

Today, we are excited to announce the general availability of the Data Wrangler extension for Visual Studio Code! Data Wrangler is a free extension that offers data viewing and cleaning that is directly integrated into VS Code and the Jupyter extension. It provides a rich user interface to view and analyze your data, show insightful column statistics and visualizations, and automatically generate Pandas code as you clean and transform the data. We want to thank all the early adopters who tried out the extension preview over the past year, as your valuable feedback has been crucial to this release.
With this general availability, we are also announcing that the data viewer feature in the Jupyter extension will be going away. In its place, you will be able to use the new and improved data viewing experience offered by Data Wrangler, which is also built by Microsoft. We understand that the data viewer was a beloved feature from our customers, and we see this as the next evolution to working with data in VS Code in an extensible manner and hope that you will love the Data Wrangler extension even more than the data viewer feature. Several of the improvements and features of Data Wrangler are highlighted below.
Previewing data
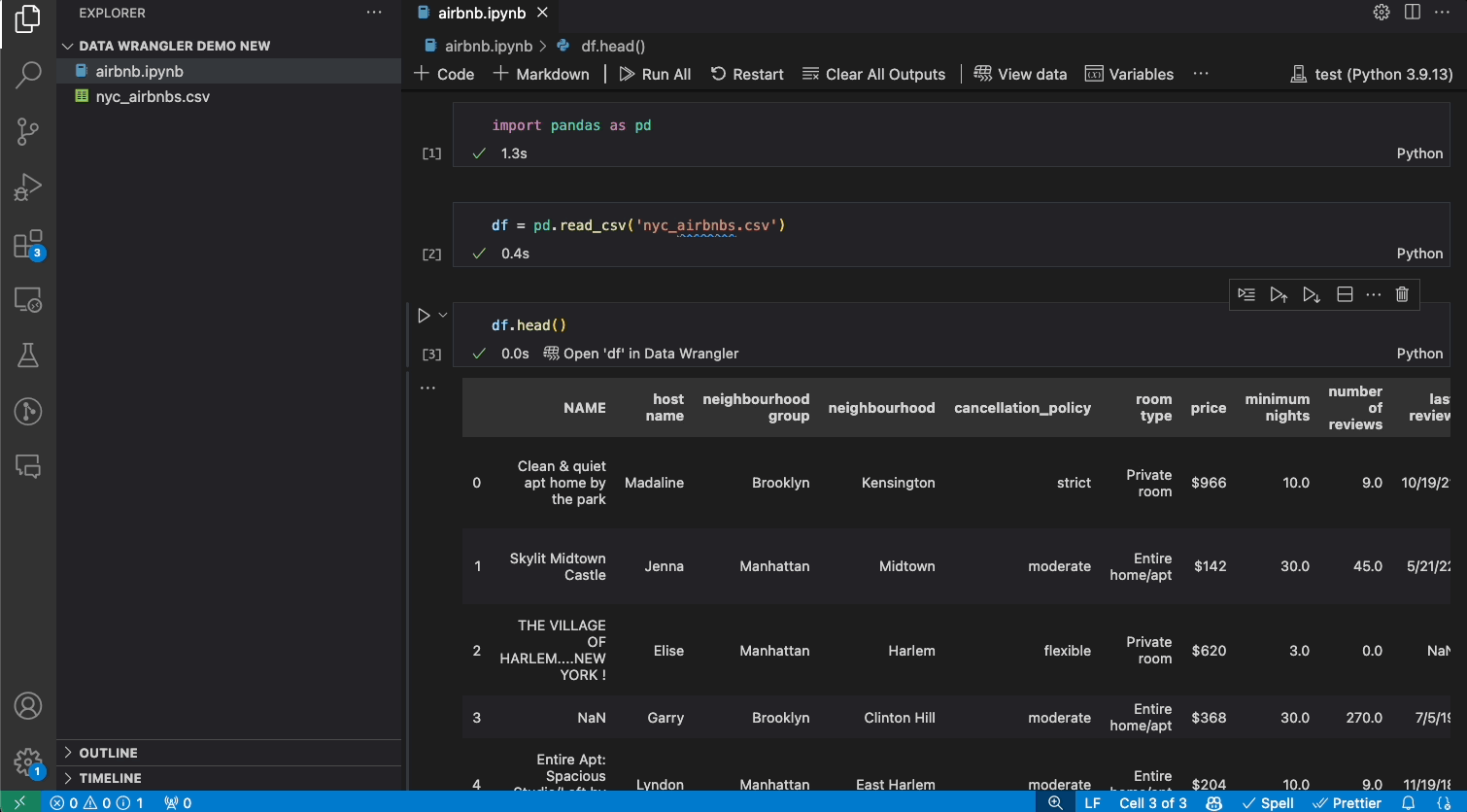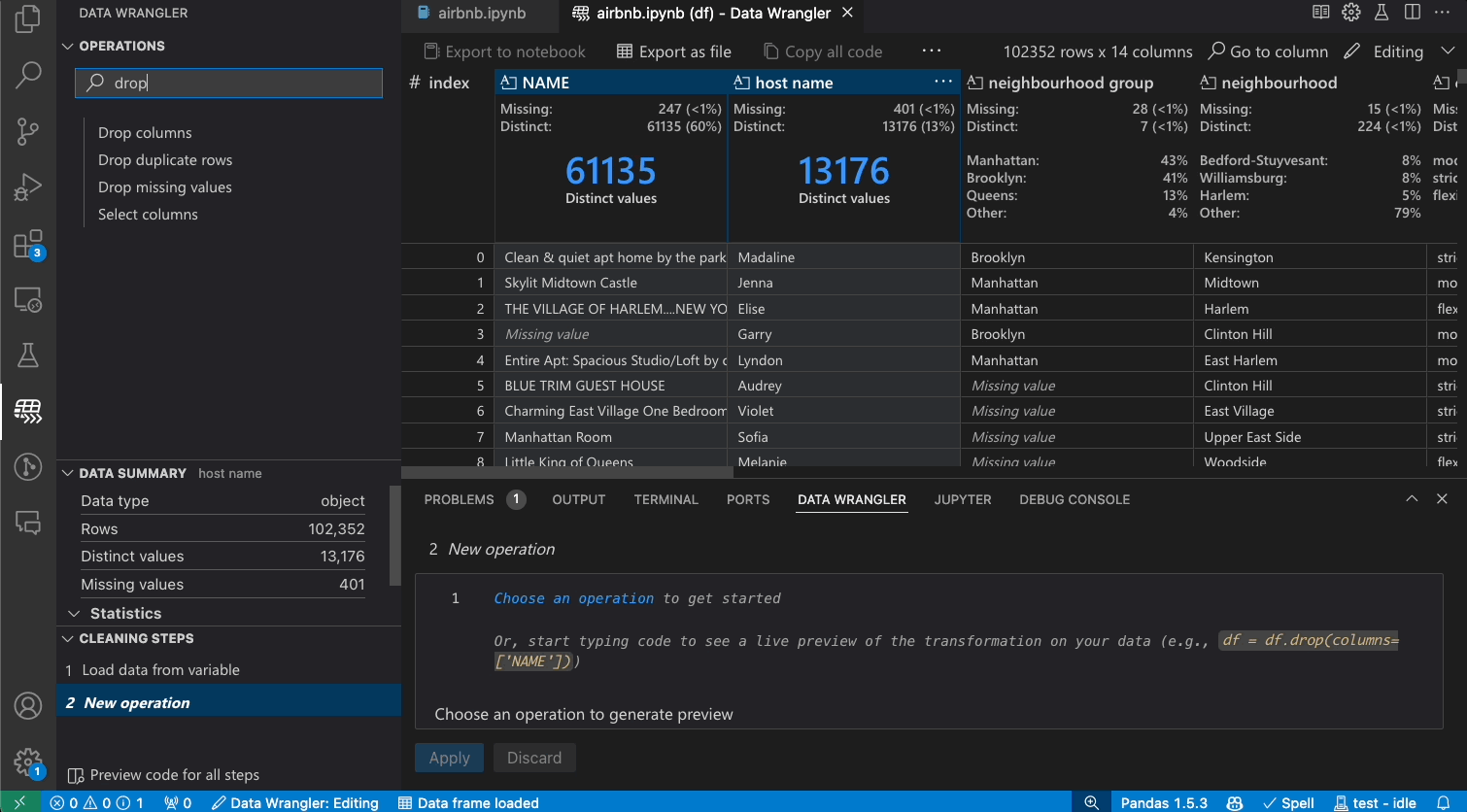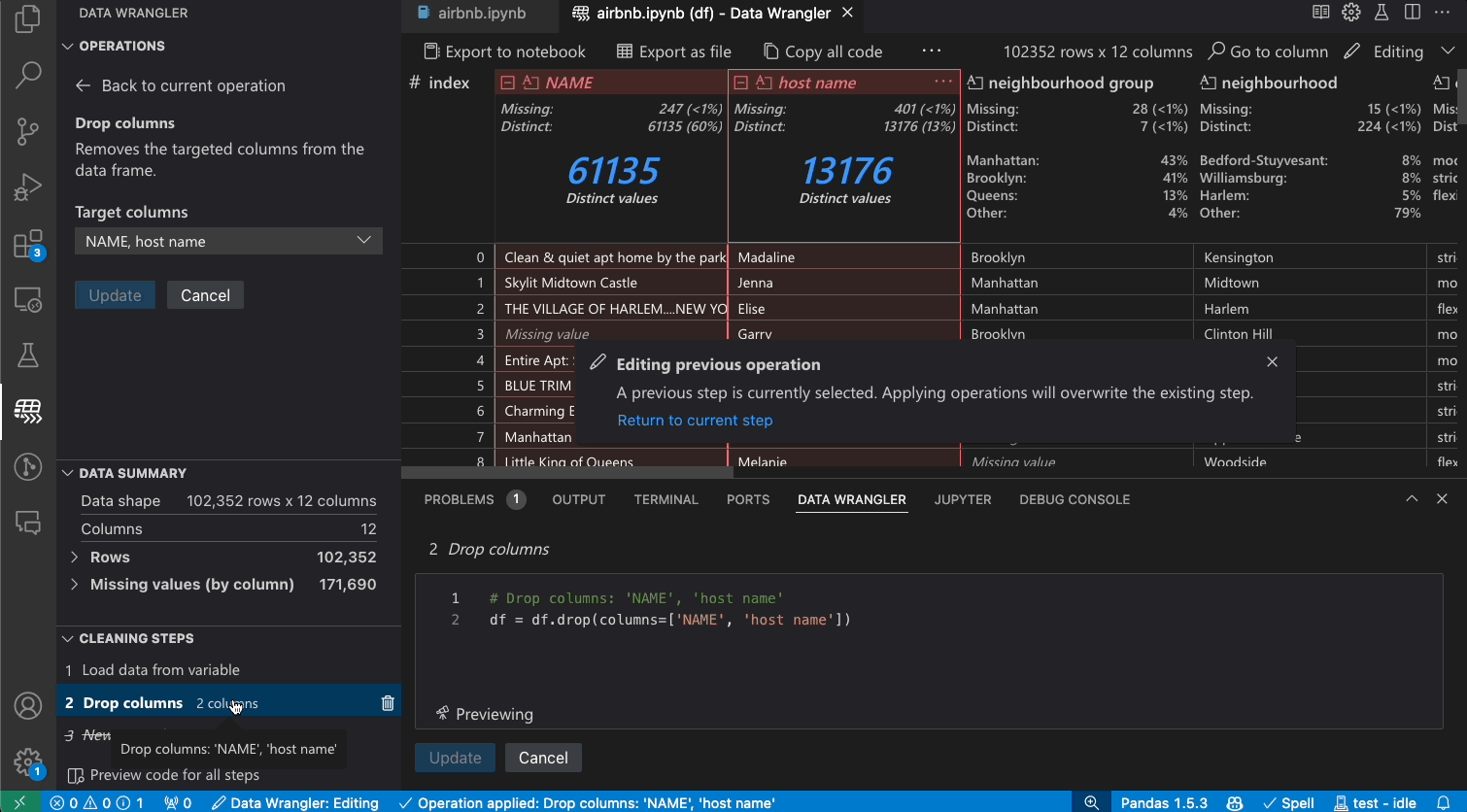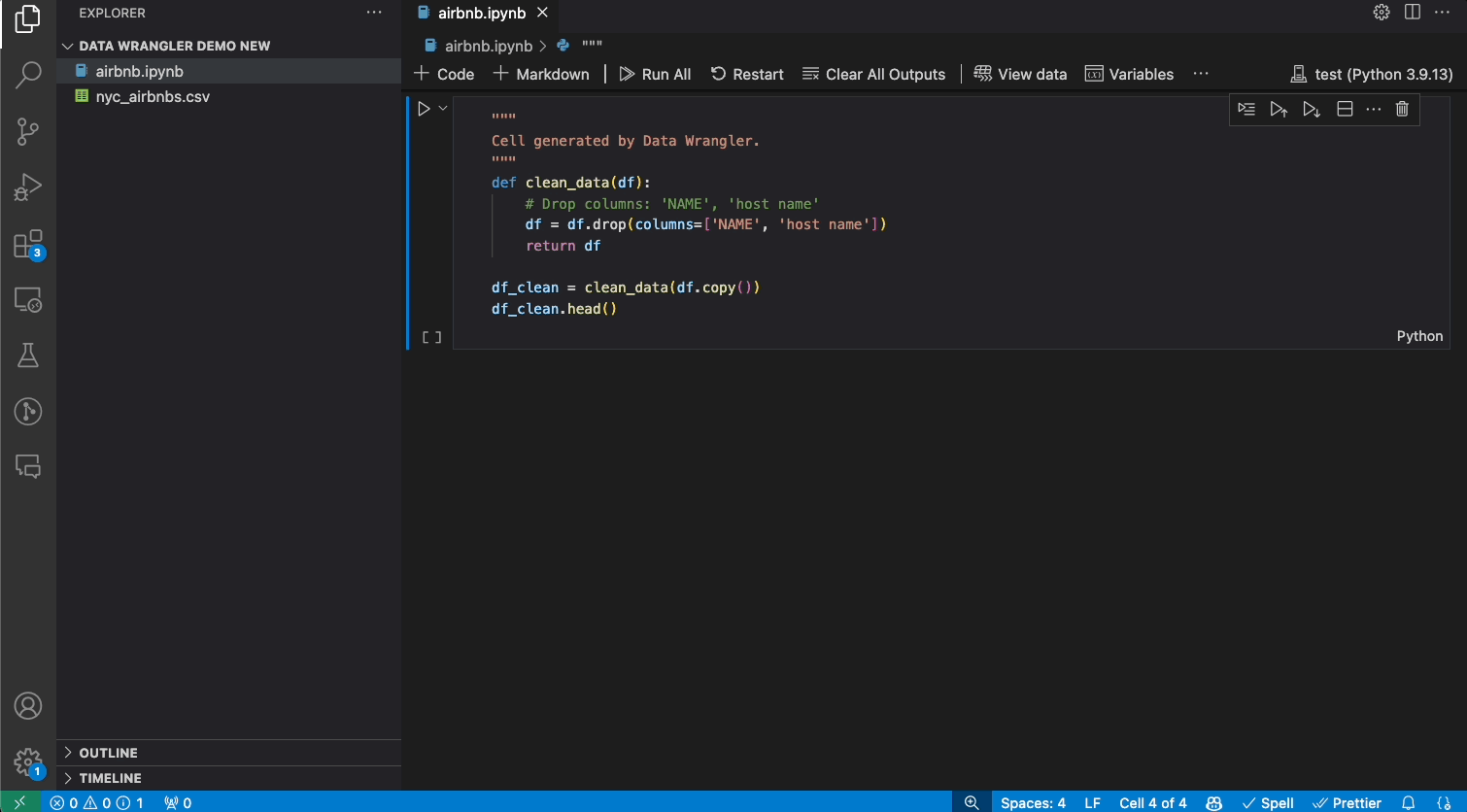
Once the Data Wrangler extension is installed, you can get to Data Wrangler in one of three ways from the Jupyter Notebook.

- In the Jupyter > Variables panel, beside any supported data object, you can see a button to open it in Data Wrangler.
- If you have a supported data object in your notebook (such as a Pandas DataFrame), you can now see an Open ‘df’ in Data Wrangler button (where ‘df’ is the variable name of your data frame) appear in bottom of the cell after running code that outputs the data frame. This includes df.head(), df.tail(), display(df), print(df), df.
- In the notebook toolbar, selecting View data brings up a list of every supported data object in your notebook. You can then choose which variable in that list you want to open in Data Wrangler.
Alternatively, Data Wrangler can also be directly opened from a local file (such as CSV, Excel, or parquet files) by right clicking the file and selecting “Open in Data Wrangler”.
Filtering and sorting
Data Wrangler can be used to quickly filter and sort through your rows of data.
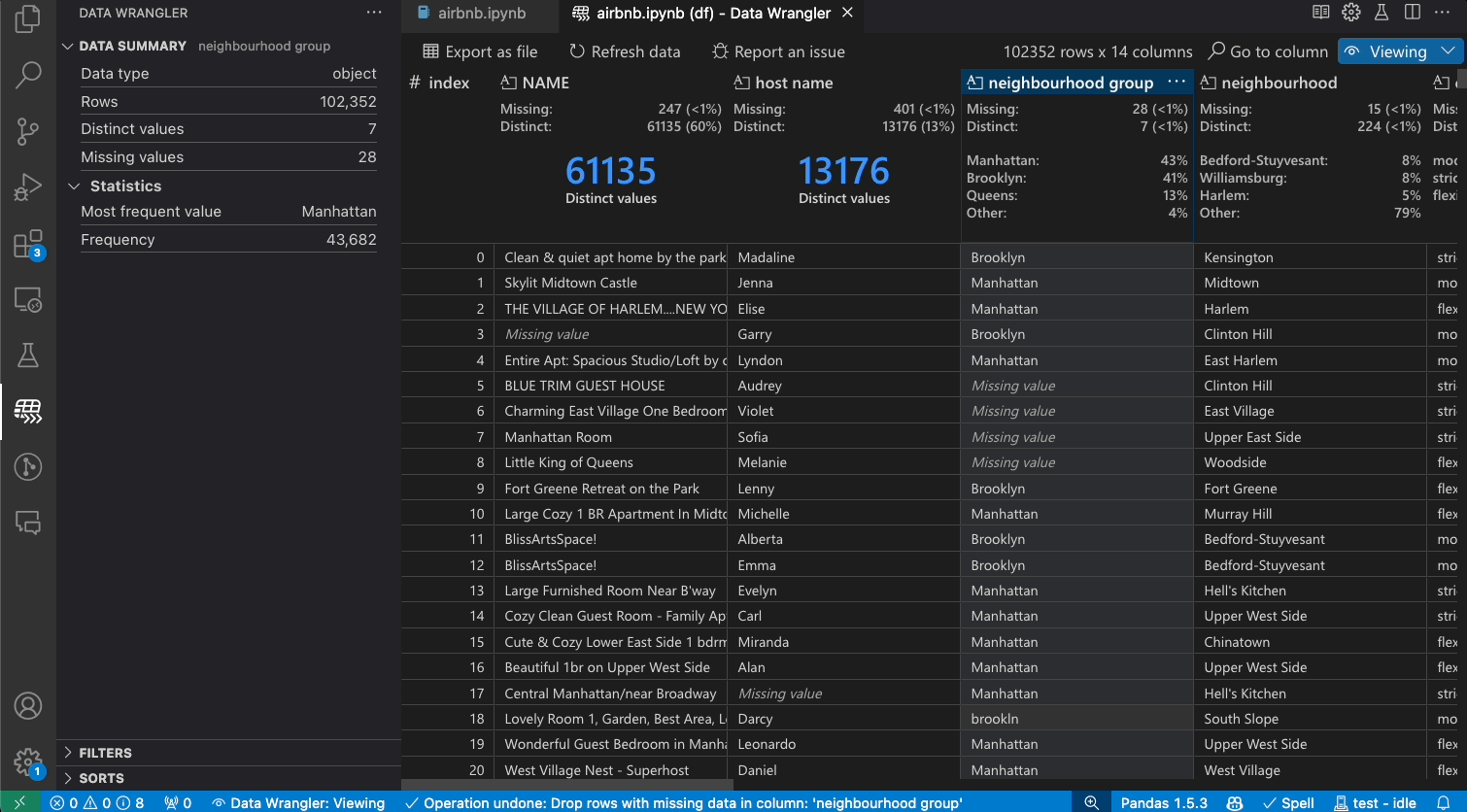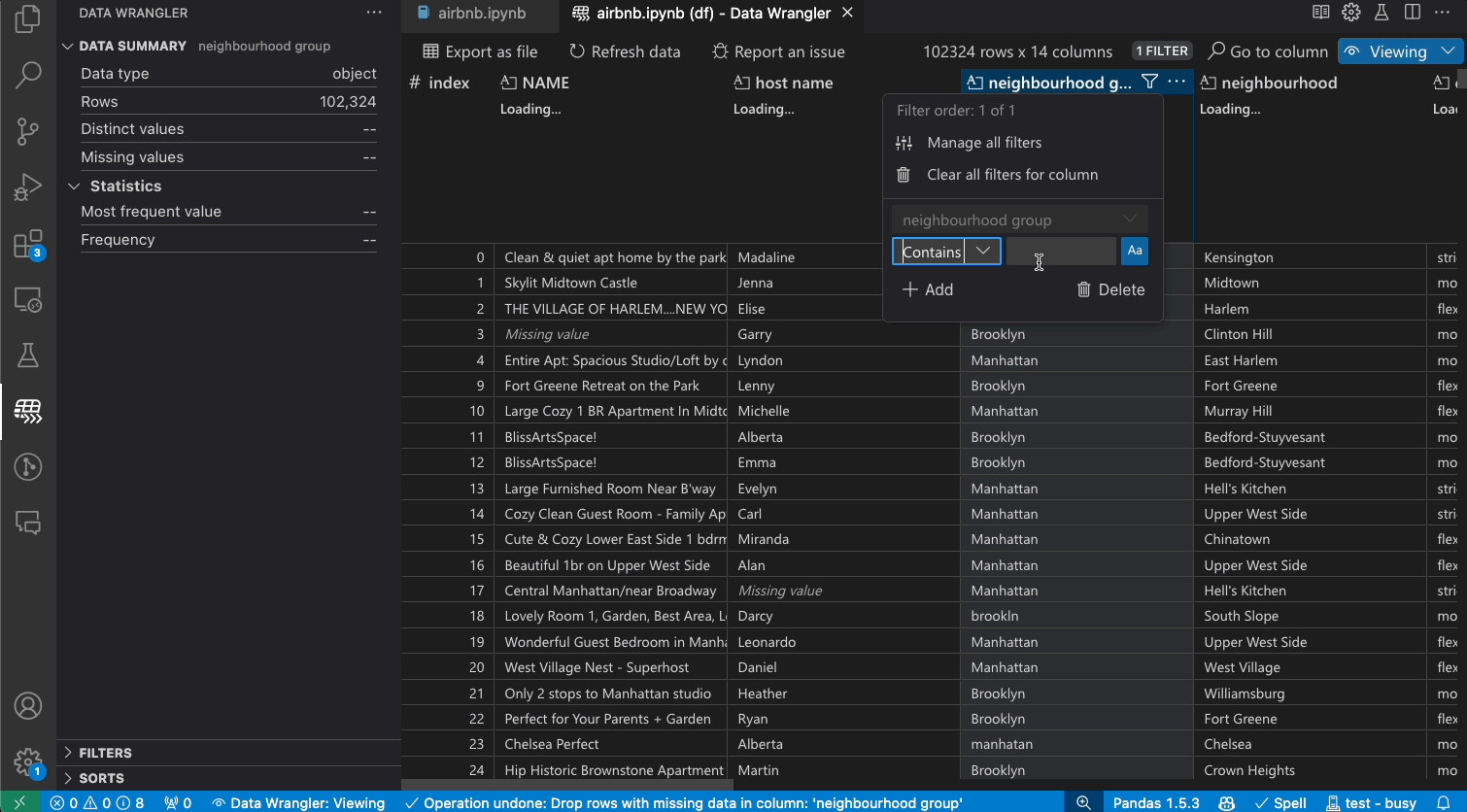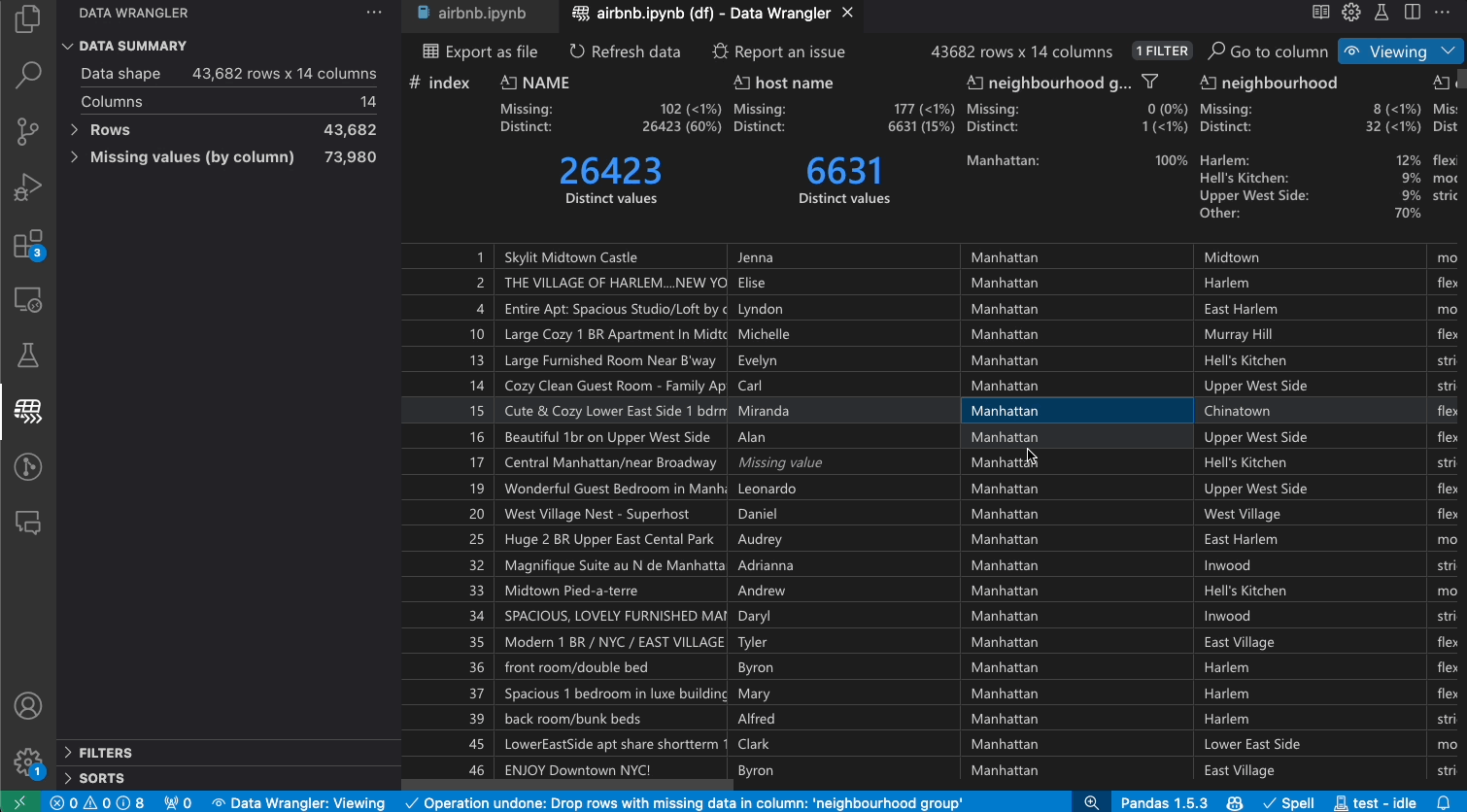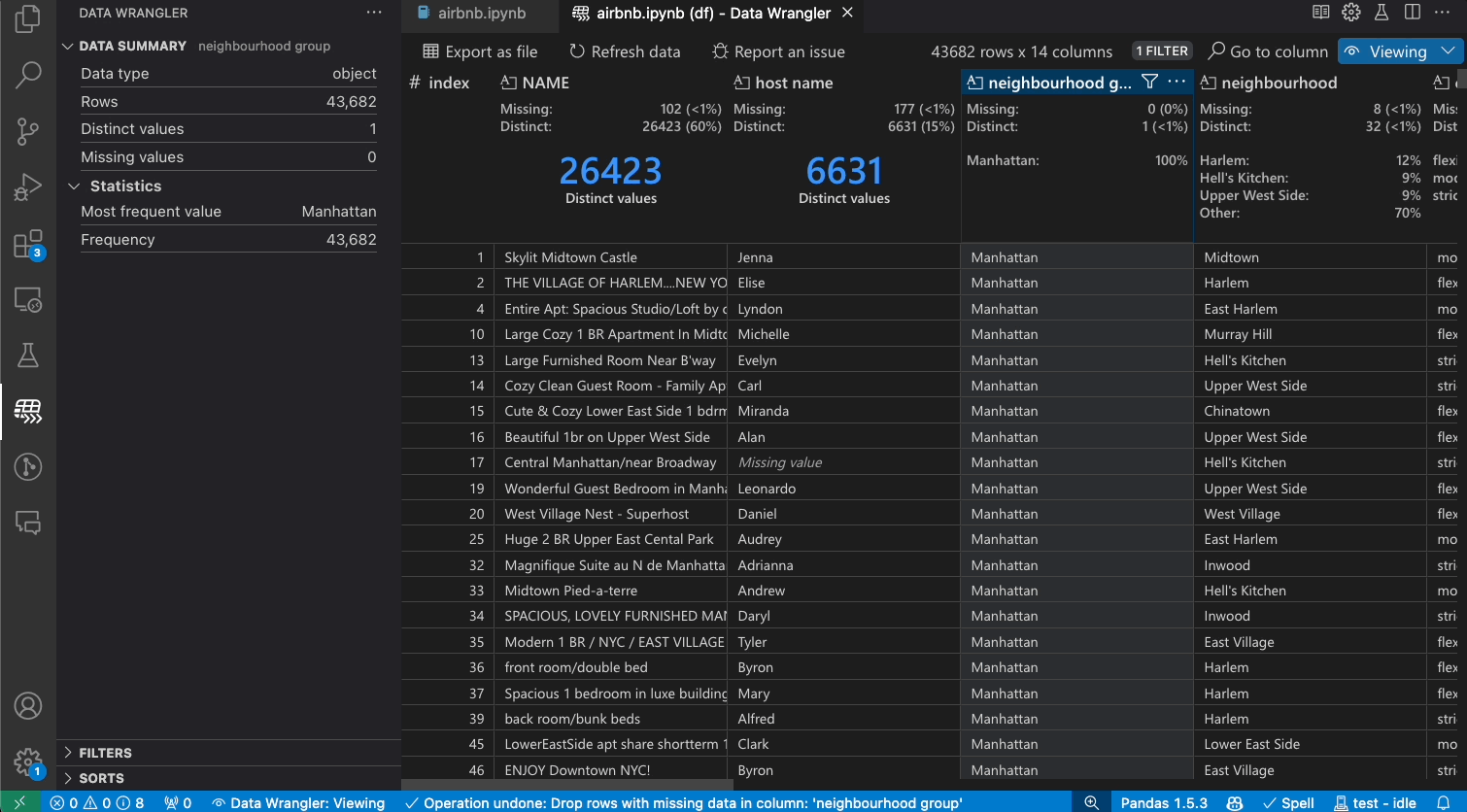
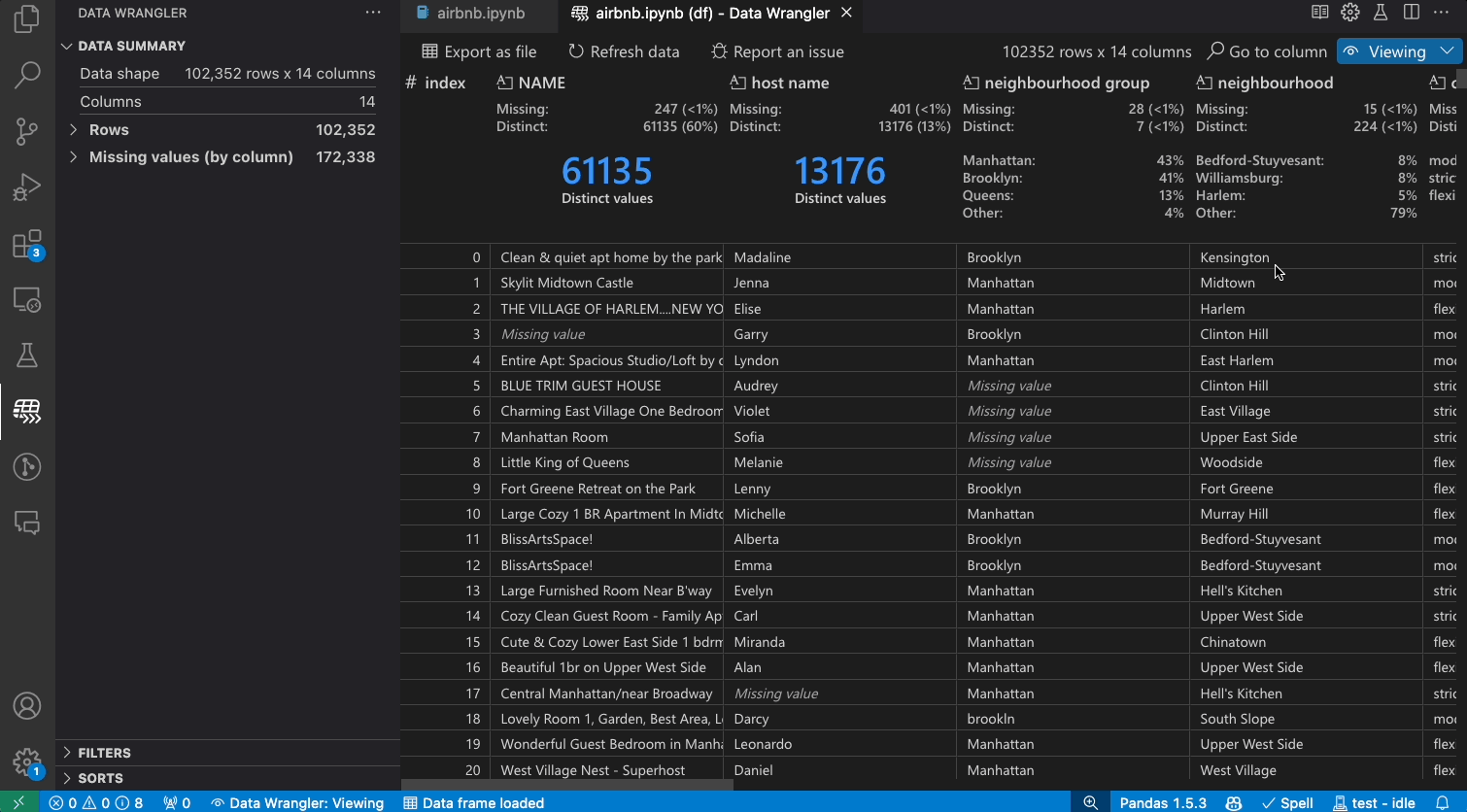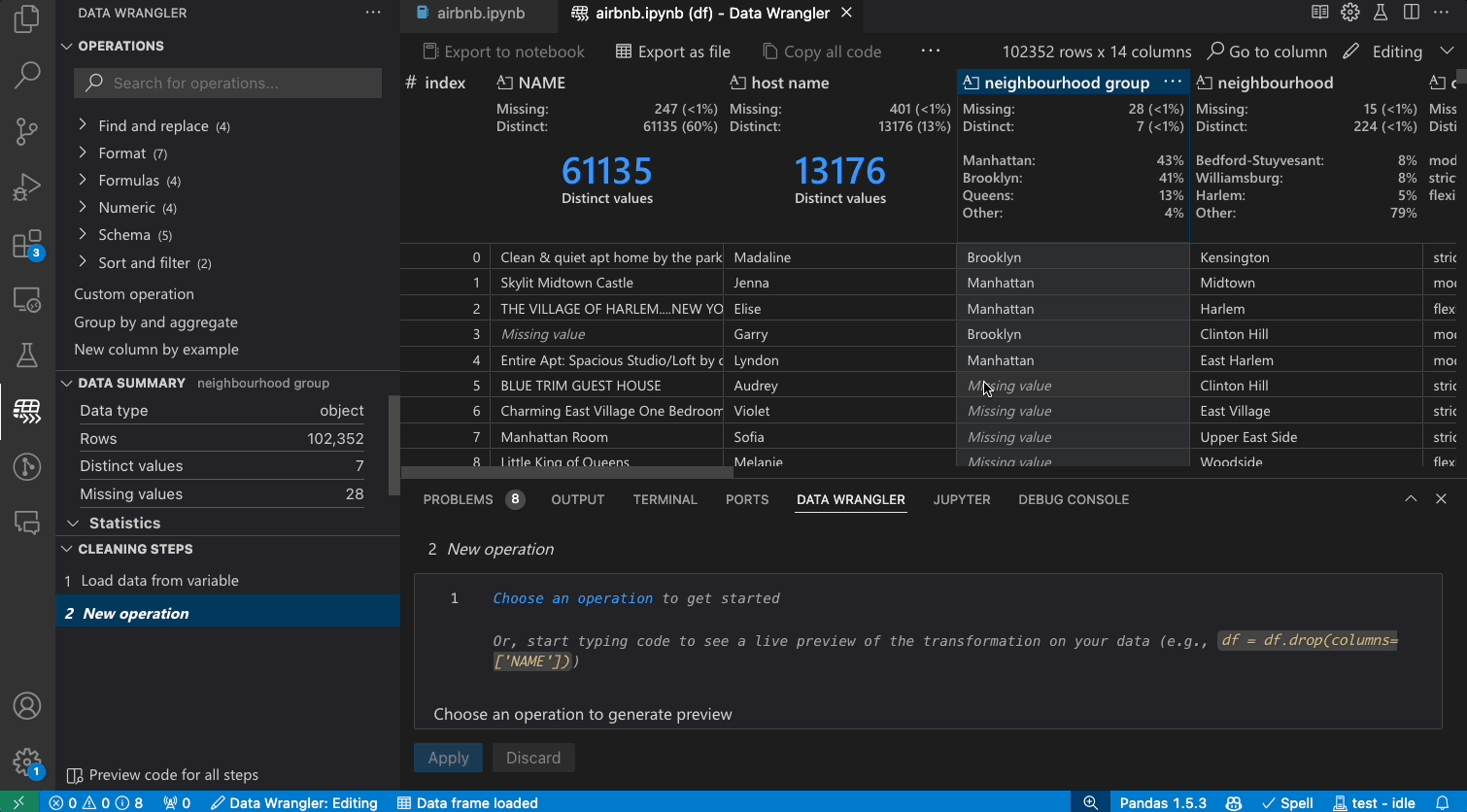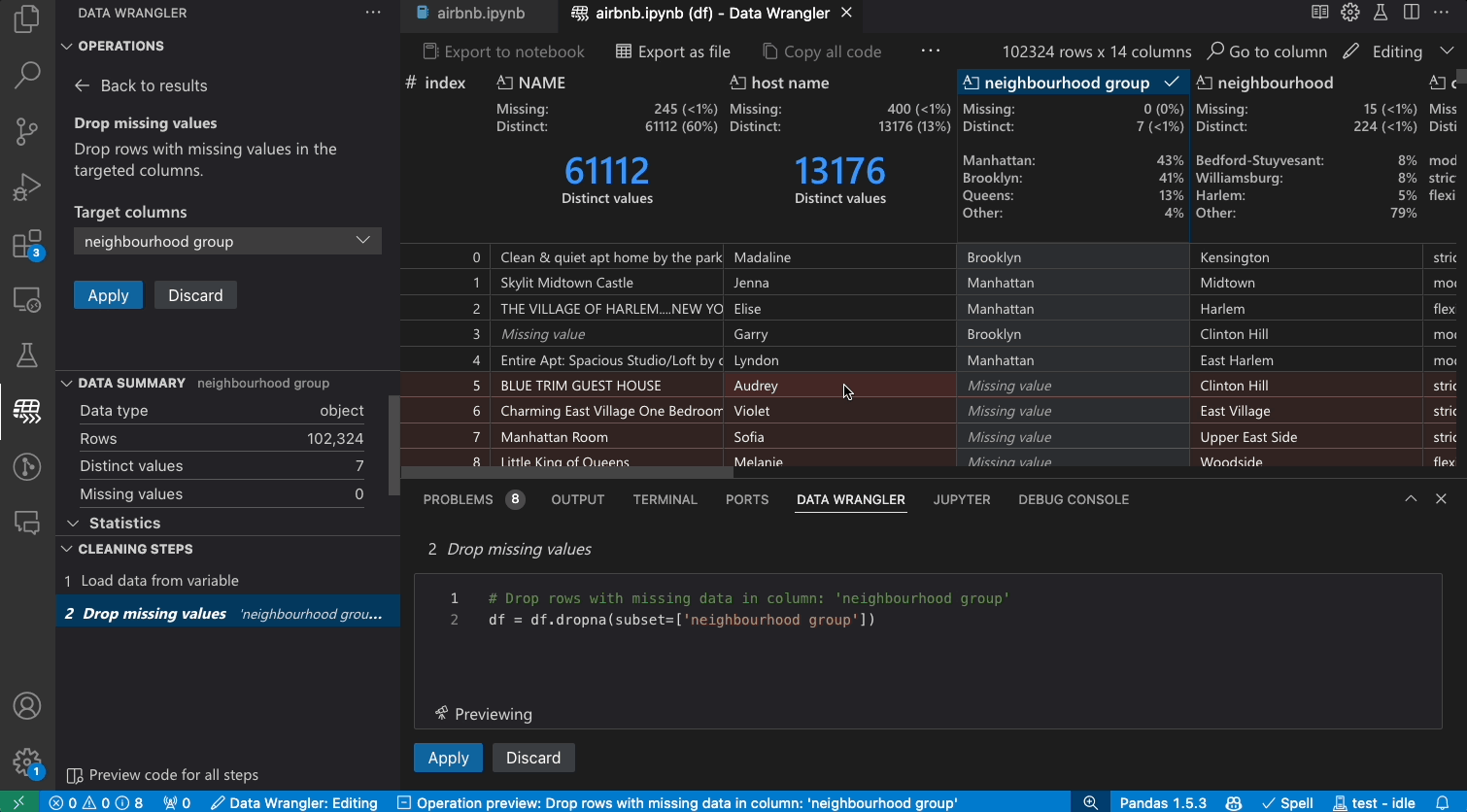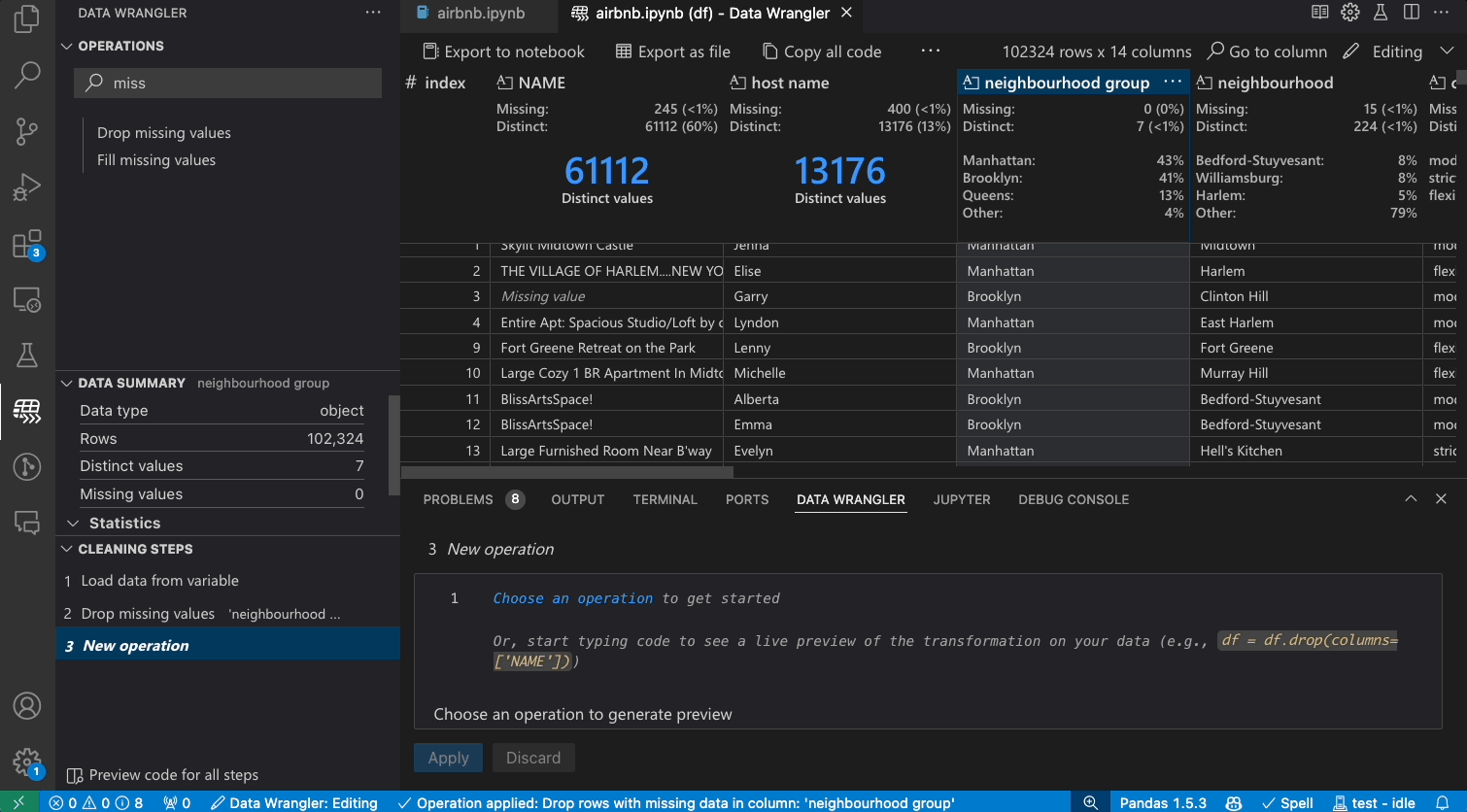
Transforming data
Switch from Viewing to Editing mode to unlock additional functionality and built-in data cleaning operations in Data Wrangler. For a full list of supported operations, see the documentation here.
Code generation
As you make changes to the data using the built-in operations, Data Wrangler automatically generates code using open-source Python libraries for the data transformation operations you perform.
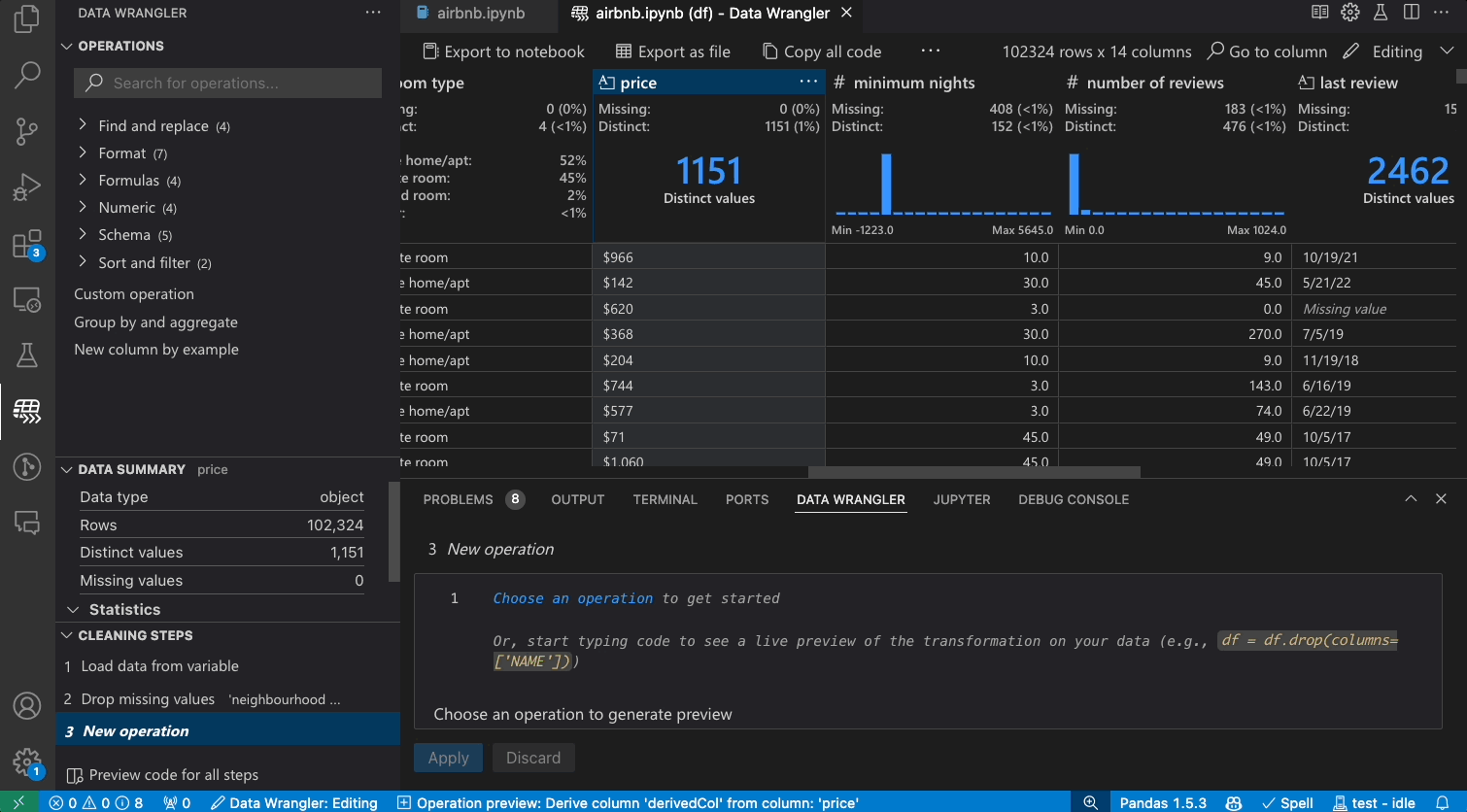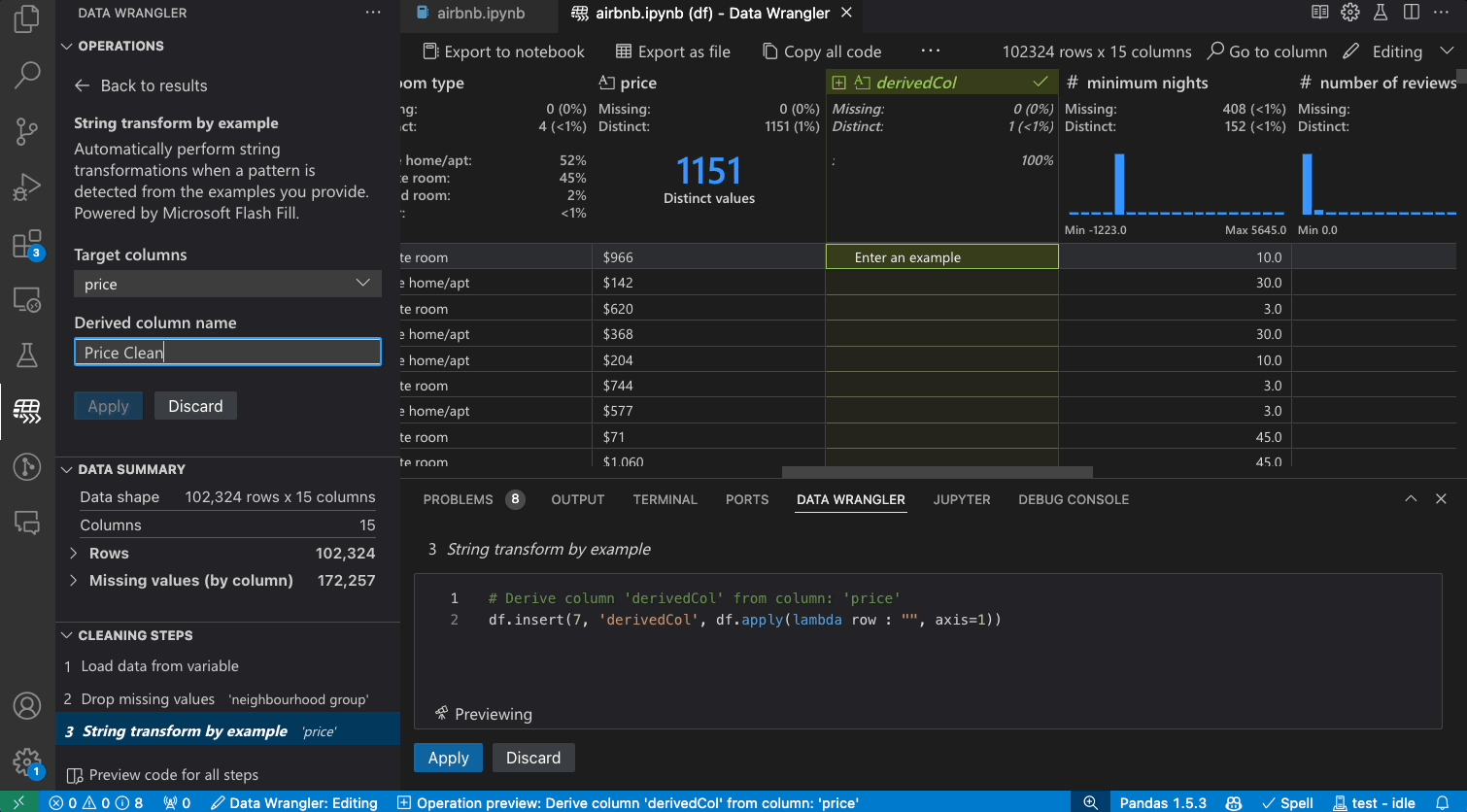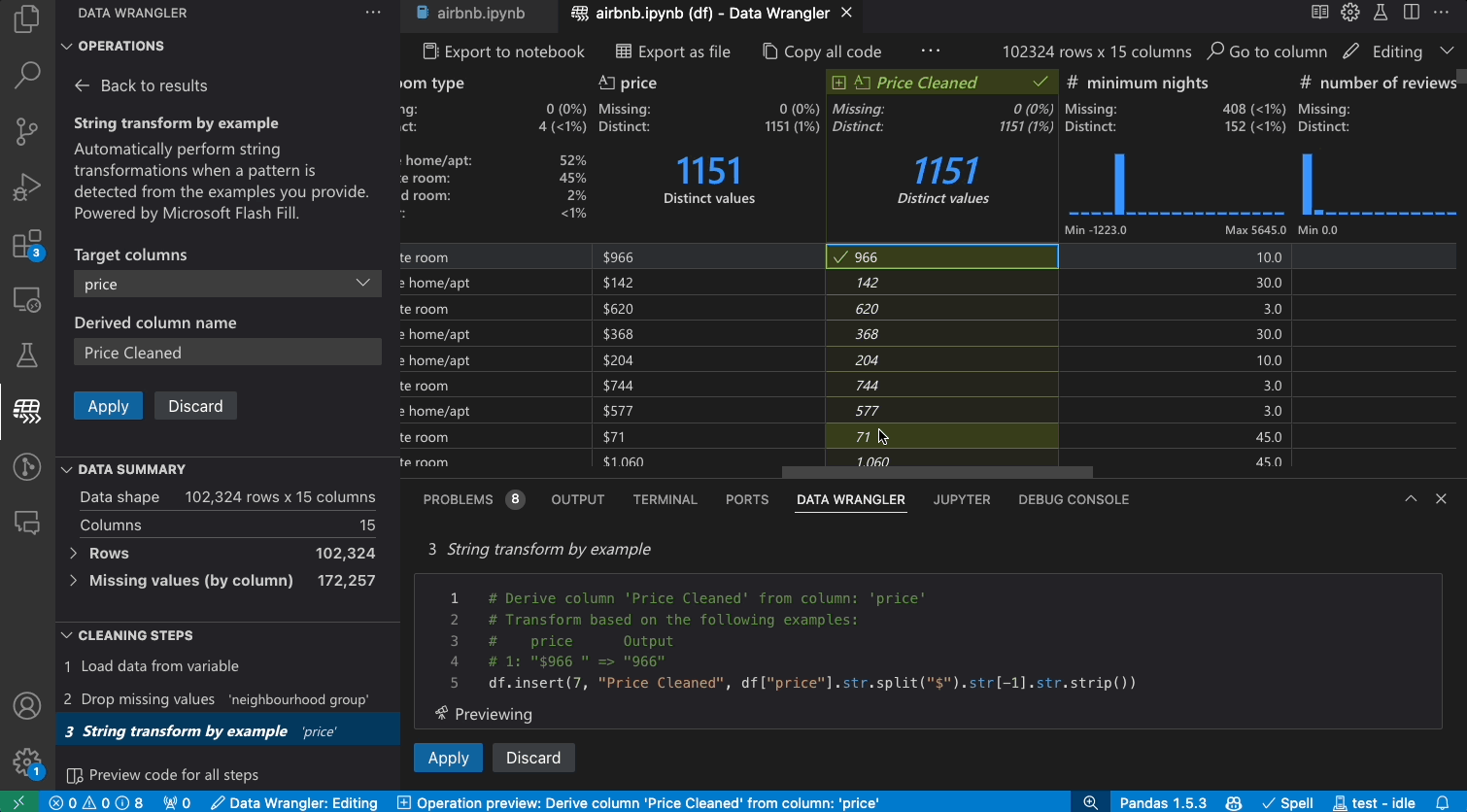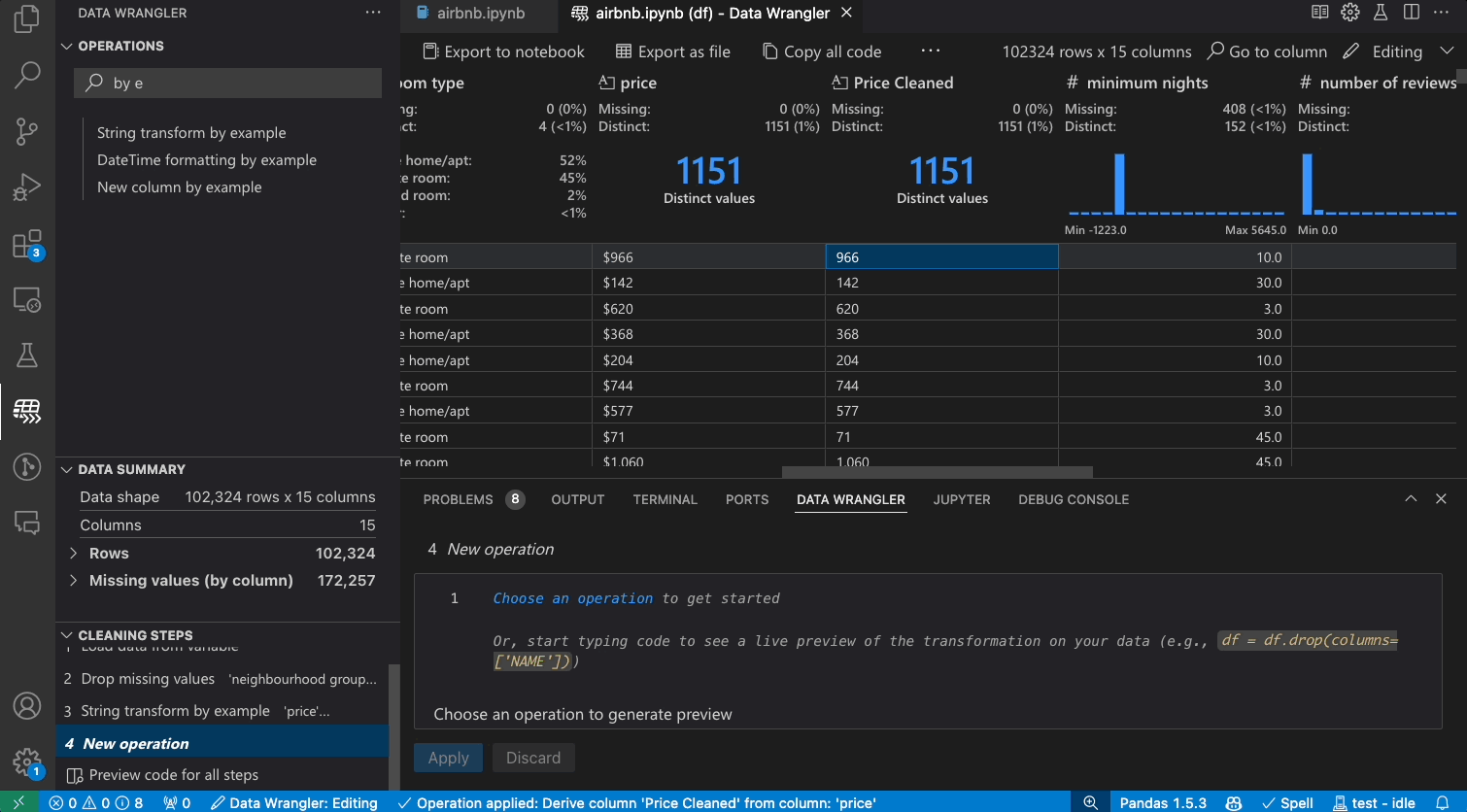
When you are done wrangling your data, all the automatically generated code from your data cleaning session can then be exported either back into your Notebook, or into a new Python file.
Trying Data Wrangler today
To start using Data Wrangler today in Visual Studio Code, just download the Data Wrangler extension from the VS Code marketplace to try it out! You can then launch Data Wrangler from any supported data object in a Jupyter Notebook or direct from a data file.
This article only covered some of the high-level features of what Data Wrangler can do. To learn more about Data Wrangler in detail, please check out the Data Wrangler documentation.
After reading this blog i am left clueless of what problem this extension tries to solve or what it does.
Hi schbaem! We’ve heard from data scientists that one of their top painpoints is the manual and tedious nature of exploratory data analysis. We built Data Wrangler to address those concerns by making it easier and more efficient for those data scientists to explore, analyze, and clean their data but providing built in data cleaning operations and richer interface to see the changes they make on their data. Thanks for the feedback.