


We’ve heard from many in the community who want to use Semantic Kernel to query their relational database using natural language expressions. We are excited to share this sandbox that enables you explore the capabilities of LLM to generate SQL queries (or SELECT statements): NL2SQL. This has been an area of interest for years (WikiSQL, Spider, etc.). While alternative approaches such as local models or semantic search services exist, the focus here is to zoom into the natural abilities (and limitations) of GPT-4 to produce relevant SQL queries. We will share our approach, learnings and some best practices.
Let’s dive right in, check out the video to view the sandbox in action.
Approach
Some basic principles that informed our approach:
- Synchronizing an existing database to vector-storage is a non-starter as there is no desire to introduce consistency considerations or any type of data-movement.
- Injecting data into the prompt-frame is also a non-starter (due to the token limit).
- Prompts cannot be hardcoded to a specific database schema or platform.
- Must discriminate across multiple schemas (in order to support multiple data-sources or to decompose a large schema).
Since GPT-4 demonstrates significantly higher capability for SQL generation (GPT-3.5-turbo generated valid SQL ~70% less than GPT-4 in our limited testing), this is the model we’ve targeted.
Schema
To start, we use an abbreviated object model to express schema meta-data for the model to reason over:

A well-designed schema is generally imbued with semantic intention via the table and column names. If needed, an optional description can be included for additional semantic clarity.
Column meta-data is highly abbreviated to include just name, reference (Foreign Key) and description. Providing a full-fidelity schema model, besides being incredibly token rich, just doesn’t demonstrate functional improvement for the classes of objectives we explored.
The schema model includes platform direction in order for the model to produce the correct SQL variant (since SQL is notoriously vendor specific). Platforms explored include:
- Microsoft SQL Server
- MySql
- PostgreSQL
- SqlLite
Selecting a compact and expressive format to express this schema within the prompt is critical since everything in the prompt counts towards the token-limit. We ended up favoring YAML since it lends itself to the inclusion of description meta-data and appears to be well understood by the model. (Example: AdventureWorksLT.yaml)
Query Generation
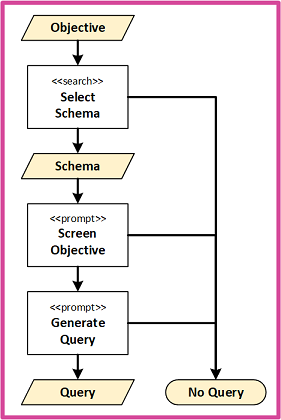
Schema expressions are stored in volatile semantic memory. We use the objective to retrieve the top-ranked schema for use in two sequential prompts:
- IsQuery: Screen whether objective is solvable with a SELECT statement against the schema.
- GenerateQuery: Performs the query generation given the schema and objective.
Both prompts are intentionally low/no-shot approaches in the interest of exposing core model capability. Attempting to marginally tune the prompts with additional training shots doesn’t further this goal (at the cost of consuming tokens that are needed for schema expression).
Attempts to consolidate screening and query generation into a single prompt invariably resulted in failed screening for reference objectives such as:
list all databases
Experimenting with more complex prompting resulted in significant latency, increases cost, with marginal functional impact on query generation.
Usage
As with any LLM processing, it is possible to experience false-positive (bad query) and false-negative (no query) behaviors particularly in response to ambiguous or conflicting direction.
One aspect that comes to light rather quickly is how the model (naturally) responds to semantic nuance and clarity.
An objective such as:
what year had the most sales
evaluates the COUNT of product sales:
SELECT TOP 1 YEAR(OrderDate) AS SaleYear, COUNT(SalesOrderID) AS TotalSales FROM SalesLT.SalesOrderHeader GROUP BY YEAR(OrderDate) ORDER BY TotalSales DESC;
Where:
what year had the highest sales amount
provides the semantic cue that SUM is appropriate.
SELECT TOP 1 YEAR(OrderDate) AS Year, SUM(TotalDue) AS TotalSales FROM SalesLT.SalesOrderHeader GROUP BY YEAR(OrderDate) ORDER BY TotalSales DESC;
Note: objective need not be expressed as a question:
year with highest sales amount
Clarifying implied context can also increase clarity:
list categories for May
is rejected, versus:
list categories for user named May
SELECT B.B1 FROM dbo.A JOIN dbo.C ON dbo.A.A0 = dbo.C.C1 JOIN dbo.B ON dbo.C.C2 = dbo.B.B0 WHERE dbo.A.A1 = 'May'
This principal extends to describing the shape of the resulting dataset…inviting a pseudo-query language of sorts:
list categories for user named May include id and full user name
SELECT A.A0 AS UserID, A.A1 + ' ' + A.A2 AS FullName, B.B0 AS CategoryID, B.B1 AS CategoryName FROM dbo.A JOIN dbo.C ON A.A0 = C.C1 JOIN dbo.B ON B.B0 = C.C2 WHERE A.A1 = 'May'
which shows the previous result hid two different users named “May”.
How deeply is the model able to reason over the schema:
Summarize sales by month before tax and after tax (show name of month)
SELECT MONTH(OrderDate) AS MonthNumber, DATENAME(MONTH, OrderDate) AS MonthName, SUM(SubTotal) AS SalesBeforeTax, SUM(TotalDue) AS SalesAfterTax FROM SalesLT.SalesOrderHeader GROUP BY MONTH(OrderDate), DATENAME(MONTH, OrderDate) ORDER BY MonthNumber;
This is quite impressive; all based on semantic inference of schema naming. This also implies that a database with unusual or non-intuitive design aspects may reduce model clarity. For example, should a ‘SubTotal’ or ‘TotalDue’ column be defined as text (instead of numeric) the model may apply numerical functions such as SUM based on semantic understanding (and provide an invalid query).
What about type? We don’t include type meta-data in the YAML.
list all products with price greater than $3
SELECT ProductID, Name, ListPrice FROM SalesLT.Product WHERE ListPrice > 3;
The model is savvy enough to not include the dollar sign. The following is equivalent:
list all products with price greater than 3 dollars
but this objective:
list all products with price greater than abc
is rejected. For this case, the model reasons that this objective just doesn’t make sense. However, we are able to force the model to generate invalid SQL with:
list all products with price > abc
SELECT * FROM SalesLT.Product WHERE ListPrice > abc;
Curiously, adding literal delimeters is sufficient for the model to again reject:
list all products with price > 'abc'
The model is limited to reasoning over the shape of the data and not able to semantically reason over the data itself. For instance, an objective such as:
list interest category related to food include id and name
SELECT B0, B1 FROM dbo.B WHERE B1 LIKE '%food%'
is not able to recognize that “Diners” and “Ice Cream” are indeed related to food.
Solving complex data objectives exceeds the capability of query generation alone and invites multi-step strategy (planner) approach.
Best practices
Standard best practices apply (as with any application/service data access pattern):
- Least privilege – Restrict to read-only access on relevant tables or views and utilize column and row-level security as appropriate.
- Credential management – Do not expose secrets and connection strings.
- Injection prevention – Never directly inject user-input into SQL statements.
Avoid inadvertent disclosure by capturing/describing database schema at design-time to allow for review/refinement. This approach aligns with least privilege as describing schema requires higher elevation than those needed to query data.
Restrict access only to the desired data. Do not rely on schema definition or query criteria to control access.
Next Steps:
Get started exploring this space in the sandbox: aka.ms/sk-nl2sql
Join the community and let us know what you think: aka.ms/sk-community

That’s interesting…