
A few years ago, I visited two very interesting countries, Vietnam and South Korea. Being actively involved in writing software (mostly RichEdit) for editing the world’s scripts, I was naturally fascinated to see Vietnamese and Korean text displayed in profusion. The Vietnamese and Korean scripts were designed with a common purpose in mind: enable the languages to be read and written easily by all members of their respective countries. Earlier on, people tried to write Vietnamese and Korean by customizing the Chinese script. But while the Chinese script is well suited to Chinese languages, it’s considerably less suited to Vietnamese and Korean. Accordingly, only a small percentage of the Vietnamese and Korean people were able to read and write their languages using the Chinese script.
In Vietnam in the 1500’s and 1600’s, Portuguese and French missionaries wanted to be able to read and write Vietnamese and to communicate with the Vietnamese people in writing as well as verbally. To this end, they chose a Latin alphabetic script with the letters a..z, đ, â, ă, ê, ô, ơ, ư plus the corresponding upper-case letters and five tone marks ̀ ́ ̃ ̉ ̣ (acute, grave, tilde, hook, and dot below, defined in the Unicode U+0300 block) for a total of 134 characters. This alphabetic script represented the Vietnamese language phonetically. The traditional Chinese orthography continued to be dominant until the early 1900’s, when the alphabetic script took over. In Vietnam today you still see Chinese characters, but mostly on old buildings and manuscripts. The vast majority of Vietnamese text uses the alphabetic script. All 134 characters were encoded in Unicode 1.1 (June 1993). Initially people used 8-bit code pages such as 1258 to encode the Vietnamese characters. But since Unicode has all the characters, it’s much more efficient to use them.
The default Windows 11 Vietnamese keyboard encodes the tone marks as combining marks in the U+0300 block instead of using the fully composed characters. This requires complex-script shaping, which slows down the display. Admittedly shaping engines can perform other useful tasks such as kerning and ligature formation, yielding finer typography. And a Vietnamese tone mark applies to a whole syllable, so it doesn’t have to be placed where a fully composed vowel has it. But web sites such as Wikipedia use fully composed Unicode characters. In Windows 11 you can install the Telex and/or the VNI keyboards, which have slicker ways to enter Vietnamese characters and insert fully composed characters. VNI’s option of automagically inserting the accents is particularly intriguing. To use one of these methods, press Windows > Settings > Time & Language > Language & region > Add a keyboard and add Vietnamese. Click on the Vietnamese keyboard Options “…” and you can choose a more advanced Vietnamese keyboard from the drop-down menu
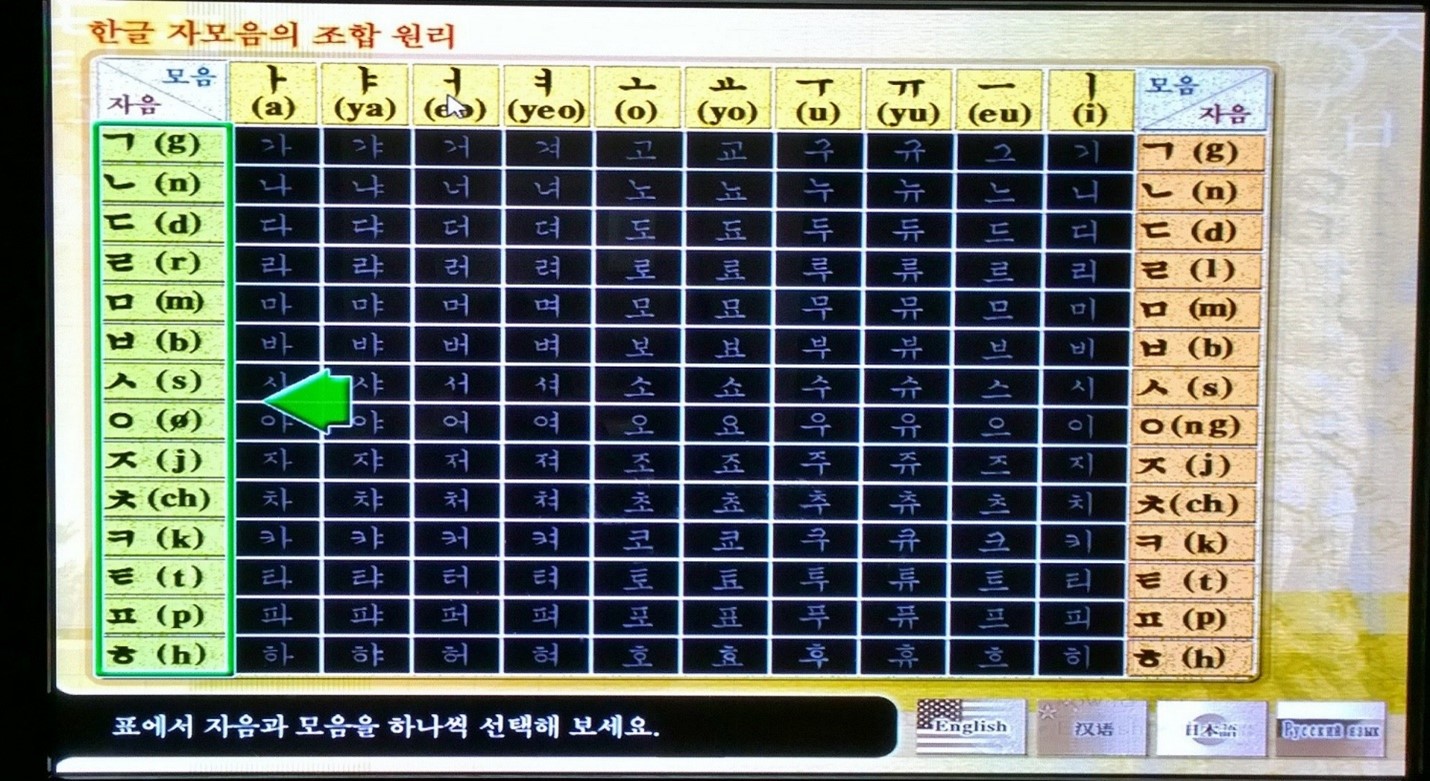
While foreign missionaries were responsible for the Vietnamese script, King Sejong of Korea was responsible for the Korean script. His motivation was essentially the same as the European missionaries’: make it easy for all Koreans to read and write their language. His original script published in 1446 had only 24 characters, called jamo, as shown in the following picture taken of an interactive display in the National Palace Museum of Korea in Seoul.
Modern Korean requires more: 19 initial consonants (C), 21 vowels (V) and 27 final consonants (T). The final consonants include most of the initial consonants and add some others. The jamo are displayed in boxes called Hangul syllables. There are 19×21 CV combinations and 19×21×27 CVT combinations for a total of 11172 possible Hangul syllables in modern Korean. The jamo are encoded in the Unicode U+1100 block (C—U+1100..U+1112, V—U+1161..U+1175, T—U+11A8..U+11C2) and the 11172 Hangul syllables are encoded from U+AC00..U+D7A3 in CVT sort order (T varies fastest, C varies slowest).
If you look at the Unicode U+1100 block, you’ll notice it’s full: 256 jamo! That’s more than 19 + 21 + 27. The major difference is the inclusion of many old Hangul jamo that are not used in Modern Korean. Modern Korean can be handled as a simple script: just use the Hangul symbols for which no glyph shaping is needed. In contrast, Old Hangul has many more combinations and needs to have a shaping engine to place the jamo correctly. The Unicode Standard explains how to do this in Chapter 3, Section 3.12 Conjoining Jamo Behavior.
Some interesting Unicode Hangul history. Non-combining jamo (U+3130..U+318F) and 2350 Hangul syllables (U+3400..U+3D2D) were part of Unicode 1.0 (October, 1991). Unicode 1.1 (June 1993) added the modern combining jamo (U+1100 block) and 4306 more Hangul syllables. The Korean government wanted the remaining 11172 – 4306 – 2350 = 4516 syllables of Modern Korean to be added as well and preferably to collect all the syllables in a single block. I had just joined the Unicode Technical Committee (over 26 years ago!) and it seemed to us to be a shame to have the Hangul syllables split up into three blocks. Furthermore, Unicode wasn’t yet used for Korean anywhere as far as we could tell. Windows NT had support for Unicode, but nothing special for Hangul. Other operating systems didn’t even support Unicode at that time. Word processing programs that supported Korean used a Korean code page, not Unicode. S.G. Hong of the Microsoft Korean subsidiary pleaded for us to use a single block and after considerable deliberation the UTC and WG2 (the ISO 10646 working group on character sets) elected to do so. Hence in Unicode 2.0 (July 1996) the two earlier Hangul blocks were deprecated and the Hangul syllables were assigned U+AC00..U+D7A3 in the ideal alphabetic order. To this day, no one has come up with a Korean document that was compromised by these changes. But you should have heard the outcries of folks that were upset that the old codes were deprecated.
Ever since then, Unicode code points have been completely stable and such stability is a basic requirement. Shortly after the release of Unicode 2.0, Word 1997 was released. Based on Unicode, it supported the modern Hangul syllables. At that point it would have been unthinkable to change the code points since documents actually existed that used the code points. Fortunately, we were able to make the changes early enough in Unicode’s history that Korea enjoys excellent Unicode support. I couldn’t help but think of that a bit while walking through the streets and palaces of beautiful downtown Seoul.
Very cool! 🙂
It occurred to me the other day why the Japanese writing system (and perhaps the ancient Korean and Vietnamese writing systems) uses a mix of Chinese characters and Japanese-specific letters.
When Japan first started writing, I'm guessing that they wrote Chinese characters but read the Chinese characters using the Japanese language. This worked great for nouns, such as 狗 (dog) or 人 (person), but it didn't work so well for verbs, because Japanese conjugates verbs whereas Chinese doesn't. Therefore, Japan invented their own, unique letters that were used for adding suffixes and prefixes to the Chinese characters.
This could be...
👍
Thank you for your great work for the Korean. There are old but interesting new facts.
In 1446, there were 28 jamo(consonant + vowel), and modern Korean consists of 14 consonants(ja) and 10 vowels(vowel). By combining modern jamos, 11,172 letters can be made. By combining old jamos, 1,638,750 letters can be created. Thanks for your post!