

Chatbots are the hot topic lately, and now you can create them easily by downloading solutions like OpenWebUI, connect it to Ollama or any OpenAI compatible API, choose your favorite language model, and then run it. It just takes a few minutes and it’s done.
But building chatbots is not enough, you most likely want to build a chatbot on your own data. Luckly, the software ecosystem around AI and chatbot is growing every day, and today creating a chatbot that allow your users to chat with data stored in your database is very easy, thanks to libraries like LangChain, ChainLit and, of course, Azure SQL.
To get started, in fact, these three things are the only thing you need:
- Langchain: aframework for developing applications powered by large language models (LLMs).
- Chainlit: an open-source async Python framework which allows developers to build scalable Conversational AI or agentic applications.
- Azure SQL: it added vector support as a core engine feature (check the Early Adopter Preview post)
You can optionally use Azure Functions to have the data added or updated to the database automatically processed for usage with AI models, if you like a change-feed kind of approach. The final architecture, simple and elegant, will look like the following:
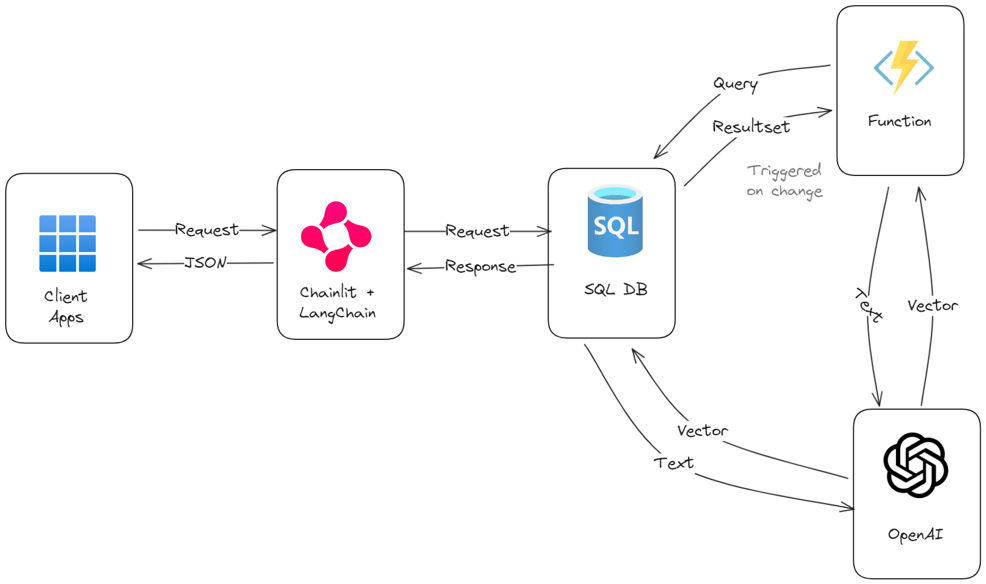
It only takes an hour (or less)
Start from the database
That is right, it only takes less than one hour to start to have a fully working chatbot on your own data. Since we’re focusing on the data side of things, let’s start from the feature that make this capability possible: the newly introduced vector type and the related vector_distance function:
declare @qv vector(1536)
exec web.get_embedding 'RAG on your own data', @qv output
select top(5)
se.id as session_id,
vector_distance('cosine', se.[embeddings], @qv) as distance
from
web.sessions se
order by
distance As you can see, the code is really simple. It turns the provided text into an embedding by calling OpenAI endpoint, via the stored procedure get_embedding and then use the returned vector to find all the similar vectors in the sample table. In this case I’m using a table with data related to conference sessions.
Integrate with LangChain
The next step is to figure out how to plug this code into LangChain, which orchestrates the RAG pattern. Thanks to LCEL – Langchain Expression Language – it’s pretty easy to define the prompt and send it to the LLM along with additional context information extracted from the database:
prompt = ChatPromptTemplate.from_messages([
(
"ai",
"""
You are a system assistant who helps users find the right session to watch from the conference,
based off the sessions that are provided to you. Sessions will be provided in an assistant message
in the format of `title|abstract|speakers|start-time|end-time`. You can use only the provided session
list to help you answer the user's question. If the user ask a question that is not related to the
provided sessions, you can respond with a message that you can't help with that question.
Your aswer must have the session title, a very short summary of the abstract, the speakers,
the start time, and the end time.
"""
),
(
"human",
"""
The sessions available at the conference are the following:
{sessions}
"""
),
(
"human",
"{question}"
)
])
# Use an agent retriever to get similar sessions
retriever = RunnableLambda(get_similar_sessions, name="GetSimilarSessions").bind()
runnable = {"sessions": retriever, "question": RunnablePassthrough()} | prompt | openai | StrOutputParser()the line where runnable is defined is where you can see LCEL in action. It makes sure that placeholders like {sessions} are replaced with actual data before being sent to the LLM (OpenAI in the sample). Actual data that is retrieved using the defined retriever, that in turn calls the get_similar_session function which is nothing more than a wrapper around the SQL code described before.
Pretty amazing! In a few lines of code, we have defined the prompt, the tool used by LangChain to provide additional context data to the LLM, and the way to inject into the prompt that additional context data. The code of get_similar_session is here, if you want to take a look. I have used a stored procedure instead of ad-hoc SQL since it makes the solution cleaner, more secure and easier to maintain.
Add ChainLit
Last missing piece is integrating the work done with Chainlit, which has native support for LangChain, via the LangchainCallbackHandler function. The integration is well explained here: Chainlit- Integrations. Basically, it boils down to two points:
- Initialize Langchain chain and make it available to use before the chat starts
- When users send messages, get their content and pass it to Langchain chain for processing, and return the result
That means that integration happens in two methods only: on_chat_start and on_message. Super easy and straightforward.
Once that is done,…well, the project is done! Run the Python script and you’ll be good to go! Of course, this is only a starting point. You surely want to build a completer and more complex LCEL chains to handle the most diverse requests and situations, and the limits now is just your imagination!
See it in action and try it yourself!
I had to chance to talk about that in the one of the recent conferences, the RAGHack conference, where presented the full end-to-end solution, that you can find on GitHub here:
https://github.com/Azure-Samples/azure-sql-db-rag-langchain-chainlit
Aside from the code repo, you can also watch the recording on YouTube:
Enjoy and start trying the repo on your own data today!
0 comments