

If you are running microservices these days there is a high probability you are managing them with Kubernetes. Kubernetes makes container management easy and its websites boasts of “Planet Scale”, “Never Outgrow”, and “Run Anywhere” as some of its key features. As a Sustainable Software Engineer, I read those phrases as more of a warning of runaway infrastructure that consumes with no boundary or regard to the impact on the planet or checkbook. The good news is that Kubernetes is built in a way that it can make carbon-aware decisions balanced against the technical requirements of the system. This post will step through an example of how to extend the Kubernetes Scheduler to take advantage of the natural fluctuations in carbon intensities in our existing power grids to minimize the amount of carbon in the atmosphere that your Kubernetes cluster is responsible for.
System Overview
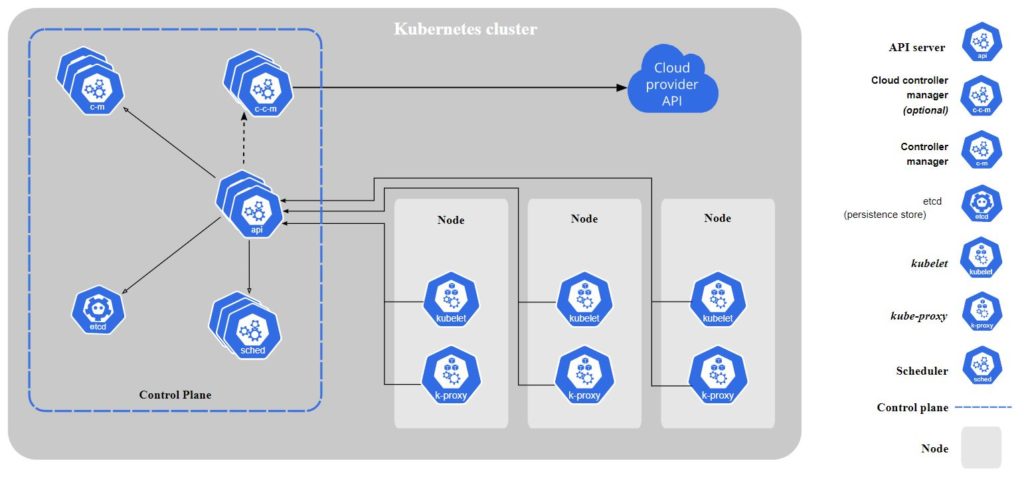
The bulk of the functionality comes from the Kubernetes Scheduler itself and a research paper titled “A Low Carbon Kubernetes Scheduler“. In short, the Scheduler takes Pods (one or more of your containers) and assigns them to run on Nodes (virtual or physical machines). It does a good job on its own of placing Pods to keep an even distribution across Nodes and ensure enough resources (memory, CPU, etc.) are available to run workloads. However, the Scheduler also lets you define your own rules for how to assign Nodes to Pods. This is where we can inject carbon intensity data as another factor for the Scheduler to use when placing Pods.
Carbon intensity data for electrical grids around the world is available through APIs like WattTime. They provide a Marginal Operating Emissions Rate (MOER) value that represents the pounds of carbon emitted to create a megawatt of energy — the lower the MOER, the cleaner the energy. WattTime’s API provides both a real-time and projected carbon intensity value for a location like zip code or Lat/Lng coordinate. We can query the API to get the carbon intensity of the location of each of our Nodes and feed this to the Scheduler’s algorithm to make a carbon-aware decision about where to place the new Pod.
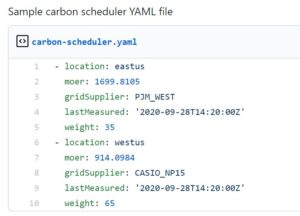 With a MOER value assigned to each Node, we need to account for assigning a weight across multiple Nodes. A simplified approach is to take the MOER value of an individual node and divide it by the total MOER values across all nodes to get a normalized percentage weighting of each Node. Save these weightings to a YAML file and by applying them as a Priority for the Scheduler, your Pods will now be assigned to Nodes with lower MOER values where possible. This sample YAML file should be periodically updated as carbon intensities change and re-applied to the Scheduler. Executing the weighting calculation as its own process will allow you to add additional factors to your weighting algorithm, like latency or predicted MOER values.
With a MOER value assigned to each Node, we need to account for assigning a weight across multiple Nodes. A simplified approach is to take the MOER value of an individual node and divide it by the total MOER values across all nodes to get a normalized percentage weighting of each Node. Save these weightings to a YAML file and by applying them as a Priority for the Scheduler, your Pods will now be assigned to Nodes with lower MOER values where possible. This sample YAML file should be periodically updated as carbon intensities change and re-applied to the Scheduler. Executing the weighting calculation as its own process will allow you to add additional factors to your weighting algorithm, like latency or predicted MOER values.
These three pieces together (Scheduler, Carbon Intensity Data, Weighting Algorithm) allows any Kubernetes instance to become carbon aware. It can take advantage of natural fluctuations in carbon intensity to ensure your application requires the least amount of carbon to meet your business and customer needs. There are a lot of positive changes in carbon reduction, having an automated way of shifting your workloads around like this allows you to quickly take advantage of improvements and help reduce demand on higher carbon emitting sources.
Specific Comparison of Regions
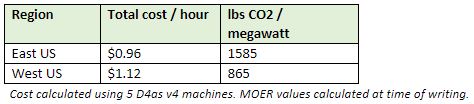
Kubernetes can run physical and virtual machines anywhere but let’s look at a specific scenario using Azure. Let’s say you run some Linux microservices in East US that consists of 5 D4as v4 machines. According to current prices you would be paying about $0.96/hour to run them in the East US region. The MOER value for East US fluctuates but averages about 1550 lbs of CO2/megawatt. By comparison, the West US region MOER value stays around 850 lbs of CO2/megawatt or a little more than half of what East US emits for the same machine type. Your costs for these machines in West US are $1.12/hour so you will pay a small premium to cut your carbon emissions roughly in half.
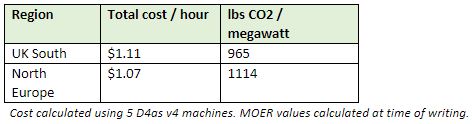
Let take the same scenario as above but this time using a couple regions in Europe: UK South and North Europe. UK South offers D4as v4 machines at $0.222 per hour and North Europe at $0.214 per hour currently. However, the MOER values for the two are much closer at 965 lbs of CO2/megawatt for UK South and 1114 lbs of CO2/megawatt for North Europe. In this scenario, running machines in UK South will cost a little under 4% more but save 149 pounds of carbon (or more than 8,600 smartphone charges) for each megawatt you consume.
It’s worth noting that both VM prices and MOER values will fluctuate over time, but that is also the point. While it may be about 50% less carbon to run in West US compared to East US now, if the sun isn’t shining or the wind isn’t blowing those numbers will move closer together. Electrical grids are adding more renewable energy all the time and are starting to remove heavy polluting coal plants so these MOER numbers will (hopefully) come down over time. Microsoft is helping this trend by announcing a new datacenter in Sweden that will be powered by 100 percent renewable energy sources. Being mindful of your carbon consumption and how your system is able to evolve and shift to be aware of those changes is one of the primary drivers of Sustainable Software Engineering.
Potential Issues with This Design
This solution is focused on a narrow, simplified use case. Your scenario is likely more complex than this, but with careful consideration it is still applicable. As a Sustainable Software Engineer it is important to include sustainability in the conversation and find the right balance. Factors like data sovereignty, latency, and the complexity of shifting infrastructure around should be taken into consideration before going down this path.
Data Sovereignty
Whether it is political or corporate policy, there are often restrictions on where you can transmit and store data. Shifting virtual machines around automatically has the potential to violate these rules. In this approach it is important to know these restrictions and limit the regions available in the weighting algorithm to only those that you can legally use. If your system requires tight control of data, it may be too limiting to take full advantage of carbon intensity fluctuations.
Latency
In the examples above, we compared East US and West US regions by the dimensions of cost and carbon intensity. If the bulk of your customers are on the east coast of the United States, switching to West US could add a noticeable amount of latency to the request and impact those customers. One approach is to use this for asynchronous workloads that can better absorb the additional latency, so it is not impactful to customers. Another option is to adjust the weighting algorithm to account for latencies in its calculation, reducing the weighting factor based on how much latency a regions would add for your typical user. Your specific business rules can guide if this is an appropriate choice.
Complexity of a Shifting Infrastructure
If you are moving resources around to different regions to take advantage of shifting carbon intensities, that can cause a lot of additional complexity in your maintenance and operations. Kubernetes is inherently designed to have ephemeral resources so if you are already running it then you shouldn’t need to adjust much here. You will want to pay specific attention to the amount of churn in your Pods and adjust the weightings appropriately for your capacity requirements. Ensure you are shipping any logs and metrics you need off the machines themselves in case they go away.
Great work – sounds like a lot of potential benefit for e.g. AI training to follow the sun & wind.
Speaking of Kubernetes I think it would also be wonderful if Microsoft would look into making Kubernetes itself more efficient – just check out how much CPU the kubelet uses even in an empty cluster..
Absolutely, there are performance gains to be had everywhere in the stack and Kubernetes is not immune from it. There are a bunch of open issues on GitHub relating to this (ex: https://github.com/kubernetes/kubernetes/issues/82440) so its something that has been recognized by other users and the Kubernetes team is working on addressing them.