

In this technical blog post, I’ll dive into some of the architectural choices made by the Azure SDK team when designing our client libraries. The first thing we always tell people is that the new libraries focus on developer productivity. This productivity comes in many forms:
-
As opposed to making raw network requests to a service, client libraries offer a rich type system enabling features like code completion and compile-time type-safety.
-
By leveraging features like optional parameters and method overloads, we’re able to offer “progressive disclosure”. Specifically, this means that you can start using a service without having to understand all the service’s options and then learn the additional options if your application demands their use.
-
By formalizing some coding patterns, once you learn them, you can intuitively reapply them. For example, we have formalized patterns for iterating over large collections by paging and long-running operations.
-
We offer several credential types and developer experiences for using them to simplify authenticating against the various Azure services.
But, in addition to these productivity features, we know that when you use our SDKs, you are likely building a distributed cloud application. Distributed means that your application makes network calls, and we all know that network calls are prone to failure. For more information, please see the “Fallacies of Distributed Computing” document. Cloud means that your mission-critical application remains fault-tolerant in the face of failures.
So, at a minimum, keeping a distributed application fault-tolerant means that failed network requests are retried and that application network requests are cancelable so that your application doesn’t hang indefinitely should a service take too long to respond. We have a saying on our team:
Client Retries + Service Idempotency = Exactly Once Semantics
For this reason, all of our SDKs have retry and cancelation mechanisms built into them. For more information about this, please see my Architecting Distributed Cloud Applications video series and specifically, this video.
In addition, since distributed cloud applications are so prone to failures, the SDK architecture includes features to help our customers self-diagnose issues. For example, when creating an XxxClient object, the constructor requires the URL endpoint where the service requests are to be made. If no service responds at that endpoint, it should be easy to debug this since we’re using the URL you passed to our client library. Our XxxClient objects also support logging so you can easily capture what raw HTTP requests your app has made to a service and what response the service returned.
XxxClient Objects, Pipelines, and Policies
When using our client libraries, you construct some XxxClient object (like BlobClient) so that your application can make service calls. When you create an XxxClient, you pass it the URL of the service endpoint, the credential you wish to use to authenticate with the service, and some options. The credential and options are used to create (what we call) an HTTP pipeline.
The HTTP pipeline adds behaviors to an HTTP request/response. Each behavior is called a policy so we have an authentication policy (which applies your credential), a retry policy, a logging policy, etc. Each policy can mutate an HTTP request’s query parameters, and/or headers before the request is sent over the wire.
Not all policy objects mutate an HTTP request; some policies simply impact the flow of a request/response by performing operations such as logging, retry policies, timeouts, and downloading of response payloads. The order of the policies is important as each policy mutates a request and then forwards the mutated request to the next policy. For example, any policy between the XxxClient’s method and the retry policy executes just once per logical service operation. While any policy between the retry policy and the transport policy executes once per physical network operation.
The figure below shows an example of an application calling a method on an XxxClient object and how the generated HTTP request flows through the pipeline until the final HTTP request is sent to the Azure service (via the transport policy). Once the service returns a response, that response flow backwards through the pipeline where the payload is usually deserialized and returned to your application code.
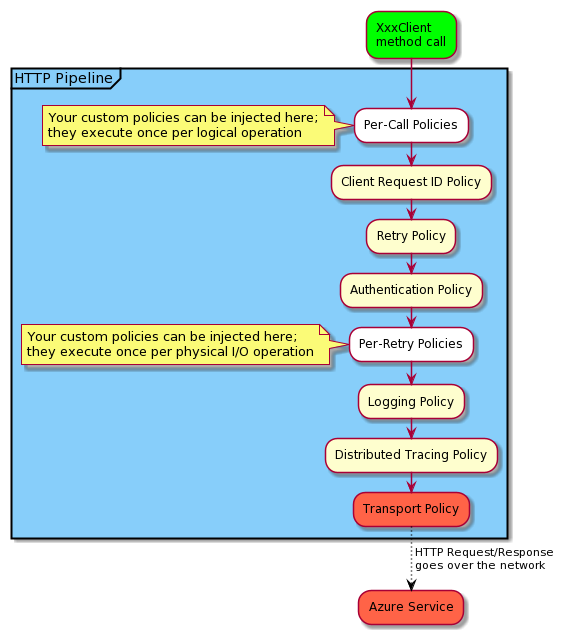
The pipeline is a fully documented and supported extensibility mechanism. In fact, you can implement your own policies for things like client-side caching, circuit breakers, mocking, fault injection, and much more.
Thread Safety and Performance
An important goal that we had when architecting the SDKs was to ensure that a single XxxClient object can be used by multiple threads simultaneously without any chance of data corruption. We accomplished this by ensuring that pipelines are immutable; that is, once created, the policies in them (and their order) cannot be changed. Furthermore, the policy types that ship in the Azure SDKs are all immutable. That is, once each policy object is constructed using its specified retry, logging, and other options, the policy object’s state is immutable. So, it is impossible for one thread to change a retry policy’s option while another thread is attempting to use that same retry policy. This ensures that the XxxClient objects always exhibit consistent behavior and are not subject to race conditions.
Since pipelines and their policies are immutable, multiple XxxClient objects can share a single pipeline to conserve memory and system resources. Furthermore, since policy objects are immutable, multiple threads can use the same pipeline object at the same time without taking any locks. This ensures that our pipelines/policies offer phenomenal performance and scalability for your application.
However, since pipelines/policies are immutable, if your application wants to make network requests with different behavior (retry policy options, different credential type, etc.), then your code must create a new XxxClient object specifying the desired credential and options. Now, code using the new object gets the new desired behavior and code using the original object experiences the same old behavior.
I must point out that the Azure SDKs ship with one policy group that is not immutable: authentication policies. While authentication policies are mutable, we still ensure that they are thread safe so the ability to use a single XxxClient object by multiple threads simultaneously is still guaranteed to work correctly. Allowing mutable authentication policies permits your application to update the password of a credential or refresh its access token on the fly transparently while your application’s threads continue to use the pipeline. This is an awesome feature that you can leverage to easily update a credential’s value without your application incurring any downtime. Updating a credential’s value in an authentication policy is very fast and so any lock taken here is guaranteed to be taken for an incredibly short amount of time as to not impact the performance and scalability of your application.
Conclusion
This blog post dives into some of the important architectural aspects of the new Azure SDKs and I hope you can see how much time and effort went into them. The main goals of the architecture are to focus on your productivity when consuming Azure services while also ensuring low resource consumption, high performance, and scalability of your applications. This architecture even allows for the dynamic and threads-safe updating of authentication credentials without requiring any downtime of your application.
Hi, Jeffrey!
Eight years have passed since your 4th release of CLR via C#.
My friend is telling me that we have higher chances to see the next The Elder Scrolls VI in a couple of years rather than your next book.
But I believe in you Jeffrey !
Thanks for the vote of confidence but I do not think I’ll revise CLR via C# again.
However, I have a new video series on Architecting Distributed Cloud Applications available free on YouTube.
“Fallacies of Distributed Computing” document link doesn’t work.
Yes correct, same observation from me as well.
Here’s a working link from the author: https://arnon.me/wp-content/uploads/Files/fallacies.pdf
Thanks for bringing it up.