

Welcome to the final part of our series on scalar replacement in OpenJDK. In the previous posts, we covered the basics of scalar replacement and detailed the improvements we introduced to the implementation. Now, it’s time to see these enhancements in action. In this post, we’ll present the results of our work, showcasing the performance gains achieved through our contributions.
Benchmarking
Figure 3 shows the execution time, in seconds, of a collection of synthetic JMH benchmarks. The blue bars show the time the program took to execute when the improvements were disabled, and the orange bars represent how long the program took to execute when the improvements were enabled. We created these benchmarks to study how much speedup we could get in some ideal cases and to ensure that we were not slowing down the application when our improvements could not actually increase the number of scalar replaced objects.
Disclaimer: The results we obtained in these benchmarks are not the sort of improvements that you will see in a large application. These benchmarks spend most of their time executing a single method, therefore you can think about these results as an example of the kind of improvements you can get for individual methods.
The numbers were about what we expected. We got some large improvements in programs that are more memory bound and smaller improvements in programs that are more CPU intensive or that had a lower memory allocation rate.
 Figure 3: Execution time of synthetic JMH benchmarks.
Figure 3: Execution time of synthetic JMH benchmarks.
Figure 4 shows the execution time (lower is better) of some Renaissance benchmark suite programs. The blue bars show the time the program took to execute when the improvements were disabled, and the orange bars represent how long the program took to execute when the improvements were enabled. These programs represent a few different scenarios that we can find in real world applications. Some of these benchmarks are written in Scala using functional programming style, others are written in Java, some of these programs are simply for solving Sudoku or Scrabble and others are implementations of Artificial intelligence algorithms. These results are much more like the kind of results that you can obtain on a real application in production because the speedup that you will get in your application depends on how important the method for which we are scalar replacing the objects is to your application execution time. If we are able to scalar replace many objects in a method that is very important to the application, in the sense that your application spends a lot of time executing, then you will see bigger improvement. However, if we are not able to scalar replace many more additional objects, or if we scalar replace objects in methods that are not that important to the execution time of the application, then the speedups will be more modest, if there are any at all.
We can see that in several of these benchmarks the execution time did not change much, but in some other benchmarks like in NaiveBayes and ScalaDoku we noted reasonable improvements on the order of 10% and 20% improvement in the execution time. We did other experiments with some 1st party customers and saw similar improvements in latency reduction, throughput, and memory allocation rate reduction.
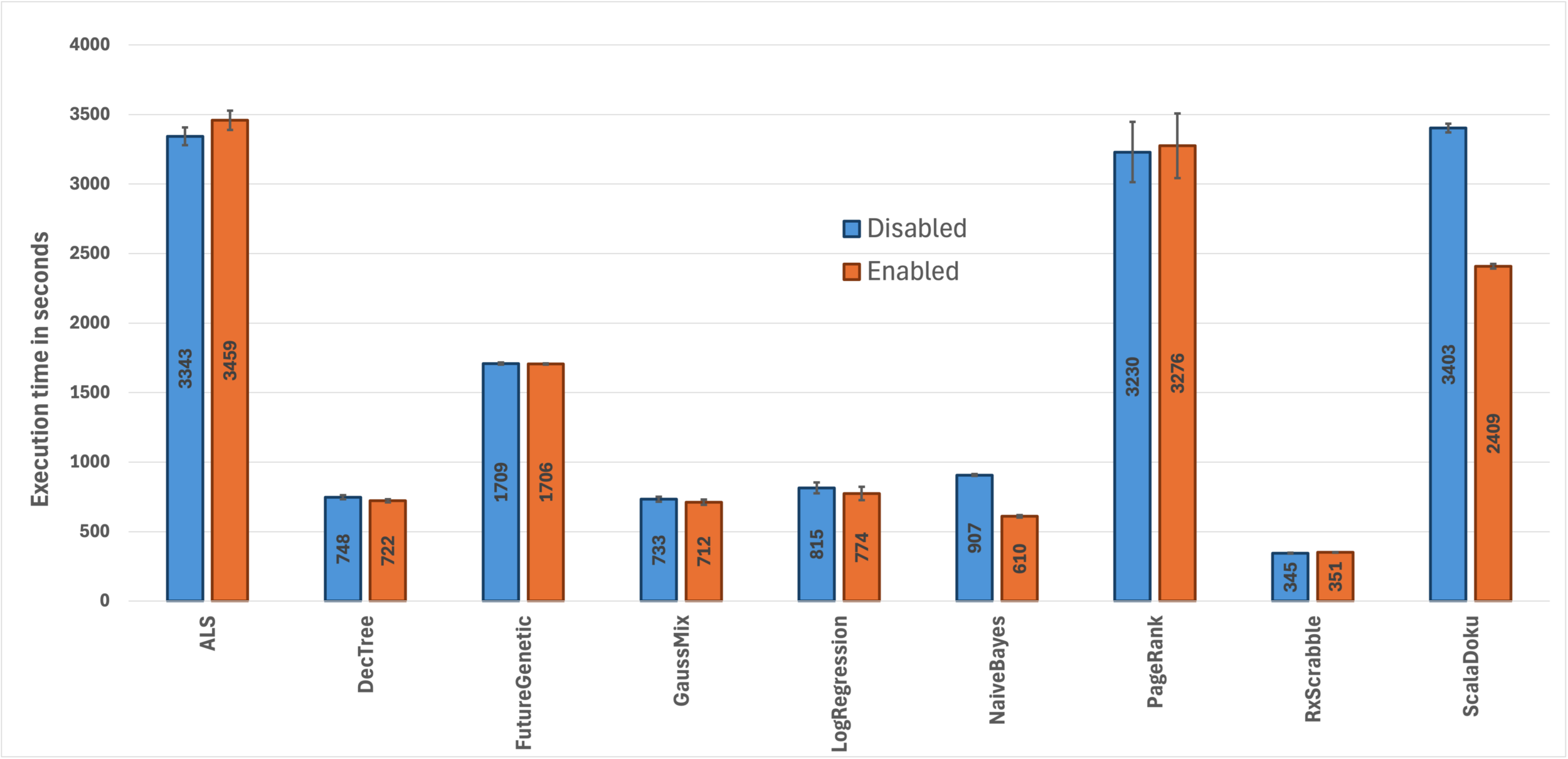 Figure 4: Execution time of Renaissance JMH benchmarks.
Figure 4: Execution time of Renaissance JMH benchmarks.
Concluding Remarks
0 comments