
Azure Fluid Relay (AFR) is a globally available Platform-as-a-Service (PaaS) offering from Azure designed for building real-time collaborative experiences. The platform is built on a globally distributed set of servers, which helps minimize network latency and ensures compliance with geographic data regulations. AFR’s usage patterns can vary significantly depending on daily and weekly traffic fluctuations, as well as geographic factors, making active scaling of the underlying platform essential to optimize compute capacity. Designed using a microservices architecture, AFR leverages Azure Kubernetes Service (AKS) to host its workloads. This post explores the journey of identifying and fine-tuning the optimal Kubernetes autoscaling configuration for AFR.
Overview
Kubernetes offers autoscaling capabilities through two primary features: the Horizontal Pod Autoscaler (HPA) and the Cluster Autoscaler (CA), which are typically used together to achieve efficient autoscaling and cost savings. The HPA adjusts the number of pod replicas based on specified metric thresholds within a given range (defined by minReplicas and maxReplicas), aiming to keep the average value of these metrics within predefined targets. Meanwhile, the CA manages the number of nodes in the cluster to ensure there are sufficient resources for new pods to be scheduled and that unused nodes are removed to reduce compute costs. In our setup, the default values for CA parameters exposed by Azure Kubernetes Service (AKS) proved to be suitable, and we only needed to determine the minimum and maximum node counts. We set the minimum node count to 3 to ensure a sufficient level of redundancy in case of node failures. For the maximum node count, we used historical data to determine an appropriate value. For HPA, we used CPU and memory usage as the primary metrics, as they effectively represent the load of our AFR workloads based on incoming traffic. These metrics can be configured using either absolute values or resource utilization percentages. We chose utilization-based thresholds, as they are more flexible and adapt better to varying loads, though this assumes resource requests are defined correctly. After some experimentation, we settled on a utilization threshold of 70%, which provides a buffer to handle sudden traffic spikes that might exceed autoscaling’s immediate response capacity. Additionally, resource limits must be configured to prevent excessive resource consumption by individual pods, ensuring that no pod monopolizes available resources or disrupts overall cluster performance. Eventually, with the metrics and thresholds determined, identifying the optimal autoscaling setup comes down to tuning the correct values for resource requests, resource limits and maxReplicas — and this is where our journey began.
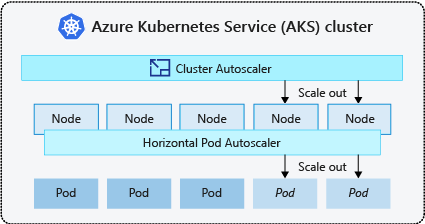
The first iteration (naïve approach)
While the official Kubernetes documentation provides good coverage of Horizontal Pod Autoscaler (HPA), there are few resources available on how to optimally configure the relevant parameters to balance compute cost and reliable service operation. To determine the right values for resource requests, resource limits, and maxReplicas, we had to take a trial-and-error approach. Our initial, naive configuration was to set resource requests based on the average resource usage observed over a period (a couple of weeks), and resource limits based on the maximum resource usage during that period. For maxReplicas, we simply used the value that was set before enabling autoscaling.
After deploying this configuration in a test environment, we quickly realized it was far from optimal and had a major flaw. Specifically, during peak hours, the HPA scale-out was not triggering a cluster scale-out, which led to resource starvation. Further investigation and analysis revealed that the issue was caused by the fact that, during non-peak hours, the cluster would scale in, reducing the node count to the minimum. When peak hours arrived, the underconfigured resource requests, combined with the unchanged maxReplicas (same value as before enabling autoscaling), limited the amount of resources being requested by the HPA scale-out to maxReplicas x UsageAvg. In reality, it required maxReplicas x UsagePeak resources to comfortably handle the peak load. As a result, the workloads were forced to scale up, causing each replica to consume significantly more resources than were available. This issue did not occur in our original configuration (before autoscaling), since CA was disabled, and the cluster node count remained fixed at the maximum value.
The second iteration (educated guess)
The failure of the first iteration prompted more intensive research into the topic, which led to valuable insights on how to configure resource requests and limits to ensure the reliable operation of pods. Specifically, a Kubernetes GitHub issue highlighted that the Kubernetes Vertical Pod Autoscaler recommends setting resource requests based on the P90 (90th percentile) of observed resource usage over time. This approach better reflects actual resource needs and provides a more reliable signal for CA to scale the cluster in sync with the resource demand generated by HPA scale-out, thus preventing pods from experiencing resource starvation.
Additionally, another insightful article recommended setting CPU limits to larger values (several cores, assuming your nodes have more than one core), particularly for Node.js-based applications, with the limit set above 1 core. Unlike memory, CPU is a “compressible” resource, and limiting CPU usage works differently. Allowing a resource limit greater than 1 core ensures that containers aren’t unnecessarily throttled when additional CPU cores are available.
It’s also crucial to set reasonably high values for HPA maxReplicas and the cluster’s maximum node count (e.g., 2x-3x the peak value). This ensures that during unexpected traffic surges, HPA and CA have enough room to scale out without service disruptions. Corresponding monitoring and alerting systems help detect such situations and identify any rogue behavior.
After applying these changes and testing the updated configuration, we found that the issues were resolved, and autoscaling functioned as expected. However, after monitoring the autoscaling operation for several weeks, we noticed that during off-peak hours, the downscaling didn’t reduce the number of nodes to the minimum, even though there was little to no traffic. A detailed analysis revealed the root cause of this behavior, leading to the third iteration of autoscaling configuration improvements.
The third iteration (targeting off-peak hours)
While analyzing the downscaling behavior during off-peak hours, we noticed that even though traffic was low and resource usage on the nodes was minimal, CA did not initiate a scale-in. To understand the reason, it’s important to highlight the criteria CA uses to trigger a scale-in and consider a node for removal. Several factors influence the CA scale-down process, which is thoroughly explained here, but a few key factors include:
- The sum of CPU and memory requests for all pods running on the node should be less than 50% of the node’s allocatable resources (this threshold is configurable in AKS).
- All pods running on the node (except those managed by daemonsets, which run on all nodes by default) must be able to be moved to other nodes.
With this in mind, we analyzed the resource requests at the node level and found that even when workloads were scaled down to minReplicas, the combined resource requests were still high enough to prevent the node from qualifying for scale-in. As part of the previous iteration, we had set the resource requests to the P90 percentile to address the issue of resource starvation. This helped us identify a potential solution: reducing the resource requests further and compensating by increasing the maxReplicas value.


However, reducing resource requests needs to be done carefully to avoid setting them too close to baseline usage (i.e., the resource usage level when there is no load). If the resource requests are too low, the HPA might continuously add replicas because the average utilization hovers around the threshold, and the new replicas don’t contribute to lowering the utilization. For CPU, this was relatively straightforward because the baseline usage was low (around 5m-20m), but for memory, there was limited room to reduce the requests, especially in high-traffic clusters.
To address this, we took an additional step. We realized that Azure offers a memory-optimized vCPU SKU, which provides twice the amount of memory compared to the regular vCPU SKU at a slightly higher cost. By migrating high-traffic clusters to this memory-optimized SKU, we effectively increased the target memory threshold (the 50% mentioned earlier), making it easier for the sum of memory requests on the node to qualify for scale-in. Testing this approach confirmed its viability, as it allowed proper autoscaling without disruptions.
As a result, reducing resource requests unblocked the scale-down of low-utilized nodes, enabling CA to scale in the cluster to the minimum number of nodes during off-peak hours. The removal of underutilized nodes during the scale-down process results in moving pods to the remaining nodes, achieving better utilization of their capacity. Ideally, to maximize cost-effectiveness, the node capacity utilization by resource requests should be close to 100%. An added benefit of this approach was improved resiliency, as the workload was distributed across more pods, reducing the impact in case of a pod failure.
Final thoughts
It is important to emphasize how tightly coupled the operations of HPA and CA are, and how crucial it is to correctly configure HPA for CA to function properly. Specifically, resource requests and maxReplicas must be defined in a way that accurately reflects the actual resource demands needed to handle peak traffic or load. Only by setting realistic resource demands based on actual usage can CA provision the appropriate amount of compute resources to meet that demand.
Theoretically, there are multiple combinations of resource requests and maxReplicas that can handle peak load, as long as the total resources (the product of the resource request and maxReplicas) are sufficient. The decision between using fewer replicas with higher resource utilization or more replicas with lower resource utilization depends on several factors:
- Resource Availability: If resources are limited, fewer replicas with higher resource utilization may be preferred to maximize the use of available capacity.
- Redundancy and Fault Tolerance: More replicas generally provide better fault tolerance. If one replica fails, others can continue to serve traffic. This is especially important for critical applications where downtime is unacceptable.
- Load Balancing: More replicas can help distribute traffic more evenly, improving performance and responsiveness, particularly during peak load.
- Scalability: For applications that need to quickly respond to sudden demand spikes, having more replicas can be beneficial, as it allows resources to scale out faster.
- Cost: Increasing the number of replicas can raise costs, particularly in cloud environments where you pay based on usage.
- Parallelization: More replicas increase parallelization, allowing more requests to be handled simultaneously, which can enhance throughput and efficiency.
Learn more
- Get Started with Fluid Framework 2.0
- HR Recruitment Fluid sample app using Presence and AI Collab libraries
- Fluid Sample app code using SharedTree and SharePoint Embedded
- For questions or feedback, reach out via Github
- Connect directly with the Fluid team, we would love to hear what you are building!
- Follow @FluidFramework on X (Twitter) to stay updated
0 comments