

Scalar replacement (SR) is a powerful optimization technique in OpenJDK that aims to enhance the performance of Java applications by breaking down complex objects into simpler, more manageable scalar variables. In this three-part blog series, we will delve into the intricacies of scalar replacement and the enhancements we’ve contributed to the OpenJDK implementation of it. The first post will provide an overview of scalar replacement, explaining its purpose and fundamental mechanisms. The second post will detail the specific improvements we have made. Finally, the third post will present the results of these improvements. Let’s jump right into it – and don’t forget to add comments!
Introduction
The OpenJDK JVM has two Just-In-Time compilers, C1 and C2. C2 is a compiler that applies many optimizations to produce a very efficient compiled version of the program. This blog post series presents an improvement that we contributed to C2 scalar replacement optimization. But before we delve into the details of our contributions, we are going to discuss about three optimizations implemented in C2: escape analysis, method inlining, and scalar replacement.
Escape analysis (EA) analyzes the code being compiled and decides for each object allocation whether that object might be used outside the current method or thread.
Method Inlining (MI) is, in very general terms, an optimization that replaces method calls with a copy of the body of the method being called.
Scalar replacement (SR) is an optimization which tries to remove object allocations that it considers unnecessary, and it uses information provided by EA and changes made by MI to achieve that. SR removes object allocations by transforming the code to store object’s fields in local variables and using MI to remove the need to invoke methods on objects.
The main benefit of SR may be that it decreases memory allocation rate and pressure on the Garbage Collector (GC). However, there are more benefits. By removing allocations, the method’s code becomes simpler, which may reveal more optimizations. So, in general, doing scalar replacement is a Good Thing TM.
A Simple Example
We are going to use the Message class shown in Listing 1 as the running example in this article. The important things to note in this class are the Checksum method and the content field. The Checksum method iterates on the characters of the content field and accumulates their integer value, returning that as the checksum of the message list.

Listing 1: The Message class.
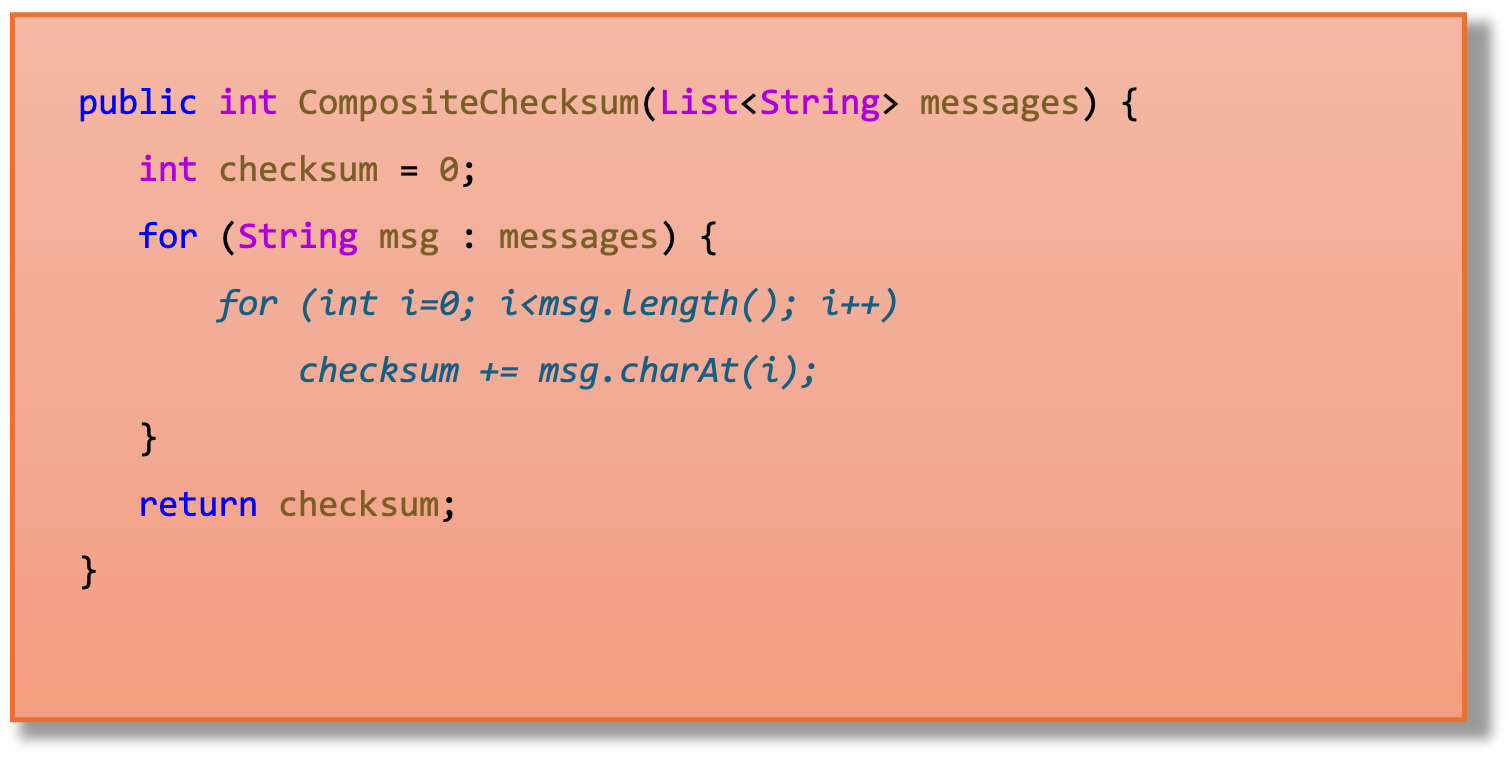
Listing 2 shows the CompositeChecksum method. This method iterates on a list of messages and for each message it calls the Checksum method on it. The method accumulates the checksum of all messages and returns it as the composite checksum of the list. This may not be an example of a piece of code written very carefully, but is the kind of code that is often processed by compilers, especially after many transformations have been applied to the code.
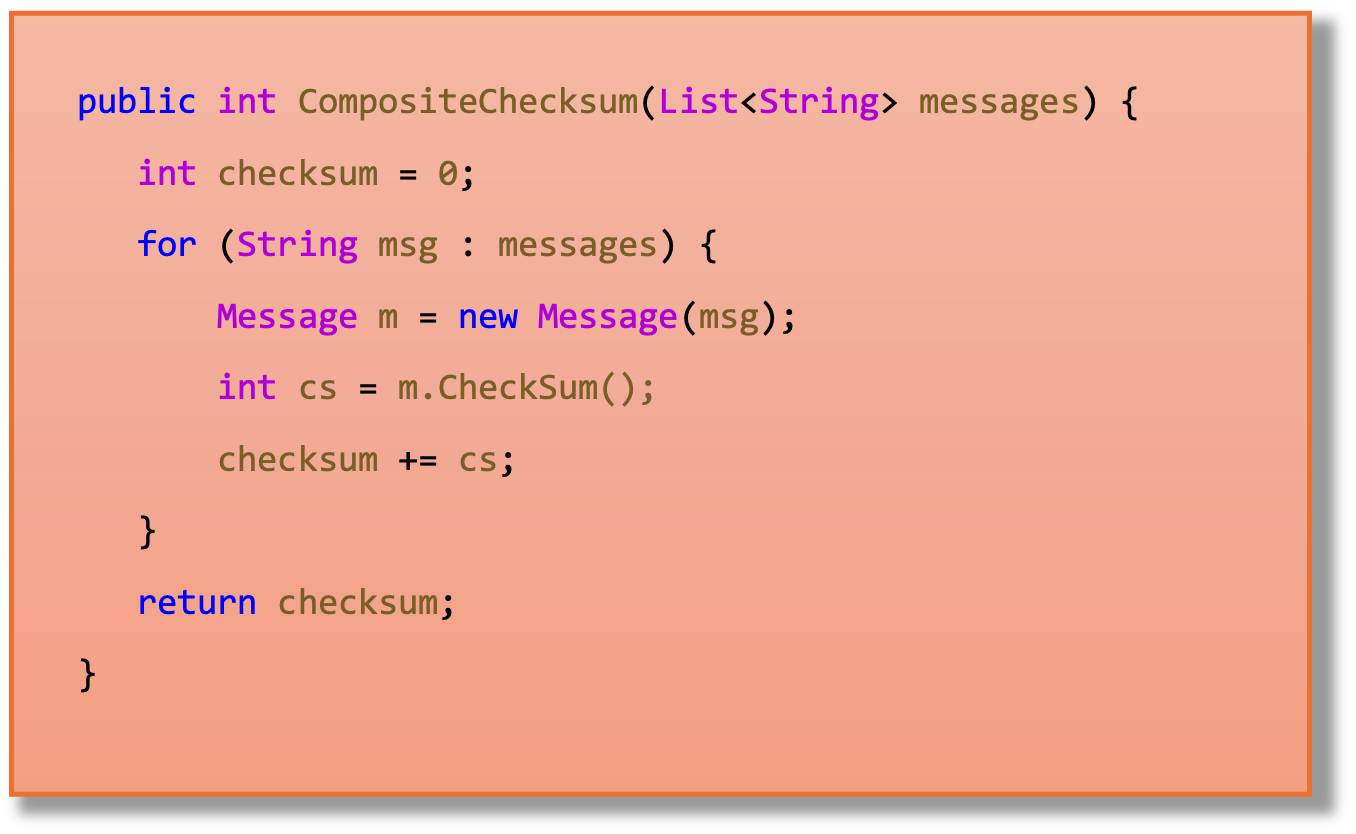
Listing 2: The CompositeChecksum method.
Listing 3 highlights what is going to happen when MI is performed on this method with respect to the Message class constructor and Checksum method. Note that the constructor of the Message object is going to be copied in the place where the constructor was previously being called and the call to the Checksum method is going to be replaced by the code of the Checksum method itself. Of course, after the code is copied, it is adjusted to still work correctly in the target location.
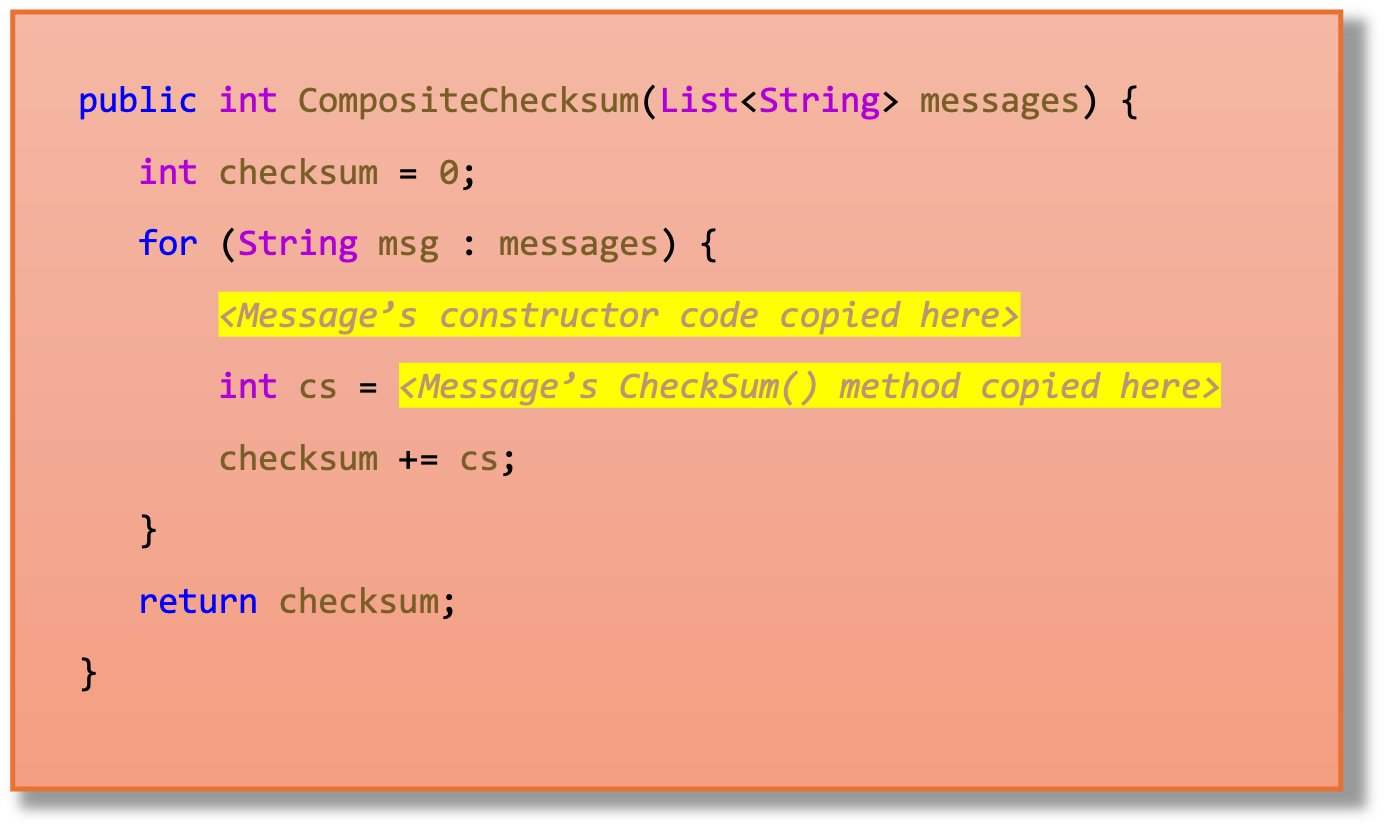
Listing 3: The CompositeChecksum method during inlining optimization.
Listing 4 shows the code after MI has been executed. Note that the object allocation is still happening. The body of the Message and Checksum methods were copied inside the loop, but they still operate on an object, in this case the one pointed to by m_ptr – previously these methods used an object pointed to by this. The chks variable that was local to the Checksum method now is another variable local to the CompositeChecksum loop.
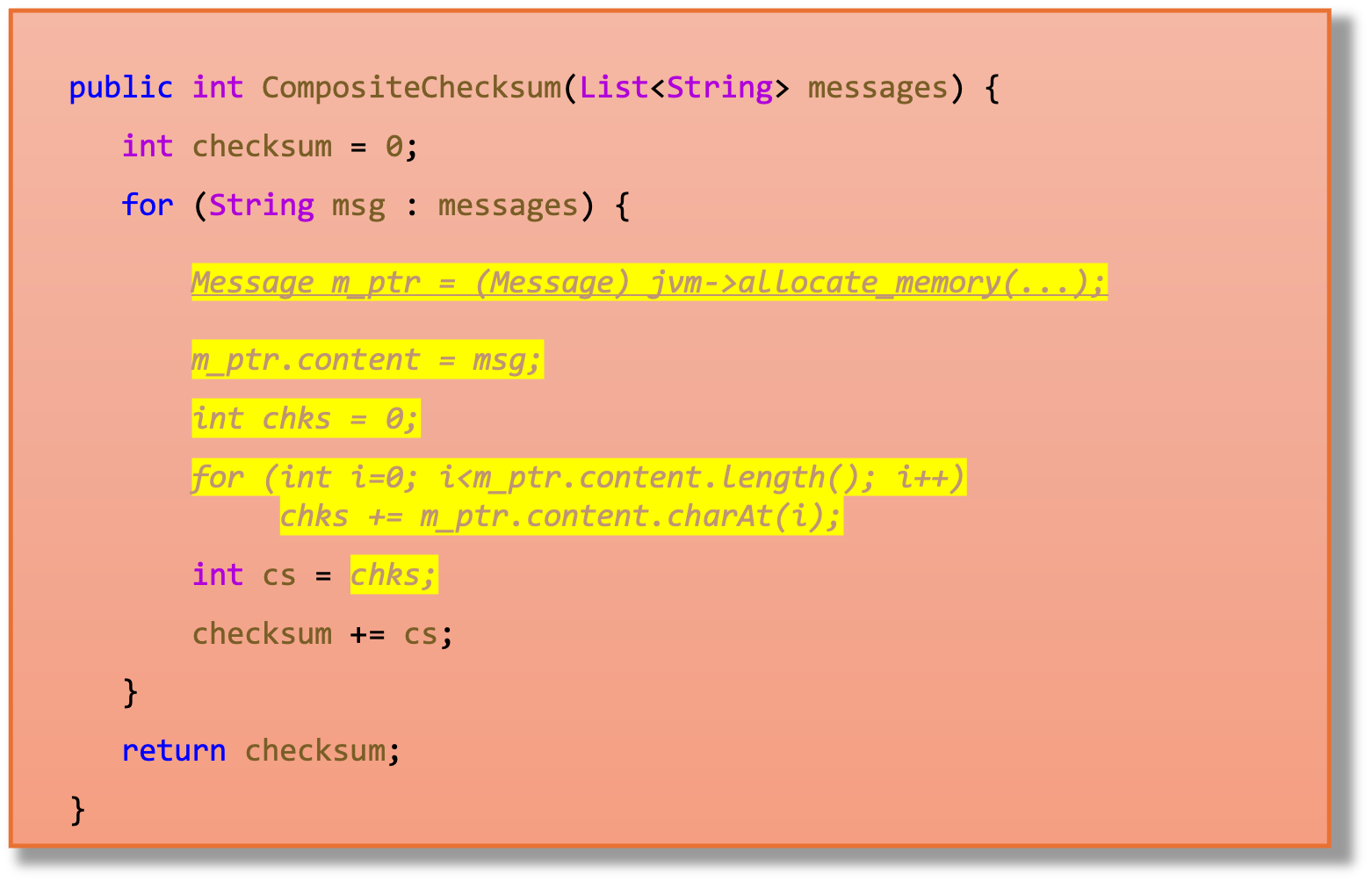
Listing 4: The CompositeChecksum method after inlining optimization.
Note that there is still room for improving the code of the CompositeChecksum method. After performing some more analysis C2 will find that some of the assignments in the code do not really need to be performed. For instance, the assignment of the msg variable to the content variable can be eliminated and we can just iterate on msg itself, instead of content. The same logic applies to the chks variable: instead of doing the computation on the chks variable and then later assigning it to cs and then accumulating into checksum we can just do the computation directly in the checksum variable. Listing 5 shows the code after these optimizations.
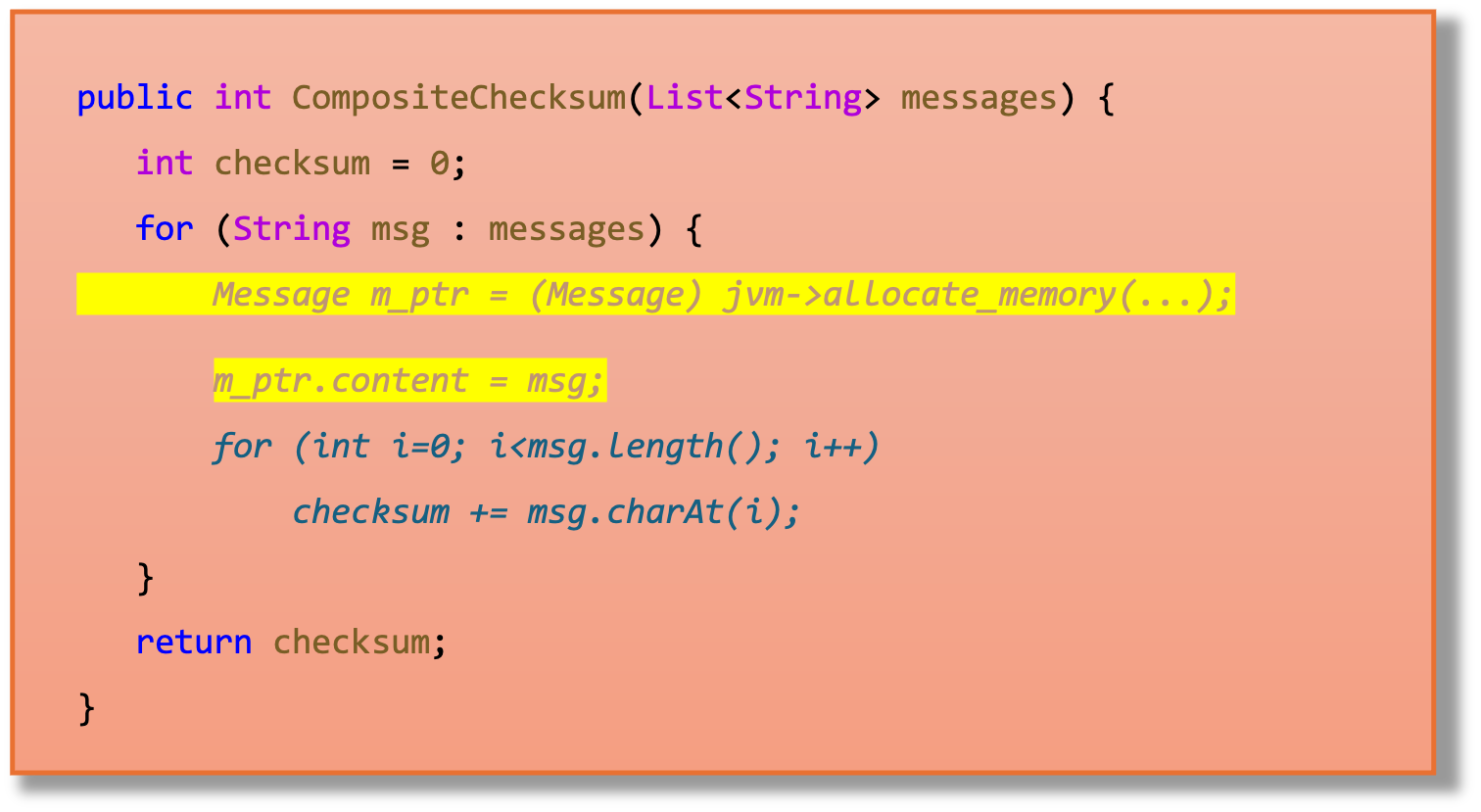
Listing 5: The CompositeChecksum method after additional optimizations.
After still some more analysis C2 will note that there are only writes to the object pointed to by m_ptr and no code is reading from it. That observation, together with some other info about the object class, means that this object allocation is not necessary and therefore it can be removed! Listing 6 shows the code after the object allocation is removed.
Listing 6: The CompositeChecksum method after Message allocation is removed.
The object allocation removal was only possible because at some point there was no code reading from that object. Scalar replacement is one of the optimizations that replaces loads from objects’ fields with a direct use of the statement (or value) that was last written in the objects’ fields. There are other optimizations that achieve the same effect but usually they work on simple pieces of code, like this example method. Scalar replacement, however, can “look” more thoroughly in the method and find points where these object fields’ writes can be simplified.
Conclusion
In conclusion, scalar replacement serves as a critical optimization technique within OpenJDK, transforming complex object instances into simpler scalar variables to enhance runtime performance. By eliminating the need for heap allocation and reducing memory overhead, scalar replacement significantly improves execution speed and resource efficiency. Understanding the fundamental mechanisms behind scalar replacement sets the stage for the second part of this series where we describe the improvements we contributed to OpenJDK’s scalar replacement implementation.
0 comments