

We are thrilled to introduce a new feature within Semantic Kernel that promises to improve AI capabilities: Image to Text modality service abstraction, with a new HuggingFace Service implementation using this capability.
A Glimpse into the Demonstration
In the video below, we’ll walk through a compelling demonstration of a simple Windows Forms application, showcasing the innovative ImageToText feature integrated into the Semantic Kernel, introduced together with the latest update on our Hugging Face connector.
This sample opens asking for a folder path in your environment containing image files. Once provided these images are then displayed in the initial window as soon as the application launches.
The application provides an interactive feature where you can click on each image. Upon clicking, the application employs the Semantic Kernel’s HuggingFace ImageToText Service to fetch a descriptive analysis of the clicked image.
A critical aspect of the implementation is how the application captures the binary content of the image and sends a request to the ImageToText Service, awaiting the descriptive text and updating back the UI. This process is a key highlight, showcasing how simple and easy is to integrate powerful capabilities in your application with Semantic Kernel.
Click here to watch the ImagetoText demo video
When building your own app using HuggingFace ImageToText you will need to use the following packages:
- Microsoft.SemanticKernel
- Microsoft.SemanticKernel.Connectors.HuggingFace
Here’s a glimpse of the C# code snippet required to kickstart the integration:
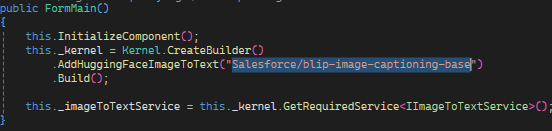
// Initializes the Kernel
var kernel = Kernel
.CreateBuilder()
.AddHuggingFaceImageToText("Salesforce/blip-image-captioning-base")
.Build();
// Gets the ImageToText Service
var service = this._kernel.GetRequiredService<IImageToTextService>();
// Get the binary content of a JPEG image:
var imageBinary = File.ReadAllBytes("path/to/file.jpg");
// Prepare the image to be sent to the LLM
var imageContent = new ImageContent(imageBinary) { MimeType = "image/jpeg" };
// Retrieves the image description
var textContent = await service.GetTextContentAsync(imageContent);Under the Hood: Seamless Integration
Central to the success of this implementation is the seamless integration between our software and the HuggingFace Image to Text Service. The application adeptly captures the binary content of the selected image and dispatches a request to the service, eagerly awaiting the descriptive text in return. This process exemplifies the power and fluidity of our latest enhancement, showcasing its potential to transform how we interact with visual content.
Getting Started
Here is the location of the full code example we’ll walk through below.
To leverage the Image to Text feature within your own applications, you’ll need to ensure you have the necessary packages installed:
- Microsoft.SemanticKernel
- Microsoft.SemanticKernel.Connectors.HuggingFace
The demonstration uses a simple Windows Forms application with Semantic Kernel and Hugging Face connector to get the description of the images in a local folder provided by the user.
Steps to use the Demo.
- Clone semantic kernel repository
- Open your favorite IDE i.e:
VSCode:
- Open in the root repository folder
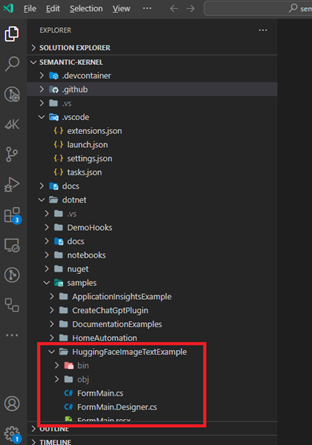
2. Go into Run and Debug (Control + Shift + D) and Select HuggingFaceImageTextSample to start.
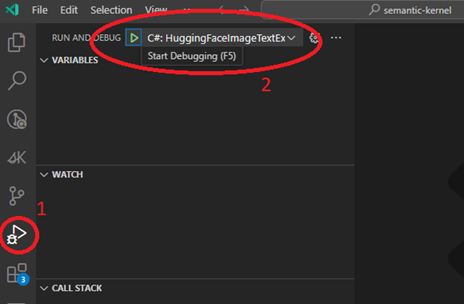
Visual Studio:
- Open SK-dotnet.sln solution file inside <repository root folder>/dotnet. This will trigger your Visual Studio IDE.
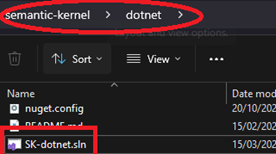
2. Hugging Face Image Sample will be within samples folder in the solution folders.
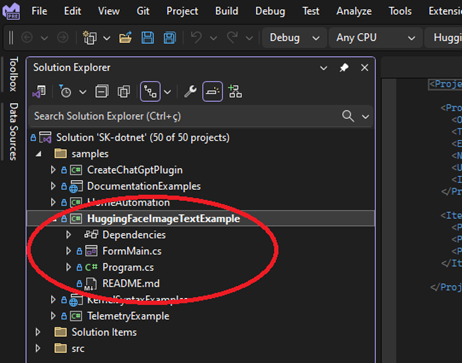
3. On the Debug Menu bar select the HuggingFaceImageTextExample project as starting and click to run
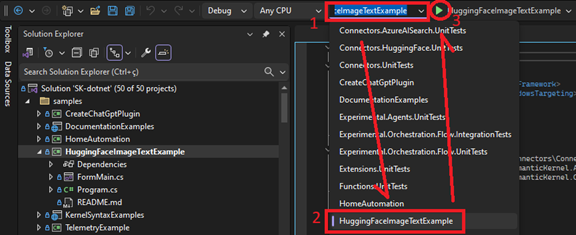
Using the Sample:
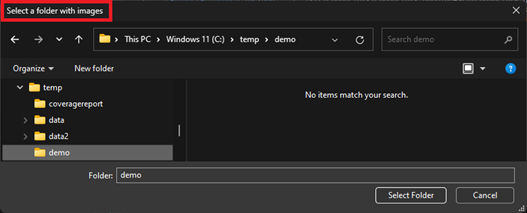
- Upon launching the application, a folder selection prompt will be asking for a folder with images to be used for the sample
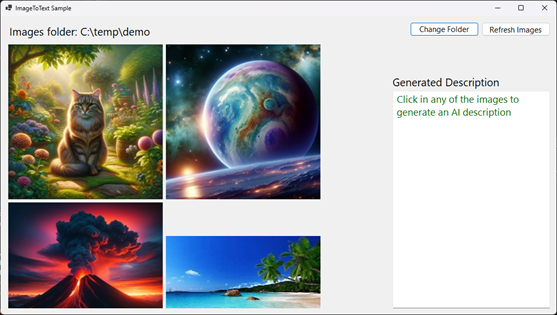
2. After selecting the folder the application will start showing a list of any image type supported (jpg, gif, png) in the folder.
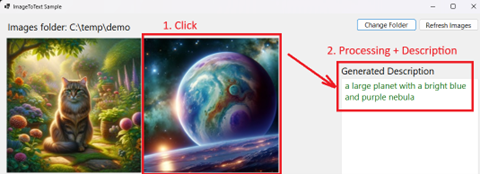
3. After clicking on an image an asynchronous request will be sent to a HuggingFace Salesforce/blip-image-captioning-base ImageToText model to process and generate a description of the image, it may take a few seconds.
4. Since HuggingFace with its inference API creates a common interface for model generation, you can try different ImageToText models changing the target model in the HuggingFaceImageToText Service initialization.
Dive Deeper
Please reach out if you have any questions or feedback through our Semantic Kernel GitHub Discussion Channel. We look forward to hearing from you! We would also love your support, if you’ve enjoyed using Semantic Kernel, give us a star on GitHub.
0 comments