

During our internal Microsoft Hackathon, there were a number of projects using Semantic Kernel. Today we’d like to highlight one of the projects focused on using Semantic Kernel and the new Vector Store abstraction. I’m going to turn it over to the Hackathon team to share more about their project and work using Semantic Kernel.
Summary
In Microsoft’s 2024 Global Hackathon, we built the prototype for Micronaire as well as a demo project that showcased the capabilities of the library. We built a Romeo and Juliet chat bot that used RAG (Retrieval Augmented Generation) to recall paragraphs of the original Romeo and Juliet text. We utilized the new Vector Store abstraction from Semantic Kernel with their implementation for the Qdrant Database in order to store embeddings of these paragraphs. Once we had a working chat bot, we used Micronaire to evaluate its performance and generate graphs of the data.
RAG pipelines enable developers to augment their chat experiences with informational documents that their agents can leverage to provide better answers. Evaluating these pipelines is a new area of study, with solutions like RAGChecker and RAGAS being state of the art frameworks that are implemented in Python. This project aims to take these ideas and bring them to DotNet through Semantic Kernel.
Micronaire brings actionable metrics to RAG pipeline evaluation by taking a set of ground truth questions and answers as well as a RAG pipeline, evaluating the pipeline against the ground truth using our metrics (see below), and then producing an evaluation report.
Micronaire has been released as open-source code here: microsoft/micronaire: A RAG evaluation pipeline for Semantic Kernel (github.com)
Here’s a link to the Hackathon Project video to learn more: https://learn-video.azurefd.net/vod/player?id=60a35fb0-3c05-454a-9307-afec267c7854
Why the name?
Micronaire is a measure of the air permeability of cotton fiber and is an indication of fineness and maturity. This plays into the evaluation of RAG (like rag textiles).
Semantic Kernel Usage
Micronaire uses Semantic Kernel in two ways. First, it uses Semantic Kernel as a way to target RAG pipelines that users of the library have written in Semantic Kernel’s C-Sharp implementation. Second, it uses Semantic Kernel as an AI Orchestrator to run its evaluation and call text completion APIs.
Using Micronaire
After bringing in the Micronaire library, users need to implement Micronaire’s expected RAG interface for their Semantic Kernel chat bot experience. The interface is shown below:
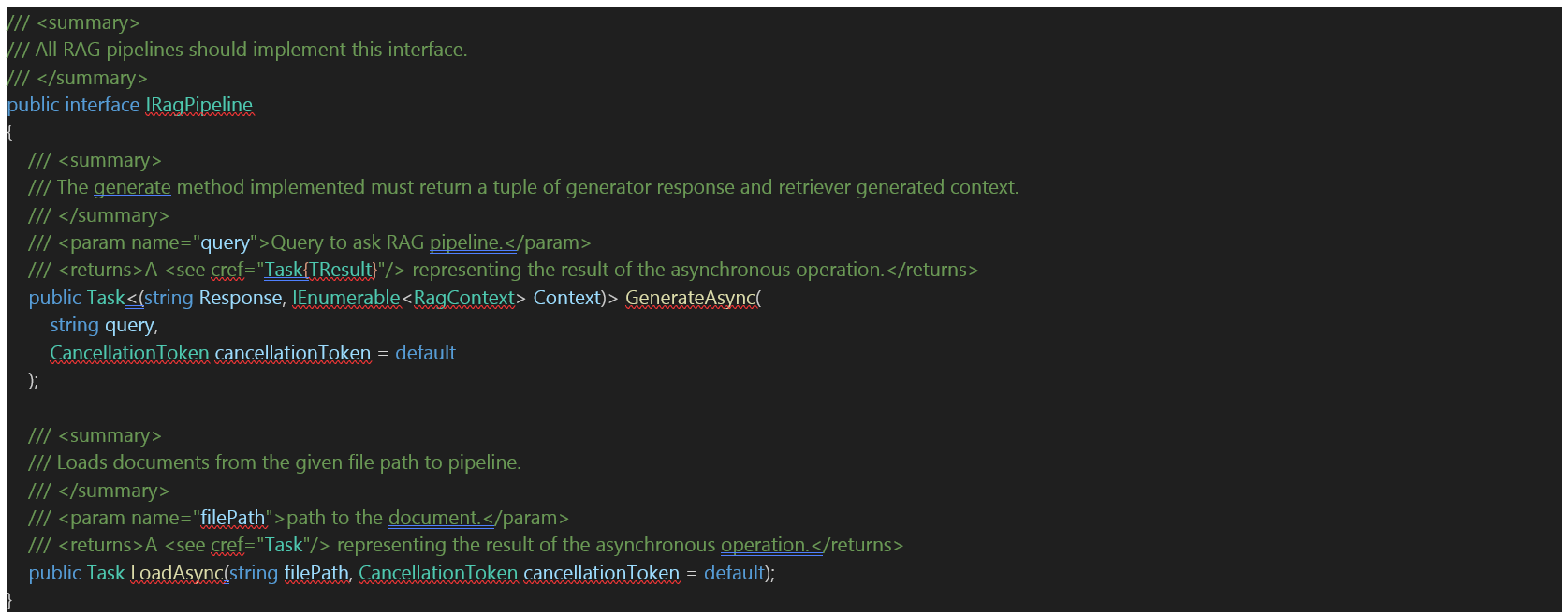
Next, users must generate a set of ground truth questions and answers for their evaluation in a JSON list. A simple example of this is shown below:

Users must register Micronaire with dependency injection to allow for Micronaire objects to be created:

Finally, users can grab the Micronaire evaluator from the container and call the evaluation function, passing in their RAG pipeline as well as the path to their ground truth data:

Metrics
Micronaire will generate a set of metrics across different categories. These categories represent all the approaches implemented in the library. Most of these approaches use claim evaluation (see below) to pull out fine-grained claims made by
LLM Evaluation
LLM evaluation uses an LLM to try to evaluate the performance of the RAG pipeline. It uses direct LLM calls which depends on the performance of the evaluating LLM, so using the strongest model possible is best. The following are the metrics that are generated, which are inspired by work done here: Evaluation and monitoring metrics for generative AI – Azure AI Studio | Microsoft Learn.
Groundedness
Measures how well the model’s generated answers align with information from the source data (user-defined context). Higher groundedness is better.
Relevance
Relevance measures the extent to which the model’s generated responses are pertinent and directly related to the queries given. Higher relevance is better.
Coherence
Measures how well the language model can produce output that flows smoothly, reads naturally, and resembles human-like language. A higher coherence is better.
Fluency
Measures the grammatical proficiency of a generative AI’s predicted answer. Higher fluency is better.
Retrieval Score
Measures the extent to which the model’s retrieved documents are pertinent and directly related to the queries given. Higher retrieval scores are better.
Similarity
Measures the similarity between a source data (ground truth) sentence and the generated response by an AI model. A higher similarity is better.
Overall Claim Evaluation
Overall claim evaluation uses extracted claims to evaluate the overall performance of the RAG pipeline. It uses the following metrics:
Precision
Precision tracks the proportion of correct claims to the total number of claims from the generated answer.
Recall
Recall tracks the proportion of correct claims to the total number of ground truth claims.
F1 Score
The F1 Score is the harmonic mean of the precision and recall scores. It can be used as an overall performance metric for the RAG pipeline.
Retrieval Claim Evaluation
Retrieval claim evaluation uses extracted claims to evaluate just the retrieval (the R in RAG) part of the RAG pipeline. It uses the following metrics:
Claim Recall
This is the proportion of claims in the ground-truth answer that are entailed in the retrieved context by the retriever. We say a ground-truth answer claim is covered if it is entailed in the retrieved context claims.

Context Precision
This is the proportion of claims in the retrieved context that are entailed in the ground-truth answer. A context claim is relevant if it is entailed in the ground-truth answer claims.
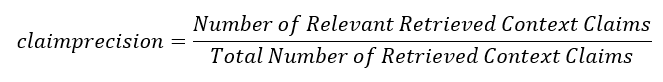
Generation Claim Evaluation
Generation claim evaluation uses extracted claims to evaluate just the generation (the G in RAG) part of the RAG pipeline. It uses the following metrics defined in RAGChecker:
Faithfulness
This is a measure of how faithful generator uses the retrieved context to generate final response. A higher faithfulness means a better pipeline since it means generator is actually using the retrieved context.

Relevant Noise Sensitivity
This is a measure of how sensitive the generator is to noise mixed with useful information in a relevant retrieved context. A lower noise sensitivity is better.
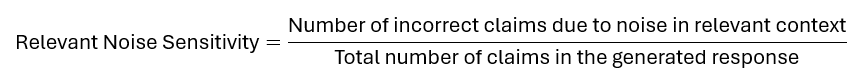
Irrelevant Noise Sensitivity
This is a measure of how sensitive the generator is to noise in a retrieved context that is irrelevant. A lower noise sensitivity is better

Hallucination
This is a measure of the propensity of the generator to make up incorrect claims with no backing by retrieved context. A lower hallucination rate is better.

Self-Knowledge Score
This is a measure of the generator’s ability to make up correct claims that are not backed by the retrieved context. A higher Self-Knowledge score is better.

Context Utilization
This is a measure of how effectively the generator uses retrieved context to generate the ground truth answer.

Claim Extraction
Claim extraction is the process of extracting a set of fine-grained claims of (potentially false) statements from a text. Micronaire achieves this through a chain-of-thought prompt that attempts to first extract subject, relationship, object triples and then combine those into a simple sentence that represents a single claim in a text.
Hallucination =Number of incorrect claims with no backing by retrieved context / Total number of claims in the generated response
Conclusion
We want to thank the Project Micronaire hackathon team for joining the blog today and sharing their work. Please reach out if you have any questions or feedback through our Semantic Kernel GitHub Discussion Channel. We look forward to hearing from you! We would also love your support, if you’ve enjoyed using Semantic Kernel, give us a star on GitHub.
0 comments