
In this multi-part series, App Dev Manager Jon Guerin, Premier Consultants Daniel Taylor (@dbabulldog) and Jorge Segarra lay out some best practices around setting up and using In-Memory OLTP.
Recently a co-worker and I were approached by a team requesting assistance with In-Memory OLTP for SQL Server 2016. This is a continuation of our first blog post where we shared our best practices and thoughts around the following key decisions you will make when deploying the In-Memory OLTP solution.
- Part one of the series ( link to post 1 )
- Understanding the requirements for In-Memory OLTP features
- Usage Scenarios
- Planning
- Schema Durability
- Natively compiled Stored Procedures
As the In-Memory solution adoption continues to increase, we thought it would be beneficial to build on the best practices and cheat sheet items from our first blog post to help further frame out the conversations with our clients and show the value proposition of the In-Memory OLTP solution. This continues to be living document and one that will grow over time with additions to the solution and input from the community.
The best practices / cheat sheet has been broken up into the following areas:
- Part two of the series ( focus of this post )
- Indexing
- Memory Management
- Performance Considerations
- Backup and Recovery
- Monitoring
Setting expectations up front this best practices / cheat sheet is by no means an exhaustive post when it comes to In-memory OLTP. What is covered are the most common questions we have received to gain a better understanding of where to start when working with the In-Memory OLTP solution. An additional goal was not to type out verbatim what documentation already exist, but to highlight some of the top considerations and then provide links for you to dive deeper into the topic.
Indexing
- Start with nonclustered / ranged indexes then examine Hash Indexes for seeks
- Exist in Memory Only and are not persisted to disk * Exception to this are clustered columnstore indexes, to speed up databases recovery they are stored in checkpoint files
- Memory-optimized tables must have at least one index
- Primary Key is required for Durable In-memory table
- Inherently covering, all columns are virtually included in the index and bookmark lookups are not needed for memory-optimized tables
- Nonclustered hash indexes can yield performance benefits for point lookups
- Always fixed sizes
- Values returned are not sorted
- Nonclustered indexes can yield performance benefits for range and ordered scans
- Index count considerations
- Up to SQL Server 2016 Memory-optimized table could have up to 8 indexes. SQL Server 2017 and above has removed this constraint.
- Prior to SQL Server 2016 Indexes need to be added at the time of the table creation
- Apply only the indexes if they will be frequently used
- Old row versions on rarely used indexes can impact garbage collection performance
- Performance can be impacted if the index key has many duplicate values. Performance can be improved by adding an additional column to the nonclustered index
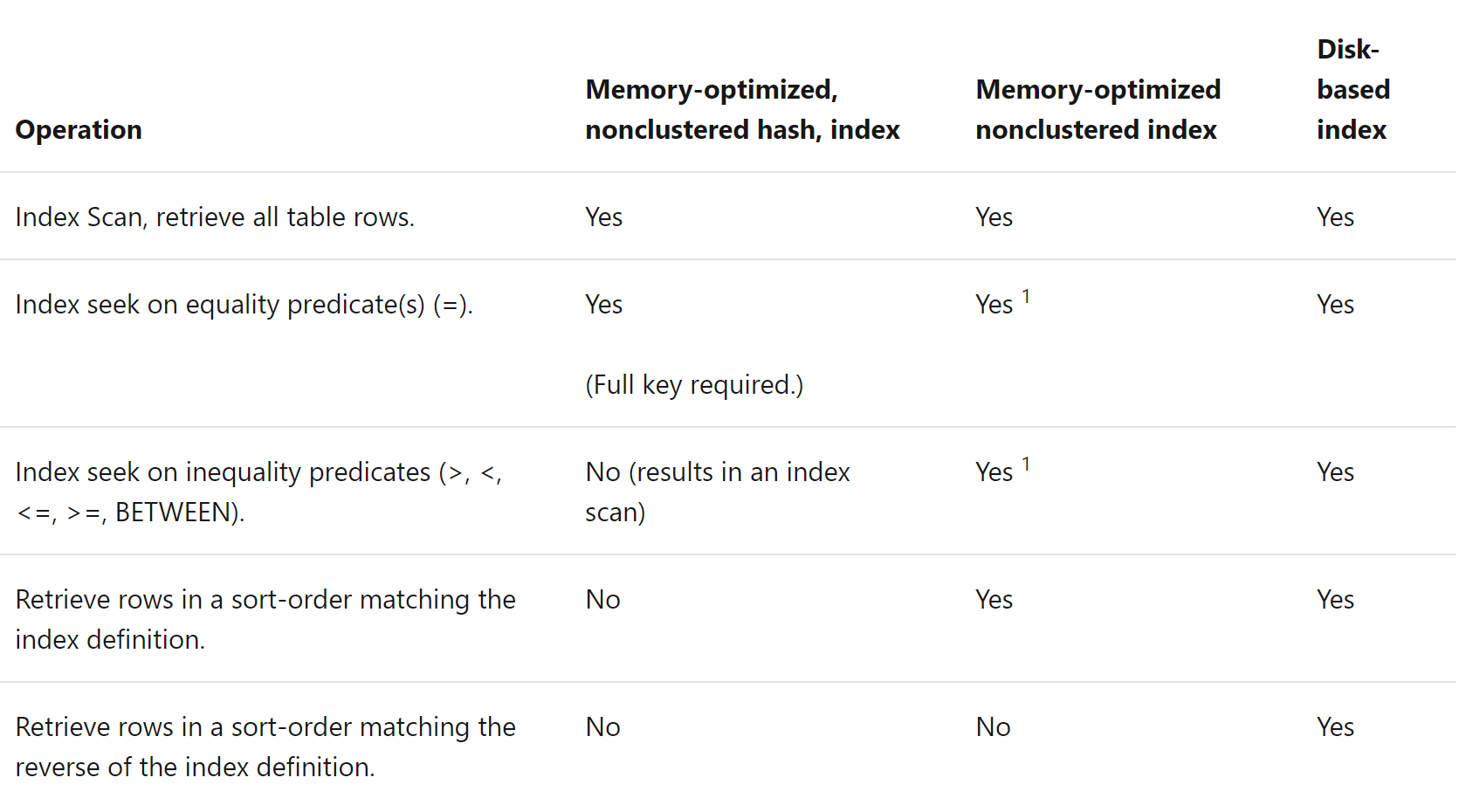
- Operations on memory-optimized and disk-based indexes
Memory Management
-
- Safe recommendation is to start with 2 times the memory
- Based off expected size of memory optimized tables and indexes
- Monitoring memory requirements for in-memory objects
- Memory-optimized size corresponds to size, data, and some overhead for row headers
- In-memory indexes tend to be smaller than disk-based indexes
- Nonclustered index size is in order of the [primary key size] * [rowcount]
- Hash indexes are [bucket count] * 8 bytes
- Bind database with in-memory tables to a resource pool ( Requires Enterprise Edition )
- Prevents memory pool buffer pressure that could affect disk-based table performance
- Must estimate how much physical memory required for in-memory tables
- Identify max memory percent for the resource pool which the database containing the in-memory tables is bound
- Provided is an example from the link provided above

- Safe recommendation is to start with 2 times the memory
- sys.dm_resource_governor_resource_pools will help provide accurate monitoring of the memory optimized tables if bound to a resource pool.
- Detailed guidance around estimate requirements for memory-optimized tables
Performance Considerations
- Plan and Optimize your Hash Index
- If you are expecting single value lookups
- If include more than one column in the key equality comparison must include all columns in the key
- Must define a bucket count
- OK to default high, but don’t overestimate
- Higher cardinality is a better candidate for a Hash Index
- Lower cardinality will create row chains which could lead to performance issues
- High confidence in the number of rows allows good estimated bucket count
- Bucket count for the primary keys is total number of rows
- Bucket count for non-unique and composite hash index is the total distinct keys
- Correct bucket count for hash indexes
- Storage considerations for In-memory OLTP
- Ensure that transaction logs can support additional IOPs for memory-optimized tables
- Each container should be typically mapped to its own storage device
- Ensure storage device can support sequential IOPs up to 3 times the sustained transaction log throughput
- Ensure storage supports recovery time for durable in-memory tables
- Maintain equal distribution of checkpoint files
- SQL Server 2014 – odd number of containers is required
- SQL Server 2016 and above – odd and even number of leads to uniform distribution
- Deeper insight into In-Memory Storage Configuration
- Process to improve load times during recovery to improve Recovery Time Objective
- Create delta map filters
- Creating multiple containers could help load performance
- One thread per container reads the data files and creates a delta map filter
- Streaming of the data files
- Data files are read by as many threads as logical CPUs
- This process could become CPU bound during recovery
- Advantage for Always On Availability groups modify memory-optimized data on the secondary replica. In the event of a failover data does not need to be re-streamed
- Failover Cluster Instances must restream memory-optimized data on a failover
- Process for improving load times
- Create delta map filters
- Garbage collection has issues with memory-optimized table variables. Row versions will only get cleaned out when the variable goes out of scope.
Backup and Recovery
- In-Memory filegroups can’t currently be deleted in any version of SQL Server. Defining a well-defined Recovery Point Objective (RPO) is key to preventing data loss in the event the database is marked suspect due to In-Memory objects. It is important to note that a well-defined RPO should be part of any database deployment.
- Database recovery is like disk-based tables, however memory-optimized tables must be loaded into memory before database is available
- In-memory tables adds an additional step to database recovery redo phase
- Data from data and delta pairs are loaded into memory
- Data is then updated with active transaction log from last durable checkpoint
- Factors that could impact the load times
- Amount of data
- Sequential I/O bandwidth
- Degree of parallelism
- Log records in the active portion of the log
- Database recovery will fail and become suspect if there is not enough memory
- Considering adding containers to improve database recovery
- Having delta maps can improve performance when reading data files and creating delta map filters
- Data file thread reads will use as many logical CPUs available which could become CPU bound
- Database recovery with In-Memory Tables
Monitoring
- Monitor In-Memory OLTP memory usage
- Best practice is to bind the database with in-memory optimized tables to a resource pool
- SSMS has provides a standard report to look at real time
- Programmatically track in-memory usage by using DMVs
- sys.dm_db_xtp_table_memory_stats – consumption for all user tables, indexes, and system objects
- sys.dm_os_memory_clerks – monitor all MEMORYCLERK_XTP account across the In-Memory OLTP engine
- Track In-Memory usage historically using the DMVs
- Allowing for postmortem analysis if performance issues were experienced
- Track In-Memory OLTP growth ensuring the resource pool has enough memory allocated preventing outages
- XEvent natively_compiled_proc_slow_parameter_passing can be used to find native compiled stored proc inefficiencies
- Mismatched types: reason=parameter_conversion
- Named parameters: reason=named_parameters
- DEFAULT values: reason=default
- Monitor disk space allocated to the In-Memory filegroup
As you find value in the post and feel like there are items that could be added or modified please let us know. We have enjoyed putting this together for you and look forward to seeing the In-Memory solution deployed into your on premises and Azure environments. Microsoft embraces a growth mindset and we are ever learning and open for feedback.
If you would like access the documents used to build this blog it can be found out on GitHub.
https://github.com/dbabulldog-repo/In-Memory-OLTP-Best-Practices-Cheat-Sheet
0 comments