
Introduction
Since the first IntelliCode code completion model was shipped in Visual Studio and Visual Studio Code in 2018, it has become an essential coding assistant for millions of developers around the world. In the past two years, we have been working tirelessly to enable IntelliCode for more programming languages and, in the meantime, researching ways to improve the model precision and coverage to deliver an even more satisfying user experience. One of our major research efforts was to bring the latest advancements in deep learning for natural language modeling to programming language modeling. After leveraging technologies like Azure Machine Learning and ONNX Runtime, we have successfully shipped the first deep learning model for all the IntelliCode Python users in Visual Studio Code.
The Research Journey
The journey started with a research exploration in applying language modeling techniques in natural language processing for learning Python code. We focused on the current IntelliCode member completion scenario as shown in Figure 1 below.
The fundamental task is to find the most likely member of a type given a code snippet preceding the member invocation. In other words, given original code snippet C, the vocabulary V, and the set of all possible methods M ⊂ V, we would like to determine:
![]()
To find that member, we need to build a model capable of predicting likelihood of the available members.
Previous state-of-the-art recurrent neural network (RNN) based approaches only leveraged the sequential nature of the source code, trying to transfer natural language methods without taking advantage of unique characteristics of programming language syntax and code semantics. The nature of the code completion problem made long short term memory (LSTM) networks a promising candidate. During data preparation for model training, we leveraged partial abstract syntax tree (AST)s corresponding to code snippets containing member access expressions and module function invocations, aiming to capture semantics carried by distant code.
Training deep neural networks is a computationally intensive task that requires high-performance computing clusters. We used a data-parallel distributed training framework Horovod with Adam optimizer, keeping a copy of an entire neural model on each worker, processing different mini-batches of the training dataset in parallel lockstep. We utilized Azure Machine Learning for model training and hyper parameter tuning because its on-demand GPU cluster service made it easy to scale up our training as needed, and it helped to provision and manage clusters of VMs, schedule jobs, gather results, and handle failures. The Table 1 showed the model architectures we tried and their corresponding accuracy and model size.
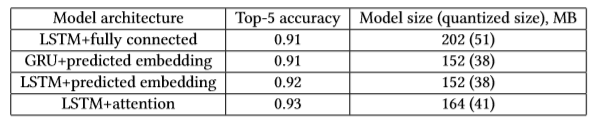
We chose to productize with predicted embedding due to its smaller model size and 20% model accuracy improvement comparing to the previous production model during offline model evaluation; model size is critical to production deployability.
The model architecture is shown in the Figure 2 below:
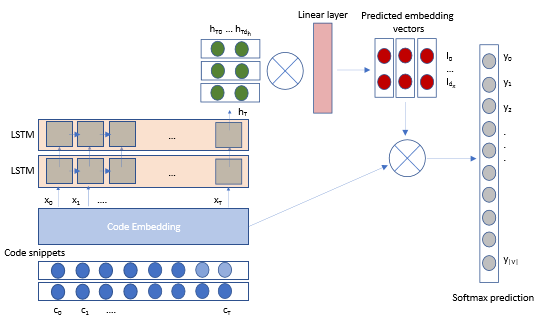
To deploy the LSTM model into production, we had to improve the model inference speeds and memory footprint to meet edit-time code completion requirements. Our memory budget was about 50MB and we needed to keep the mean inference speed under 50 milliseconds. The IntelliCode LSTM model was trained with TensorFlow and we chose ONNX Runtime for inferencing to get the best performance. ONNX Runtime works with popular deep learning frameworks and makes it easy to integrate into different serving environments by providing APIs covering a variety of languages including Python, C, C++, C#, Java, and JavaScript – we used the .NET Core compatible C# APIs to integrate into the Microsoft Python Language Server.
Quantization is an effective approach for model size reduction and performance acceleration if the accuracy drop introduced by low bit width numbers approximation is acceptable. With the post-training INT8 quantization provided by ONNX Runtime, the resulting improvement was significant: both memory footprint and inference time were brought down to about a quarter of the pre-quantized values, comparing to the original model with an acceptable 3% reduction of model accuracy. You can find details of the model architecture design, hyperparameter tuning, accuracy and performance in the research paper we published at the 2019 KDD conference.
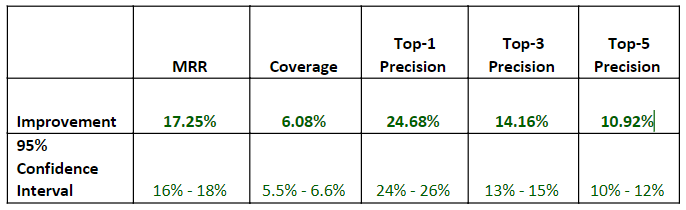
The final gate of the release to production was doing online A/B experimentation comparing the new LSTM model and the previous production model. The online A/B experimentation results in the Table 2 below showed about 25% improvement on top-1 recommendation precision (the precision of the first recommended completion item in the completion list) and 17% improvement on mean reciprocal rank(MRR), which convinced us the new LSTM model is significantly better than the previous production model.
Python developers: Try IntelliCode completions and send us your feedback!
With a great team effort, we completed the staged roll-out of the first deep learning model to all the IntelliCode Python users in Visual Studio Code. In the latest release of the IntelliCode extension for Visual Studio Code, we’ve also integrated ONNX Runtime and the LSTM model to work with the new Pylance extension, which is written entirely in TypeScript. If you’re a Python developer, please install the IntelliCode extension and provide us feedback.
What’s next?
We are looking forward to shipping the deep learning model of member completion for more programming languages in IntelliCode’s coming releases. In the meantime, we are actively working on more advanced transformer based deep learning model for even longer code completions.
How can you leverage what we’ve learned?
Along this journey, ONNX Runtime and Azure Machine Learning were critical in making these developments possible. You can learn how to leverage them in your own scenarios from these links (ONNX Runtime, Azure Machine Learning). The ONNX and Azure Machine Learning teams will be happy to hear your feedback!
I really like the new intellCode suggestions.
I only have one issue and that is changing current code.
if you start deleting a variable, class, control name it will put it to the top of the list and trying to access other items with the same sort of names are way down in the list (more details in the below post).
I have left a fix suggestion that has mostly been ignored here
https://developercommunity.visualstudio.com/content/problem/1014572/intellisense-moving-current-item-to-the-top-of-the.html
this still slows me down every day
if anyone else is experiencing these type of issue please comment up-vote that post so the developers might consider it.
Hi @Scott,
Thanks for the kind words about the IntelliCode suggestions. I'd love to hear any cases you can share where completions or the new suggestions feature have particularly helped you, or places we could improve these capabilities. Drop me a line at mwthomas at microsoft dot com if you are interested to share more.
The specific problem you mention in C# and VB IntelliSense was introduced by a change in Visual Studio 2019 in May. It sorts items first by pattern matching score then alphabetically (this was applied to both C# and VB). The relevant change is at https://github.com/dotnet/roslyn/pull/38499. My...
Sounds fine to me. But, alas, it failed miserably in its first suggestion it made me. I was writing AVX code, and I forgot to sum 4 to the control variable. I moved the cursor there and changed it. Then, I noticed a suggestion in the non-AVX code: it was "Intellicode" (sorry for the scare quotes) suggesting me to perform the same change in the alternative loop!
Yes, I've been told to submit my example to MS, but I decided it's not worthwhile. Intellicode not only lacks good old common sense (as all current DL approaches) but it's a dangerous tool...
Hi Ian.
Thanks for taking the time to provide this feedback.
The feature that you are talking about is IntelliCode Suggestions, which is quite separate from the IntelliCode Completions which Shengyu's blog above is covering.
IntelliCode suggestions uses PROSE pattern matching on your recent edits to create suggestions. There are some issues with false positive cases as you have identified, and we're very keen to hear from users who hit these so we can fine-tune the capability. We're particularly keen to hear about any false positives you see a lot. I quite understand if you don't feel submitting an...
Yay! 🙂
Next up: IntelliCode for JavaScript and JSX? 😛
Yes, IntelliCode is already enabled for JavaScript in VSCode and we’ll be working on deep learning model for it as well.
Awesome! 🙂