

We’re excited to announce the launch of Data Wrangler, a revolutionary tool for data scientists and analysts who work with tabular data in Python. Data Wrangler is an extension for VS Code and the first step towards our vision of simplifying and expediting the data preparation process on Microsoft platforms.
Data preparation, cleaning, and visualization is a time-consuming task for many data scientists, but with Data Wrangler we’ve developed a solution that simplifies this process. Our goal is to make this process more accessible and efficient for everyone, to free up your time to focus on other parts of the data science workflow. To try Data Wrangler today, go to the Extension Marketplace tab in VS Code and search for “Data Wrangler”. To learn more about Data Wrangler, check out the documentation here: https://aka.ms/datawrangler.
With Data Wrangler, you can seamlessly clean and explore your data in VS Code. It offers a variety of features that will help you quickly identify and fix errors, inconsistencies, and missing data. You can perform data profiling and data quality checks, visualize data distributions, and easily transform data into the format you need. Plus, Data Wrangler comes with a library of built-in transformations and visualizations, so you can focus on your data, not the code. As you make changes, the tool generates code using open-source Python libraries for the data transformation operations you perform. This means you can write better data preparation programs faster and with fewer errors. The code also keeps Data Wrangler transparent and helps you verify the correctness of the operation as you go.
In a recent study, Python data scientists using the Pandas dataframe library report spending the majority (~51%) of their time preparing, cleaning and visualizing data for their models (Anaconda State of Data Science Report 2022). This activity is critical to the success of their projects, as poor data quality directly impacts the quality of the predictions made by their models. Furthermore, this activity is not predictable: the industry even calls it exploratory data analysis to capture the fact that it is often highly creative, requiring experimentation, visualization, comparison and iteration. However, despite the activity being creative and iterative, the individual operations are not – they involve writing small code snippets that drop columns, remove missing values, etc. But today there isn’t tooling support that makes it easier; In our research with data scientists, we regularly see them searching for and copy-pasting snippets of code from Stack Overflow into their programs.
Data Wrangler Interface
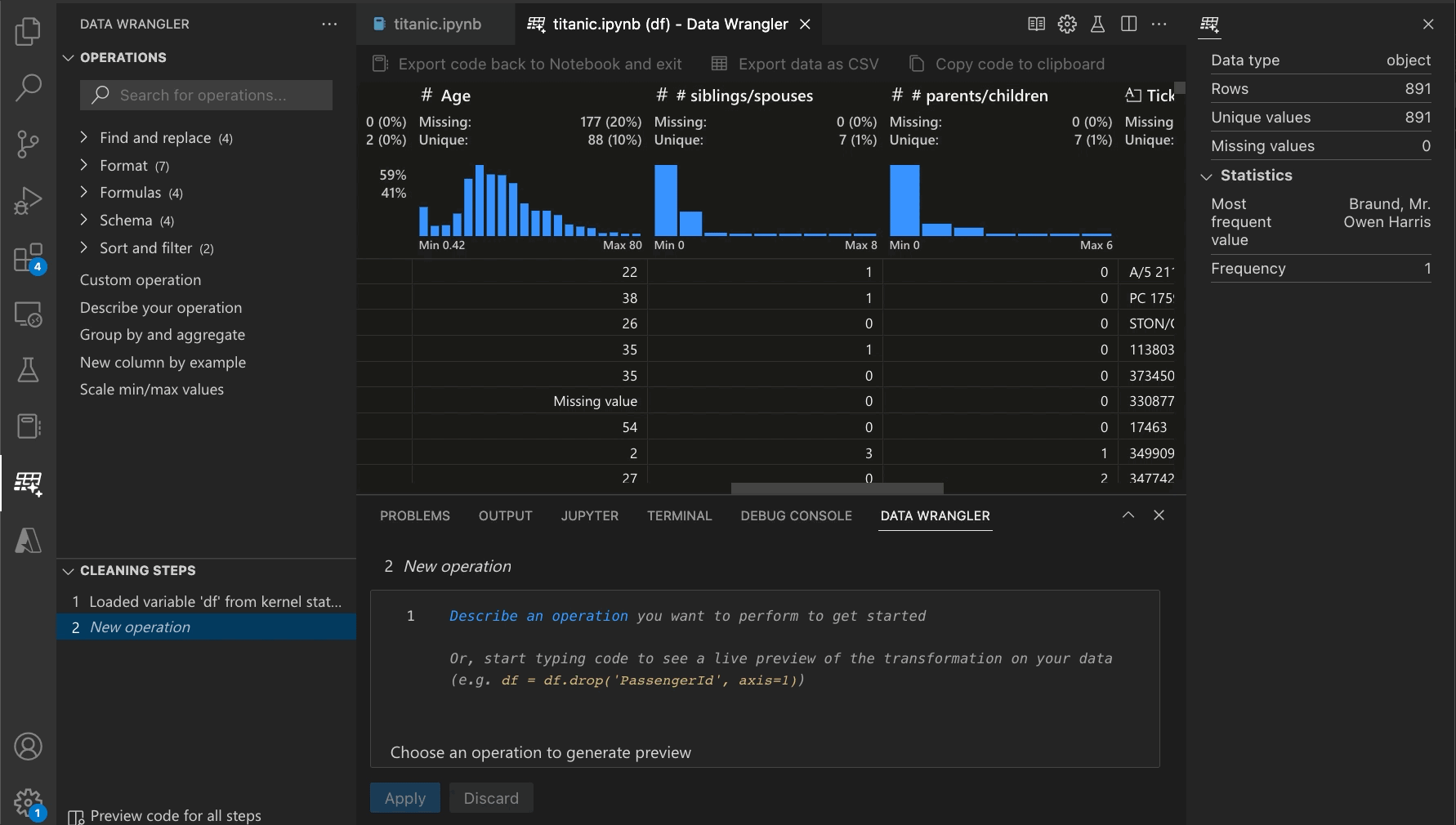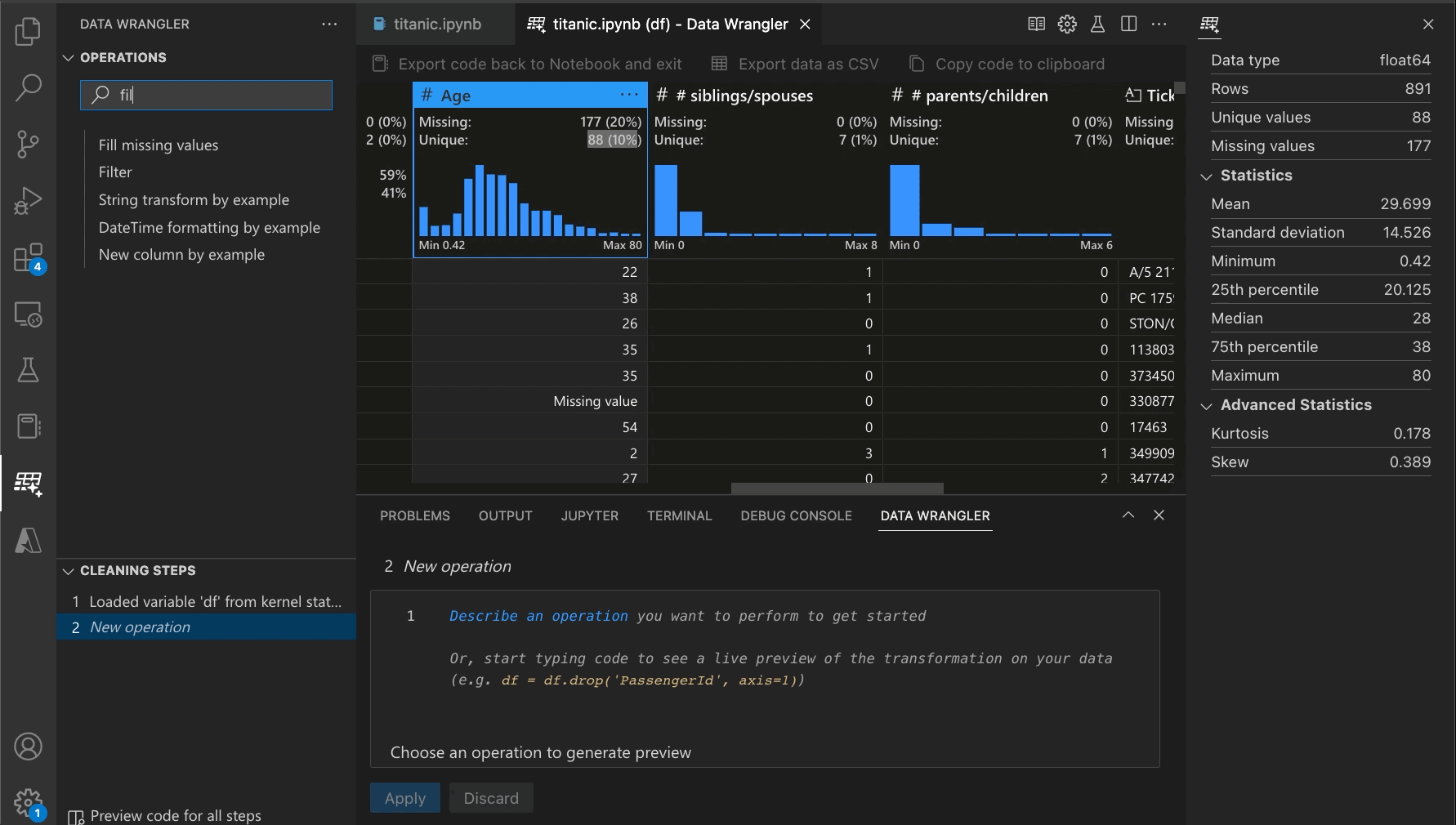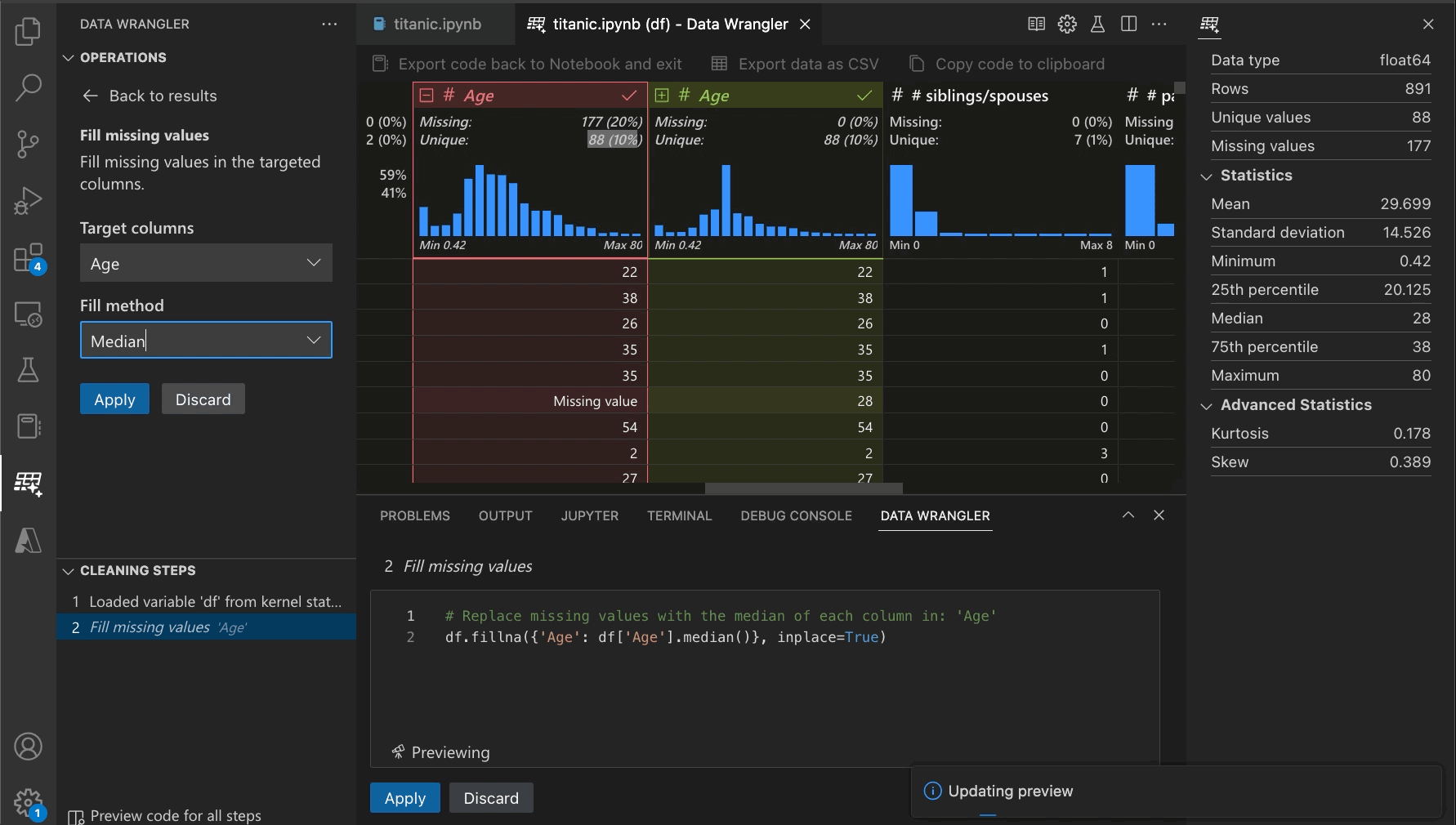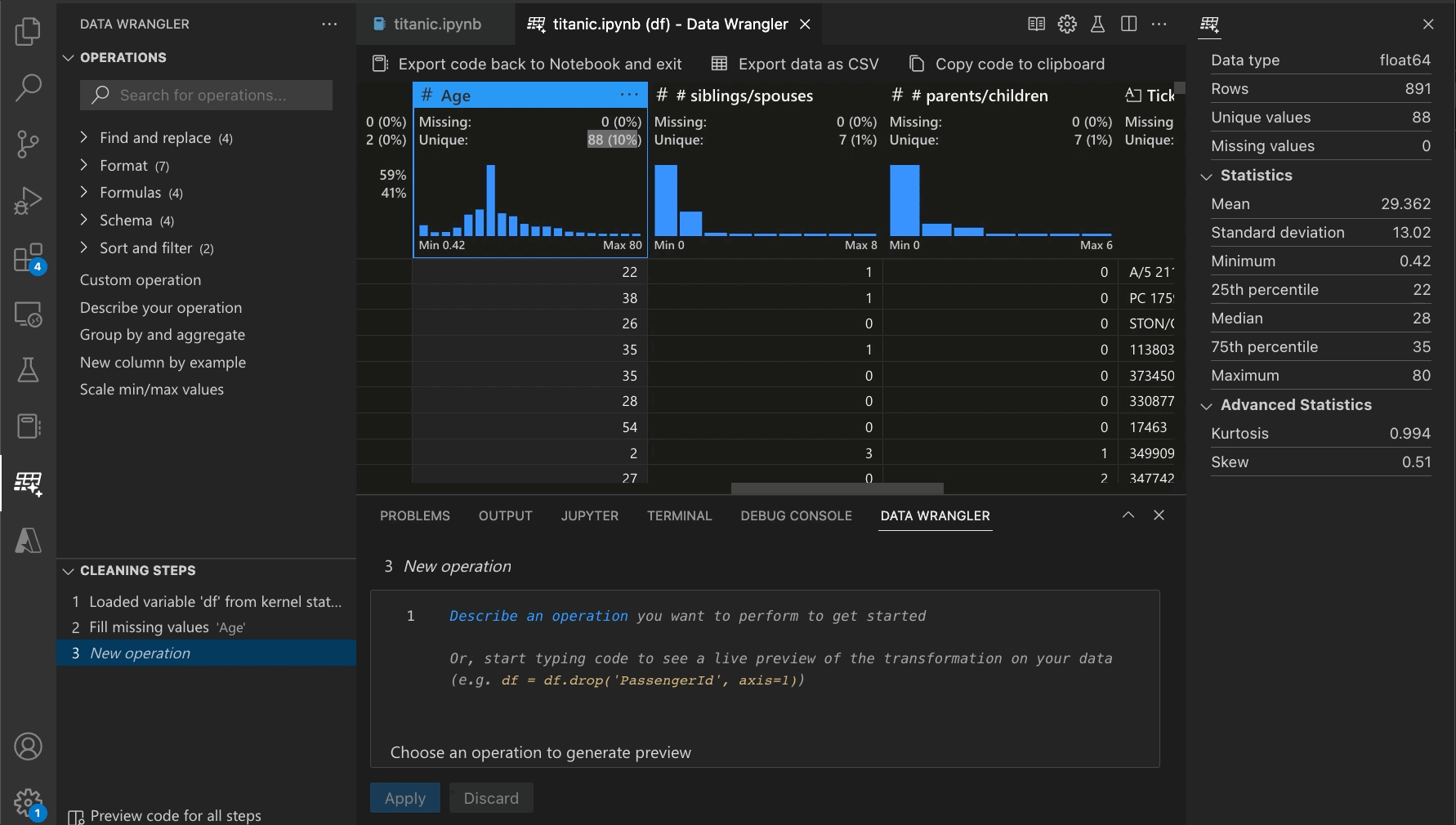
With Data Wrangler, we’ve developed an interactive UI that writes the code for you. As you inspect and visualize your Pandas dataframes using Data Wrangler, generating the code for your desired operations is easy. For instance, if you want to remove a column, you can right-click on the column heading and delete it, and Data Wrangler will generate the Python code to do that. If you want to remove rows containing missing values or substitute them with a computed default value, you can do that directly from the UI. If you want to reformat a categorical column by one-hot encoding it to make it suitable for machine learning algorithms, you can do so with a single command.
Create column from examples
Data scientists often need to create a new derived column from existing columns in their Pandas dataframe, which usually involves writing custom code that can easily become a source of bugs. With Data Wrangler, all you need to do is provide examples of how you want the data in the derived column to look like, and PROSE, our AI-powered program synthesis technology (the same technology that powers Microsoft Excel’s Flash Fill feature), will write the Python code for you. If you find an error in the results, you can correct it with a new example, and PROSE will rewrite the Python code to produce a better result. You can even modify the generated code yourself.

How to try Data Wrangler
To start using Data Wrangler today in Visual Studio Code, just download the Data Wrangler extension from the marketplace and visit our getting started page to try it out! You can then launch Data Wrangler from any Pandas dataframe output in a Jupyter Notebook, or by right-clicking any CSV or Parquet file in VS Code and selecting “Open in Data Wrangler”.

This is the first release of Data Wrangler so we are looking for feedback as we iterate on the product. Please provide any product feedback here. If you run into any issues, please file a bug report in our Github repo here.
For some time, I’ve been searching for an alternative to Power Query that generates Python Code instead of M. This is fantastic, keep it up! Wouldn’t it be something to add Python as an alternative to M for performing data transformations within Power Query? 😀
How is this going to compare to GitHub Copilot which is also a Microsoft software?
Could you make this feature available also in the debug context? That would take it to the next level.
Thanks for the feedback Tim! We actually work closely with both the Python and Jupyter extension teams, so this is something our team can bring up with their teams, and potentially look to add Data Wrangler to the debug context in the future. Or were you more looking for the ability to debug the code/operations in Data Wrangler?
No, as you guessed my idea was to start the Data Wrangler from the debug context of a regular python program.