
Many of the mobile apps we build and use provide an optimized interface on top of raw data retrieved from a remote service.
When the service is constructed with a mobile app in mind, it’s generally mindful of giving you a nice API that takes into account the limitations of the device you are running on, which could include intermittent Internet access, limited screen space, or the unwillingness of the user to type.
However, when the remote service is not intended for mobile use, your application may require data over which you have little control. You may have no choice over the format of the data, and no friendly medium to access the information. The technique we turn to in this situation is Web scraping: the process of extracting data from human-readable sources like websites, and turning the data into machine-readable structures.
A Better Web Scraper
I recently wrote an app to help users to visualize their Hubway rental history. Hubway is a bike sharing system found in the Boston and Cambridge areas. The application looks like this:
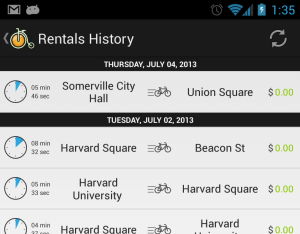
Hubway provides a website to get this information, and the website uses a custom authentication scheme:
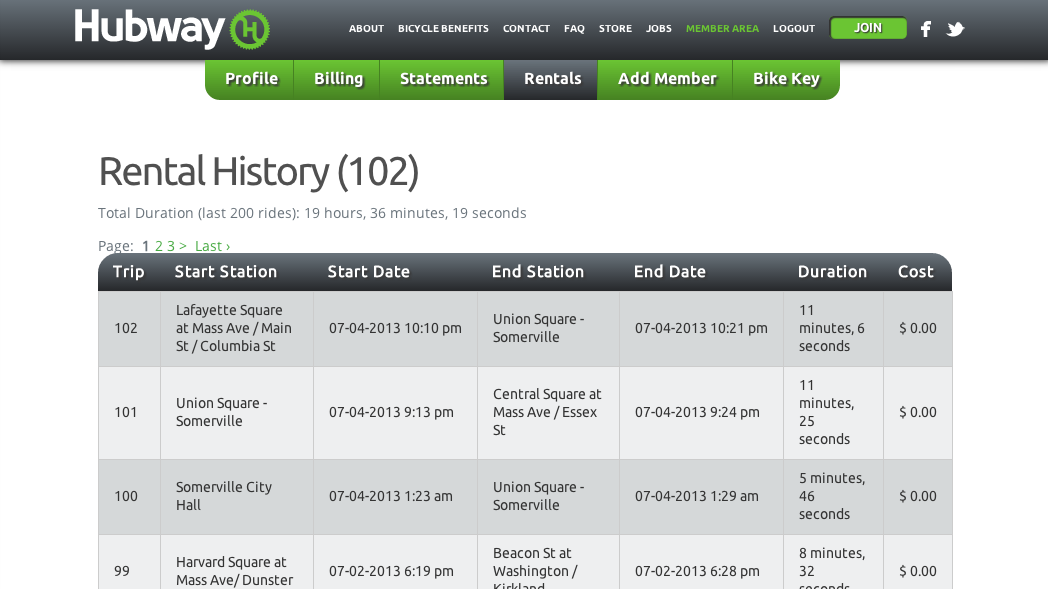
Obtaining this data in a usable form for my mobile app posed two challenges: first, I had to emulate Hubway’s authentication workflow, and second, I needed to extract the individual cell content from the raw HTML. Here is how I made it work.
Authentication
This is the workflow to access the rental history:
- Try to access https://thehubway.com/rentals
- If your cookies contain a valid authentication token, show rentals
- If not, issue a 302 redirect to https://thehubway/login
- User types his or her credentials and validates
- If login is successful, another 302 is generated to redirect user to their member page
- Go back to 1
This is not an easy task because some of these steps involve network calls, and there are multiple points of failure. Previously in the .NET world, you would have devised a solution using WebClient and maybe some Task continuations, and ended up with spaghetti code.
Thanks to the async/await support that was added to the Xamarin family, and the new HttpClient swiss-army knife class in .NET 4.5, this workflow can be translated into an equivalent imperative algorithm:
public async Task<Rental[]> GetRentals ()
{
bool needsAuth = false;
client = new HttpClient (new HttpClientHandler {
AllowAutoRedirect = false, // This allows us to handle Hubway's 302
CookieContainer = cookies, // Use a durable store for authentication cookies
UseCookies = true
});
// Instead of using a infinite loop, we want to exit early since the problems
// might be due to a broken website or terrible network conditions
for (int i = 0; i < 4; i++) {
try {
if (needsAuth) {
var content = new FormUrlEncodedContent (new Dictionary<string, string> {
{ "username", credentials.Username },
{ "password", credentials.Password }
});
var login = await client.PostAsync (HubwayLoginUrl, content).ConfigureAwait (false);
if (login.StatusCode == HttpStatusCode.Found)
needsAuth = false;
else
continue;
}
var answer = await client.GetStringAsync (rentalsUrl).ConfigureAwait (false);
return ProcessHtml (answer);
} catch (HttpRequestException htmlException) {
/* Unfortunately, HttpRequestException doesn't allow us
* to access the original http status code */
if (!needsAuth)
needsAuth = htmlException.Message.Contains ("302");
continue;
} catch (Exception e) {
Log.Error ("RentalsGenericError", e.ToString ());
break;
}
}
return null;
}
This method takes an optimistic approach by reusing a cookie container that is stored durably, using XML serialization. In case of a 302, which indicates that the user needs to re-authenticate, we handle the “error” condition gracefully by restarting the loop and sending the user credentials to refresh our cookie-based tokens.
HTML extraction
HTML extraction is simple thanks to the HtmlAgilityPack library.
HtmlAgilityPack allows you to parse HTML documents. Unlike traditional XML parsers, it is able to recover from badly written content, much like your web browser. Moreover, the library is mostly cross-platform C#, so it’s easy to drop in your Xamarin mobile projects. You can take a look at my own cleaned up version of the library, which is exposed as a Xamarin.Android library project.
Those familiar with HtmlAgilityPack may recall that walking the parsed HTML tree was tedious business. Not so anymore: HtmlAgilityPack introduced a delightful new API to access the resulting DOM. This API is similar in spirit to System.Xml.Linq.
For example, Hubway’s HTML has this shape:
html
+- body
+- div [id="content"]
+- table
+- tbody
+- tr
+- td <-- the fields we are interested in
Thanks to HtmlAgilityPack, we can extract data in the following way:
// HTML data we got earlier
string answer = ...;
var doc = new HtmlDocument ();
doc.LoadHtml (answer);
var div = doc.GetElementbyId ("content");
var table = div.Element ("table");
return table.Element ("tbody").Elements ("tr").Select (row => {
var items = row.Elements ("td").ToArray ();
return new Rental {
Id = long.Parse (items[0].InnerText.Trim ()),
FromStationName = items [1].InnerText.Trim (),
ToStationName = items [3].InnerText.Trim (),
Duration = ParseRentalDuration (items [5].InnerText.Trim ()),
Price = ParseRentalPrice (items [6].InnerText.Trim ()),
DepartureTime = DateTime.Parse(items[2].InnerText, CultureInfo.InvariantCulture),
ArrivalTime = DateTime.Parse(items[4].InnerText, CultureInfo.InvariantCulture)
};
}).ToArray ();
Conclusion
As our devices get more powerful, we are liberated from the constraints of pre-massaged data, and can do more complex content processing.
The main drawback of scraping your data is that it requires the website to keep its HTML structure relatively compatible. If the website changes, your app may suddenly stop working. You will need to react promptly to correct the problem, which may not be possible if the app store has a long review process.
However, if you want to add a companion mobile app to an existing web-based application without re-architecting your data layer, this technique can help you build something quickly and efficiently. For example, Facebook uses the raw HTML of their mobile website http://m.facebook.com to provide content for their native iOS app.