

I’ve just finished watching the video from the @GuyInACube about Common Table Expressions
and I noticed that in several comments there was the request to explain what is the difference between Common Table Expressions, Views and Temp Tables.
This is quite a common question, and it is time to give it a simple, concise, and clear answer, once and for all.
Common Table Expressions
You can think of a Common Table Expression (CTE) as a table subquery. A table subquery, also sometimes referred to as derived table, is a query that is used as the starting point to build another query. Like a subquery, it will exist only for the duration of the query. CTEs make the code easier to write as you can write the CTEs at the top of your query – you can have more than one CTE, and CTEs can reference other CTEs – and then you can use the defined CTEs in your main query.

CTEs make the code easier to read, and favor reuse: imagine that in each CTE you are defining the subset of data that you want to work on in the main query and you are giving it a label. In the main query then you can just refer to that subset by using its label instead of having to write the whole subquery.
CTEs also allows for some complex scenarios like recursive queries.
Views
Views are metadata objects that allow to save the definition (and the definition only, not the result!) of a query and then use it later by referencing its name. To quote the book I wrote couple of years ago: “A view is nothing more than a query definition, labeled with name, and usable as a table. In fact, views are also known as virtual tables, even if this name is seldomly used”
Temp Tables
Temporary tables are regular tables that must start with # character (or ## for global temporal tables), and on which the query engine can do some special optimization knowing they are ephemeral, that will be automatically dropped once going out of scope (for example, when the connection that created them is terminated).
Temporary tables have no special relationships with queries: you can simply take any query result and save it into a temporary table using, for example, the SELECT INTO command.

Once the SELECT INTO command is finished, the relationship between the query that produced a result set and the temp table that has been used to store that result set is concluded. Think of it as a very simple ETL process. Once it is finished there is nothing that will automatically update or keep in sync the data in the temp table with the result set generated by the query used to move data into the temp table.
When to use what?
Let’s start simple
Let’s say you have a complex query, where you must put together several different tables to produce the result set you need.
👉 The first thing that is important to keep in mind, that Subqueries, Views and CTEs are all conceptually the same for the query engine. SQL is declarative language where – unless there are some precedence constraints imposed by the operator used – everything is evaluated “all-at-once”.
It means that there is no guarantee that a subquery (or a CTE or a view) will be executed before the query that uses it.
This is a super important concept to grasp. It might sound strange to you, but this is a key feature of SQL as the query optimizer can decide – as long as the final result will be correct – to apply filters and optimization wherever is more appropriate.
Let’s say, for example, that you have a subquery that filters all people that live in Seattle. On this subquery you want to add an additional filter to limit the result set only to return people that are named Davide.
👉 Thanks to the fact that SQL is “all-at-once” the optimizer can push the outer filter down to the inner subquery and immediately search for all those people who live in Seattle and are named Davide.
If SQL hand’t been “all-at-once”, the database engine would have had to first execute the query and then search among the resulting rows for only those for which the name is Davide.
That would have been an incredible waste of resources – more CPU and memory used – and would have provided a much worse performance result.
In addition to that, it would also make index usage much more complex and less likely. If we had an index on the people’s name, it would be useful only if we could filter first by name and then by city. Luckly the optimizer can move the filters around, given that the query simply states what you want and not how to get it. If we had, instead, to firstly execute the subquery and then the outer query, well…you can guess that the index wouldn’t have been that useful, right?
Let’s complicate things a bit
So far, from what has just been explained, it seems that using a subquery, a view, or CTE is always a clever idea as we’re just allowing the query optimizer to do its work at best.
On paper yes. In practice, we have to take into account that the query optimizer doesn’t really know exactly what values are contained in each table and how data is distributed. Does it have a normal distribution? Or is skewed toward some specific values?
🚗 You can think of the query optimizer as your car navigation system. When it plans for a route, it will do so considering the most up-to-date and accurate information about traffic…but you won’t be 100% sure that the road it tells you to drive will be the best choice until you are there. What if there has been a sudden surge in traffic for whatever reason? Well, you’re there now and you just must wait in queue (or take another road, of course).
🙀 The database is similar in the sense that it will have statistical information of how data is distributed within a table. This is useful to try to decide the best strategy to return the data you’re asking in the query, but it also comes with the fact that statistics come with a certain degree of error. This means that the query engine may estimate that the subquery will return “X” rows, but when it executes it will really return “Y” rows. If you have nested subqueries, the error will propagate and can get amplified, up to the point that – potentially – the query optimizer will try to use index “A” as it thinks at some point there will be only – for example – 10 rows involved, but there will be 10K for real, making the index usage a potentially bad choice.
The amplitude of the error propagation and amplification is completely dependent on the query itself, the data in your tables and other factors (updated statistics, partitions, etc.). The more table references you have, the more likely this is to happen. Imagine a complex query using CTEs calling several Views which have subqueries inside. Estimation errors will potentially pile up.
How do you see if you are having estimation errors? Execution Plans are your friend. They’ll show what steps will be taken to generate the result set and for each step they will show the estimated and the current number of rows touched.

If you notice an estimation completely gone wrong (like several orders of magnitude differences) you may need to give the query optimizer some help.
Temporary tables to the rescue?
Temporary tables can help to greatly reduce or even fix the poor row estimation due to the aforementioned error amplification. How? Well, by storing the result of a subquery into a temporary table, you are resetting such error amplification as the query engine can use the data in the temporary table and thus make sure it is not guessing too much anymore.
Another reason to use a temporary table is if you have a complex query that needs to be used one or more time in subsequent steps and you want to avoid spending time and resource to execute that query again and again (especially if the result set is small compared to the originating data and/or the subsequent queries will not be able to push any optimization down to the subquery as you are working on aggregated data, for example)
But there is no “one-solution-fits-all” here. You must try to see if, for your use case, a subquery is enough, or a temporary table is needed to give the query engine some leverage to get better estimations and thus a better execution plan.
Keep also in mind that using temporary tables comes with some overhead. Aside from the obvious space usage, resources – and thus time – will be spent just for loading them. Sometimes you might even need to create indexes on temporary tables to make sure subsequent query performances are at the top.
The data persisted in the temporary table, also, is not automatically kept up to date with any changes that might be made to the data in the tables used in the originating query. It is your responsibility to refresh the data on the temporary table anytime you need it (Another option would be to use Indexed Views: see below for more details on this feature).
Other stuff that you may want to know
Indexed Views
A special kind of Views, the Indexed Views, can be created so that the produced result is materialized and persisted into the database data file. With Indexed Views, the result doesn’t need to be re-calculated every time, so they are great for improving read performances. In HTAP scenarios they can help to get a great performance boost. The database engine will also make sure that every time data in one of the based tables used in an Indexed View is updated, the persisted result is updated too, so that you always have fresh and updated values.
Inline Table-Valued Functions (aka Parametrized Views)
Sometimes you would like to have a View with parameters, to make it easier to return just the subset of values you are interested in. In Azure SQL and SQL Server, you can create parametrized views. They fall (more correctly, IMHO) under the umbrella of “Functions”, and specifically they can be created by using Inline Table-Valued Functions:
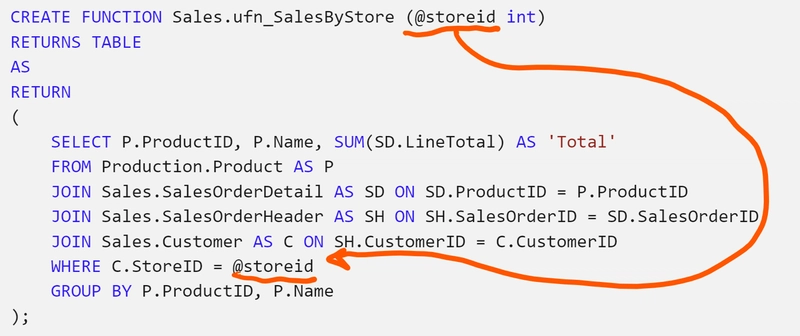
Conclusion
Now you should have a clear picture of what is the difference between CTEs (or subqueries), Views and Temp Tables.
My recommendation is to start with a CTE and then use temporary tables as needed, so that you can get the performance you want with the minimum overhead possible. (I like to say that usage of temporary table is like salt with foods. You can always add it later.)
If you still have questions, make sure to leave them in the comments, so that we can keep the discussion on!
Photo by Pixabay from Pexels
Hi Davide, here Luca from Turin, do you remember me? Congratulations for your articles.
What do you think about usage of in Memory tables to improve performance?
Another question: do you have experience about the bottleneck that temp tables could cause when more queries with temp tables are executed in a closed time?
Thanks
Hi Luca! We released quite a few improvements around TempDB (and thus temporary tables) in the last years especially around metadata optimizations (with SQL Server 2019) that should help to avoid any bottleneck, even under heavy concurrent loads and stress
You didn't mention table variables in this discussion. I'd be interested in your opinion on them.
I prefer table variables to temp tables if I need to store a temporary set of data AND that data may be built programmatically such that a CTE/table function wouldn't work well. In my experience temp tables tend to be created but not cleaned up so attempting to rerun a query fails (although maybe the select into variant doesn't have this issue). Still I see a lot of DBAs say table variables should never be used and to stick with temp tables for perf...
HI Micheal. Right, we should definitely discuss also Temp Tables vs Table Variables, which is another topic that requires a clear explanation and answer. I guess that will require another article. This was already long enough. I will put one together soon. Thanks!
My advice is to always start with CTEs over temp tables and only use temp tables if you have a performance issue and they are a provably faster solution. Far too many times I’ve seen developers default to temp tables and write what could be a single query as several statements inserting into temp tables. This usually ends up being orders of magnitude slower because doing it this way prevents the query optimizer from doing its thing.
SQL is first and foremost a “give me what I want” language, not a “here’s how I want you to get it” language.
Can’t agree more! 🙂