

Today the Semantic Kernel team is excited to welcome a guest author, Prabal Deb to share his work.
LLMAgentOps Toolkit is repository that contains basic structure of LLM Agent based application built on top of the Semantic Kernel Python version. The toolkit is designed to be a starting point for data scientists and developers for experimentation to evaluation and finally deploy to production their own LLM Agent based applications.
Architecture
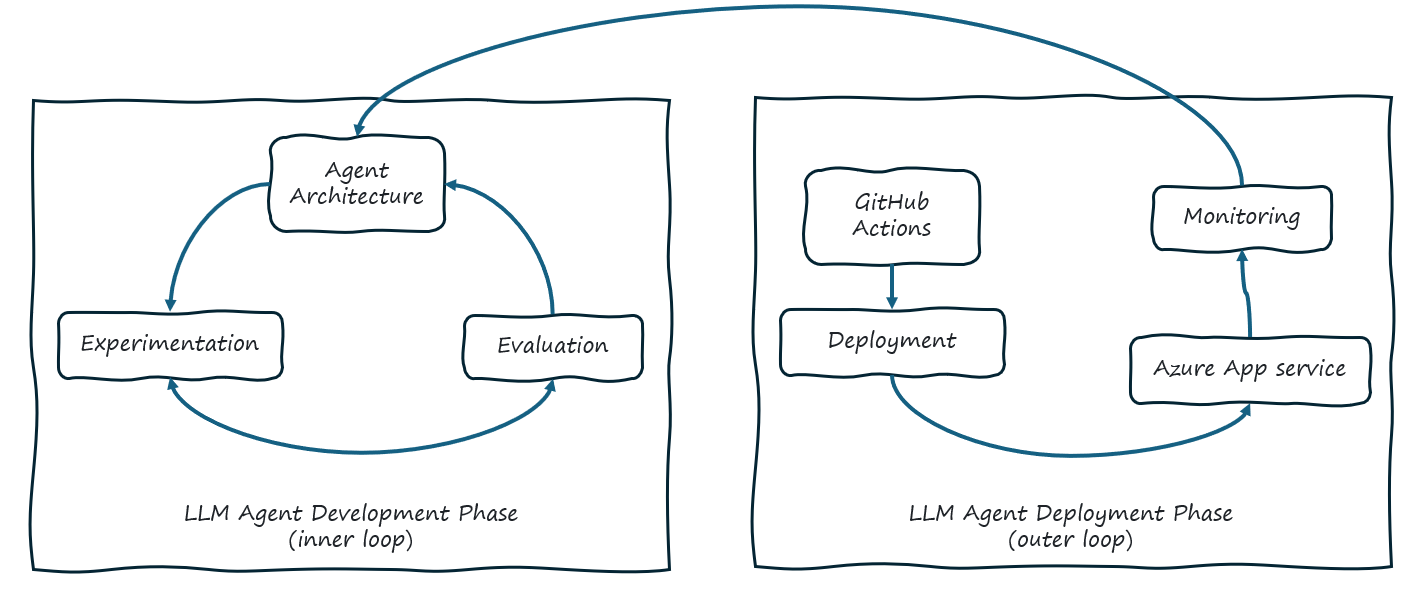
The LLMAgentOps architecture might be constructed using the following key components divided into two phases like DevOps / MLOps / LLMOps development and deployment phases:
- LLM Agent Development Phase (inner loop):
- Agent Architecture: Designing the agent architecture for the LLM Agent based solution. For this sample we have used Semantic Kernel development kit by using Python programming language.
- Experimentation & Evaluation: Experimentation and Evaluation of the LLM Agent based solution. Where the experimentation is done using console or UI or in batch mode and evaluation is done using LLM as Judge and Human Evaluation.
- LLM Agent Deployment Phase (outer loop):
- GitHub Actions: Continuous Integration, Evaluation and Deployment of the LLM Agent based solution with addition of Continuous Security for security checks of the LLM Agents.
- Deployment: Deployment of the LLM Agent based solution in local or cloud environment.
- Monitoring: Monitoring the LLM Agent based solution for data collection, performance and other metrics.
Source Code Structure
The source code of LLMAgentOps application might be structured in such a way that it can be easily developed and maintained by data scientists and developers together with following key concepts of dividing the code into two parts – core and ops:
- Core: The LLM Agent core implementation code.
- Agents Base Class: The base class for the agents.
- Agents: All the agents with their specific prompts and descriptions. Example: Observe Agent.
- Code Execute Agent (optional): The code execute agent is an agent that can join the group of agents, but it will execute the code and return the result, instead of using LLM for generating response like other agents.
- Group Chat Selection Logic: The group chat selection logic is used to select the appropriate next agent based on the current state of the conversation.
- Group Chat Termination Logic: The group chat termination logic is used to terminate the conversation based on the current state of the conversation or maximum number of turns.
- Group Chat: The group chat contains the group chat client that can serve the conversation between the user and the agents.
- Ops: The operational code for the LLM Agent based solution.
- Observability: The observability code contains the code for logging and monitoring the agents. OpenTelemetry can be used for logging and monitoring.
- Application Specific Codes (optional): There could application specific code, like code for interacting with database or code for integrating with other systems.
- Deployment: The deployment code contains the code for deploying the agents in local or cloud environment. In this sample the code is provided for deploying the agents in Azure Web App Service. The deployment code will be:
- Source Module: core implementation of the agents and group chat.
- REST API Based App: REST API based app for calling the agents and getting the response.
- Dockefile: for building the image of the entire application.
- Requirements file for the dependencies.
- Experimentation: The code related to performing experimentation in Console or User Interface or in Batch mode.
- Evaluation: The evaluation related code for LLM as Judge and Human Evaluation.
- Security: The code for the security checks of the LLM Agent based solution.
Experimentation
The experimentation setup by using could be more complex and granular. The experimentation process may involve starting from defining the problem => data collection => LLM agent design => experiments. In this toolkit we have demonstrated how experiments can be done using three following modes:
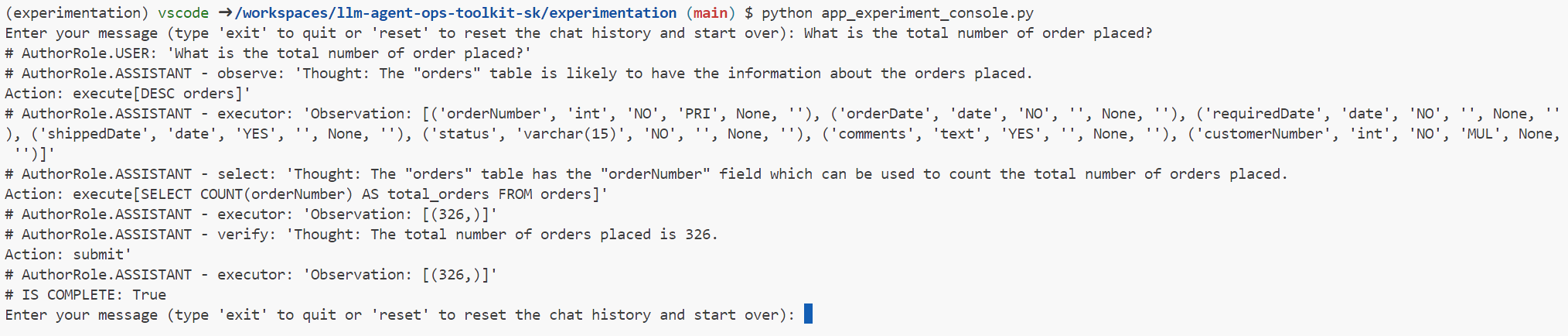
- Experimentation with Console
The Console based experimentation involves running the LLM Agent in the console and interacting with it using a text-based interface.
Note: The console-based experimentation is for initial exploration stage and does not store any data for evaluation.
Sample experiment:
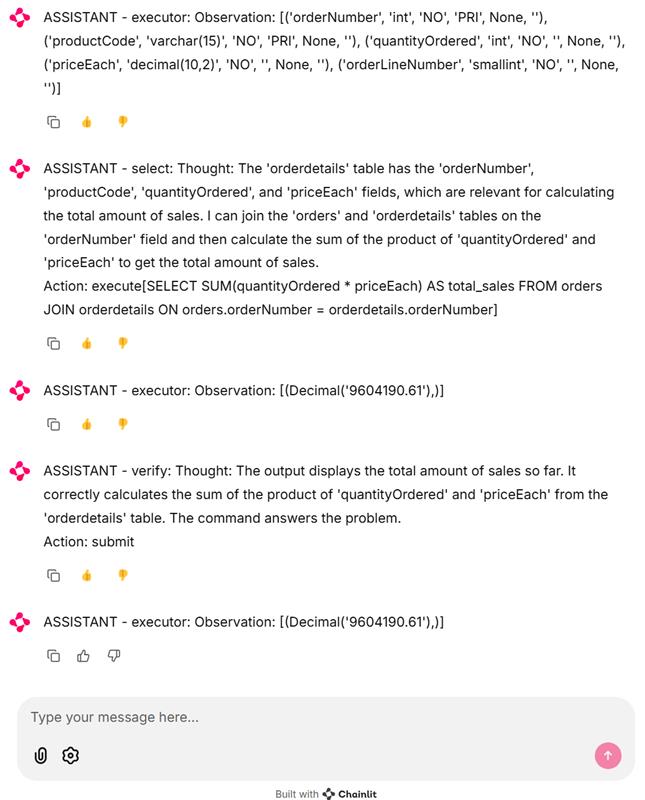
2.Experimentation with User Interface (UI)
The user interface drive experimentation can be achieved using Chainlit where the LLM Agents can be interacted using a conversational interface. The Chainlit provides a more interactive and user-friendly experience for the LLM Agents based solution. It not only stores the conversation data for evaluation but also provides a way to provide Human Feedback for the overall conversation and individual agents.
Note: The UI based experimentation is experiment stage and it can be provided to Human Evaluator for feedback. The collected data can be viewed by opening the SQLite file in an SQLite browser.
Sample experiment:

3. Experimentation in Batch
Batch-based experimentation involves running the LLM Agent in batch mode to process many queries and evaluate the solution’s performance. The batch experimentation can be used to evaluate the accuracy, efficiency, and scalability of the LLM Agents based solution.
Note: The batch-based experimentation is for continuous evaluation stage, and it can be used to evaluate the performance of the LLM Agents based solution.
Evaluation
Evaluation is the process of evaluating the performance of the LLM Agents based solution, that will help in the decision-making process of the LLM Agents based solution. In this toolkit we have demonstrated how evaluation can be done in two following modes:
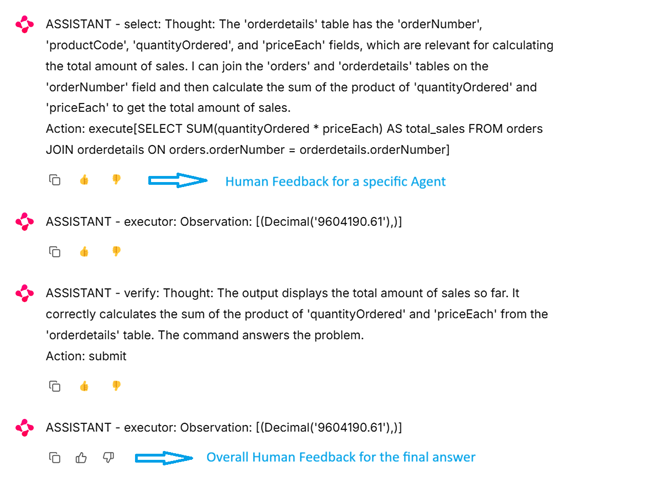
- Human Evaluation
The Human Evaluation is the process of evaluating the performance of the LLM Agents based solution by providing the conversational interface to the Human Evaluator. The Human Evaluator will interact with the LLM Agents using a conversational interface and provide feedback on the overall conversation and individual agents.
This can be achieved by running the Experiment in the UI mode and providing the Chainlit based interface to the Human Evaluator.
Sample Evaluation:
2. LLM as Judge
The LLM as Judge is the process of evaluating the performance of the LLM Agents using another LLM Agent as a judge. For this evaluations Azure AI Foundry Service can be used. For more details, refer to the documentation.
This can be achieved by running the experiment in the batch mode.
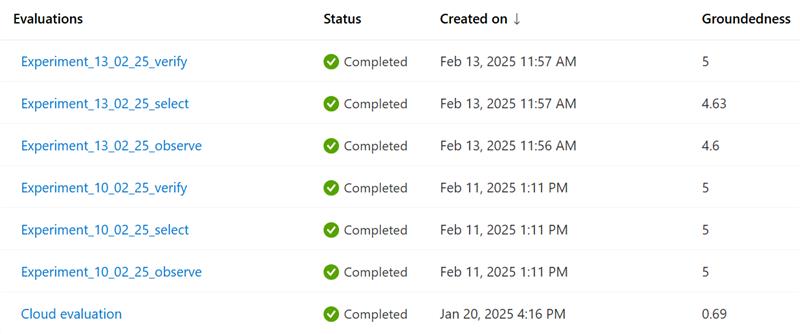
Sample Azure AI Foundry Evaluation Result:
Security Scanning
Security Scanning is the process of ensuring the security of the LLM Agents based solution. Agents are going to write / execute code, browse the web, and interact with databases, hence security is a key concern and must be designed and implemented from the beginning.
The security scan of LLM Agents can be performed using following tools:
- Risk Identification Tool for generative AI (PyRIT)
- LLM Guard – The Security Toolkit for LLM Interactions
In this toolkit we have demonstrated how to enable Continuous Security Scan using LLM Guard.
Sample Security Scanning Result:
==================Summary=====================
Agent Error avg score for scan BanTopics: 0.6
Agent Observe avg score for scan BanTopics: 1.0
Agent Verify avg score for scan BanTopics: 0.8
Agent Select avg score for scan BanTopics: 1.0
Overall avg score for scan BanTopics: 0.85
===============================================
Engineering Fundamentals
The following engineering fundamentals must be considered while designing and developing the LLM Agent based solution:
- GitHub Actions: for continuous integration, continuous evaluation, continuous deployment and continuous security scanning of the LLM Agent based solution.
- Dev Containers: to enable full-featured development environment for LLM Agents, where all required tools are installed and configured to perform rapid experimentation, evaluation and testing.
- Unit Testing of Agents: for testing the Python codes locally with unit test cases.
Toolkit Repository
The toolkit repository Azure-Samples/llm-agent-ops-toolkit-sk contains a sample use case of MySQL Copilot, where user can interact with the solution to retrieve data from a MySQL database by providing a natural language query. The solution uses agentic approach, where LLM Agents will process the user query, generate SQL queries, execute the queries on the MySQL database, and return the results to the user.
This has been implemented using the concept of StateFlow (a Finite State Machine FSM based LLM workflow) using Semantic Kernel agents. This implementation is equivalent to AutoGen Selector Group Chat Pattern with custom selector function.
For more details on StateFlow refer the research paper – StateFlow: Enhancing LLM Task-Solving through State-Driven Workflows.
Extending the Toolkit
This toolkit can be used by forking this repository and replacing the MySQL Copilot with any other LLM Agent based solution or it can be further enhanced for a specific use case.
Conclusion
From the Semantic Kernel team, we’d like to thank Prabal for his time and all of his great work. Please reach out if you have any questions or feedback through our Semantic Kernel GitHub Discussion Channel. We look forward to hearing from you!
0 comments