

In this post, we will learn how to leverage Git as a storage mechanism behind the globally available Azure Fluid Relay (AFR) service. AFR is an Azure-hosted implementation of the open-source Fluid Framework reference server, Routerlicious. This service is designed to facilitate real-time collaboration by ordering and broadcasting Fluid operations across connected clients.
Summaries and Git
To understand how we leverage Git, it’s essential to grasp the concept of summaries. Summaries are snapshots of the collaborative state at a given point. They allow us to efficiently manage and retrieve the state without replaying the entire history of operations. Conveniently, summaries are built and stored as blob trees, which are very similar to the data structures behind Git.
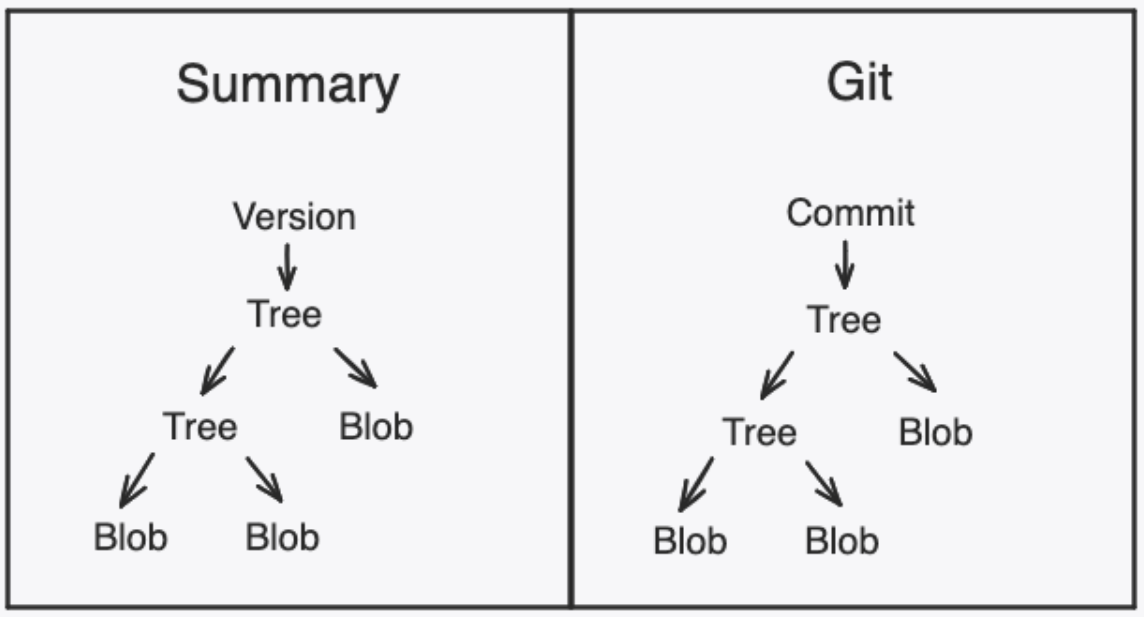
By using Git to store Fluid summaries, we get several benefits:
- 1:1 mapping of Summary Tree and Blob nodes to Git Tree and Blob objects.
- Immutability across summary versions.
- Efficient storage use by reusing blobs that do not change across versions.
To dive deeper into how we use Git for storing summary trees, look at the open source Gitrest service implementation.
Challenge 1: Scalability and reliability
While Git is excellent for version control, using it for long-term data storage at scale presents a major challenge: a high volume of data that needs to be managed reliably. As the number of collaborative sessions grows, so does the number of Git repositories and summary versions, leading to performance bottlenecks and rapidly increasing storage costs, particularly when using a local filesystem.
In the early days of AFR, Gitrest was deployed to a Kubernetes cluster along with 2 other key components: the GitSSH microservice and a Persistent Volume Claim (PVC). We then used the built-in Node.js filesystem module along with the nodegit package to store summaries as Git repositories in the PVC via local SSH through the GitSSH microservice.

As you can imagine, this didn’t scale well for a few reasons:
- Access to a particular container’s summaries was bound to 1 Kubernetes cluster forever. This is a complete non-starter for global scalability and reliability, especially regarding disaster recovery.
- Increasing the storage available in a Persistent Volume Claim can cause availability outages and scaling them out horizontally introduces the additional challenge of mapping containers to volumes.
- Gitrest pods couldn’t be reliably scaled out to handle increased traffic when they all had to be mounted to 1 PVC.
Solution: Scaling Git with Azure Blob Storage as a Filesystem

To address these challenges, we leverage Azure Blob Storage to scale Git summary storage globally by plugging a custom filesystem implementation using Azure Blob Storage APIs into the isomorphic-git package. This approach gives us the best of both worlds: the version control and immutability of Git along with the availability, scalability, and reliability of Azure Blob Storage.
Challenge 2: Performance and cost
Before we began migrating to Azure Blob Storage as a remote filesystem for Git summary storage, we ran some initial tests by uploading our codebase’s Git repository to Azure Blob. Immediately, we knew we had problems: network overhead and traffic volume.
Challenge 2.1: Network overhead
Uploading 1 large file to Azure Blob is very fast (milliseconds) but uploading hundreds or even thousands of smaller files sequentially is very slow (seconds). In practice, this means that summary read/write performance degrades proportionally to
a) the height and width of the tree, and
b) the physical distance between the Kubernetes cluster and the Azure Blob Storage datacenter
To understand why network overhead is such a big deal when using a remote filesystem in this way, you must understand a little about how isomorphic-git works out-of-the-box. A Git tree must be written bottom up, as files are named as a SHA value of their contents. Specifically, a tree referencing a tree and a blob must be written after the child tree and blob have their SHA values computed. To compute those, we write them to storage using the isomorphic-git writeTree and writeBlob APIs, which incidentally involves writing the files to Azure Blob. From here, you can see how a tall tree can involve many sequential layers of writing to storage, thus amplifying the impact of network overhead and latency.
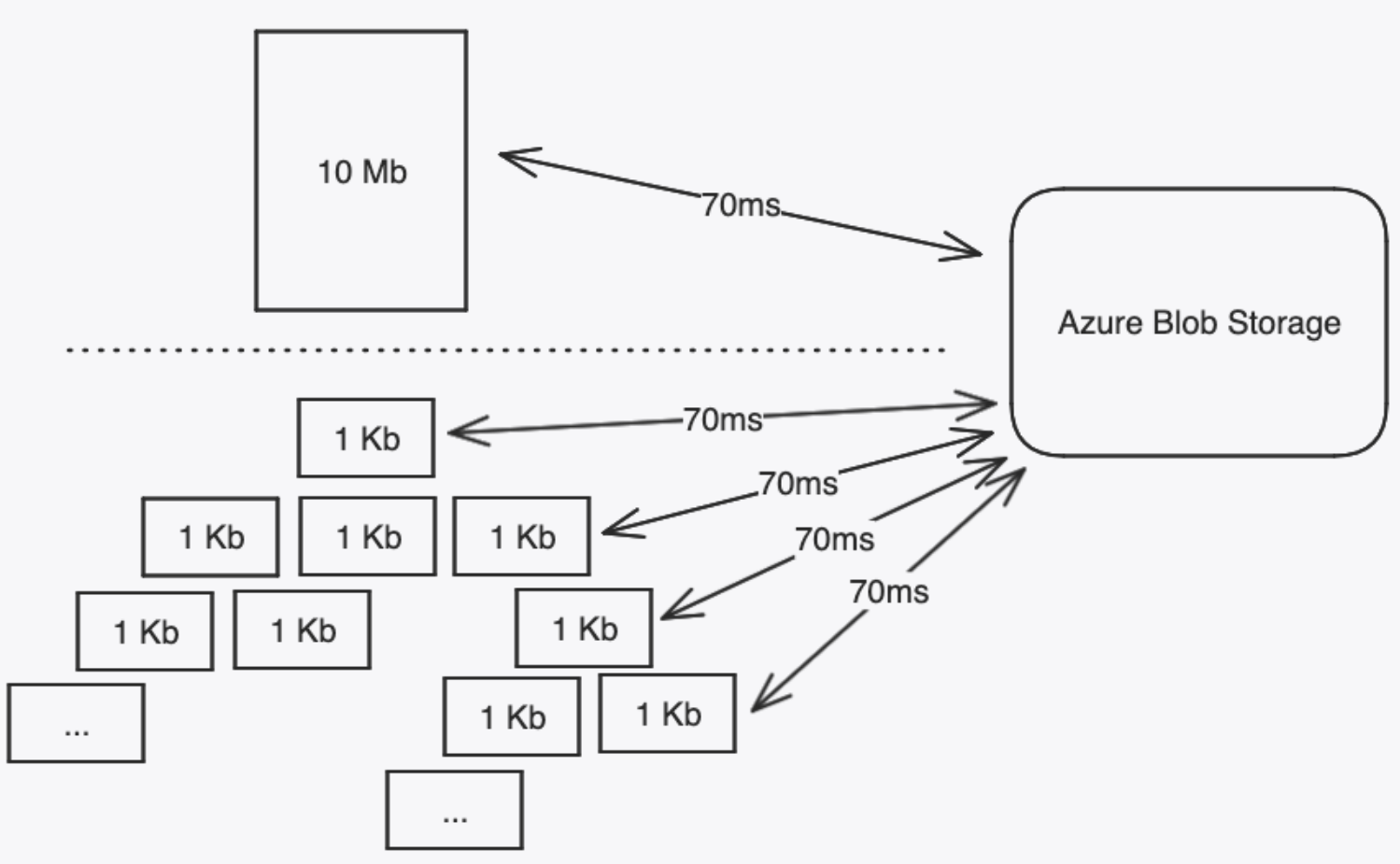
For example, if network latency is 10ms for a file, then storing a tree of height 10 takes 100ms; however, if latency is 70ms, writing the same tree would take 700ms.
Note: it takes ~70ms for a network packet to cross the United States from coast to coast.
The obvious solution here is to perform all SHA hash computation locally, then write all files to storage in parallel. Then, the network latency would no longer stack with itself. Unfortunately, network overhead was not the only problem here.
Challenge 2.2: Traffic volume
Azure Fluid Relay serves millions of collaborative sessions per day, which means a lot of new summaries. Even at the highest performance, premium dedicated tier of Azure Blob Storage, we were quickly running out of storage access allowance across our many Azure Storage Accounts. That meant we were sending so many requests that we could no longer, even temporarily, mitigate this scalability bottleneck with additional provisioning (i.e. money). Thankfully, we knew this day would come and had already been experimenting with workarounds. Enter: Low-IO Write
Solution: Low-IO write mode
To address the issue of exceeding storage access limits in Azure Blob Storage, the current workaround involves computing the entire Git summary in memory first. This is achieved by using the isomorphic-git package in conjunction with memfs, a memory-based file system, to create a single JSON filesystem payload for each summary, which is then stored with a commit and tree pointing to it. By handling the Git filesystem computation of the summary tree in memory, we minimize the network overhead and traffic volume that typically comes with writing multiple blobs to storage.
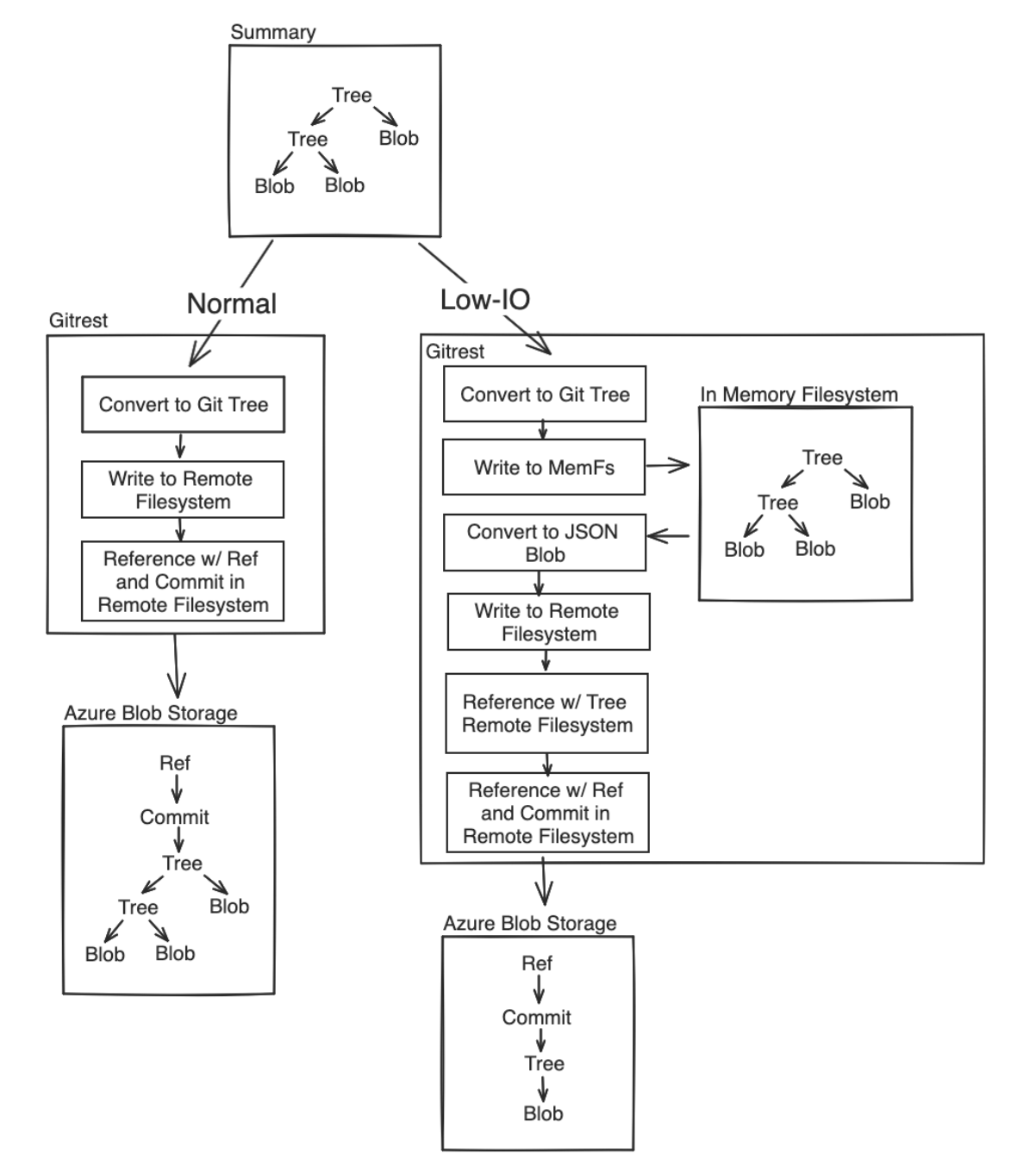
As a result, the number of blobs written to Azure Blob Storage for each summary is significantly reduced, down to just four key components: the ref, commit, tree, and single memfs blob. This streamlined approach leads to fewer storage access requests and helps to alleviate the scalability bottleneck associated with high traffic volume.
Trade-offs
However, this method introduces a couple substantial trade-offs: decreased storage efficiency and increased memory usage. Since each summary is freshly computed and stored as new blobs, it prevents the reuse of unchanged blobs from previous summaries. This leads to an increase in cost for the additional required storage capacity. Also, because we must build a fully self-contained Git file system every time, we must load the previous summary into memory to allow the new Git tree to reference previously written, unchanged objects. This leads to an increase in the cost for memory capacity within the Gitrest service.
Despite this downside, the overall storage costs are still reduced. The savings stem from the decreased volume of access requests, which vastly outweighs the minor increase in capacity. This balance between increased storage capacity costs and reduced access volume ultimately results in a net reduction in total storage expenses for the Azure Fluid Relay service, not to mention the additional room for scalability.
Future work
Going forward, we hope to find a feasible solution to performance and cost challenge that does not have as many major trade-offs as the Low-IO write solution. However, in the meantime we are continuing to leverage our current solution’s extensibility to power other needs, such as using Redis as a remote filesystem to store ephemeral containers.
Fluid Framework 2 is production-ready now! We’re excited to see all the collaborative experiences that you’ll build with it.
Visit the following resources to learn more:
- Get Started with Fluid Framework 2
- Sample app code using SharedTree DDS and SharePoint Embedded
- Connect your app to Azure Fluid Relay for production workflows
- For questions or feedback, reach out via GitHub
- Connect directly with the Fluid team, we would love to hear what you are building!
- Follow @FluidFramework on X (Twitter) to stay updated
0 comments