnetconf2023-session-finder
Of course, the OpenAI calls are limited (I’m using the smallest tier) so you might see throttling happening. Please be patient or deploy everything in our subscription to try it out yourself, using the code available here:
https://github.com/azure-samples/azure-sql-db-session-recommender
Excellent article! Great example of using Azure SQL (SQL engine) as a very viable data store for search embeddings.