

TL;DR
In this blog post, we explore the use of a semantic router using Azure AI Search to handle query routing in AI systems, particularly in the context of a banking chatbot use case. This approach is designed to direct user queries to the most relevant nodes (such as specialized AI models, tools, or data sources). We test this approach against traditional methods using context cramming with different models, such as GPT-3.5, GPT-4o, and GPT-4o-mini, to compare their performance and highlight potential advantages in real-world applications.
Introduction
Query routing in chatbot systems refers to the process of directing user queries to the most appropriate response or action based on the detected intent. Efficient query routing in chatbot systems remains a challenge in the rapidly evolving AI landscape. Traditional approaches, pre-dating Large Language Models (LLMs), often relied on technologies like Language Understanding Intelligent Service (LUIS) or Bidirectional Encoder Representations from Transformers (BERT) for intention detection. LUIS, while fast, lacks flexibility and requires numerous examples to handle varied phrasings of similar intents. BERT, though more adaptable, is not as powerful as LLMs in natural language understanding.
Modern systems have largely transitioned to using LLMs to classify user queries with intent/route labels for routing due to their language understanding. However, this approach faces scalability issues; as routing options increase, maintaining high routing accuracy becomes more challenging and can lead to higher costs and increased latency.
This blog post introduces a routing system designed to address these challenges, potentially offering a more efficient and scalable solution for directing user queries to appropriate resources.
The Problem – Scalability in AI Routing
As AI systems grow in complexity, they often need to choose between numerous potential nodes – which could be specialized AI models, data sources, or tools. Few-shot prompt-based routing for each decision becomes impractical when dealing with hundreds of potential destinations because the examples could exceed the maximum token length for prompts to LLMs. This approach faces several key issues:
- Cost: Each LLM function call incurs a cost, which can quickly escalate with scale.
- Latency: LLM calls introduce noticeable delays, impacting user experience in real-time applications.
- Accuracy: As the number of potential routing destinations grows, the accuracy of LLM-based routing can decrease.
Possible Solution – Semantic Router using Azure AI Search
To address these challenges, a potential solution could be to leverage Azure AI Search, specifically hybrid search with re-ranking, combined with phi-3-mini-4k-instruct for intention detection and relevance checking. Here’s an overview of the potential solution architecture:
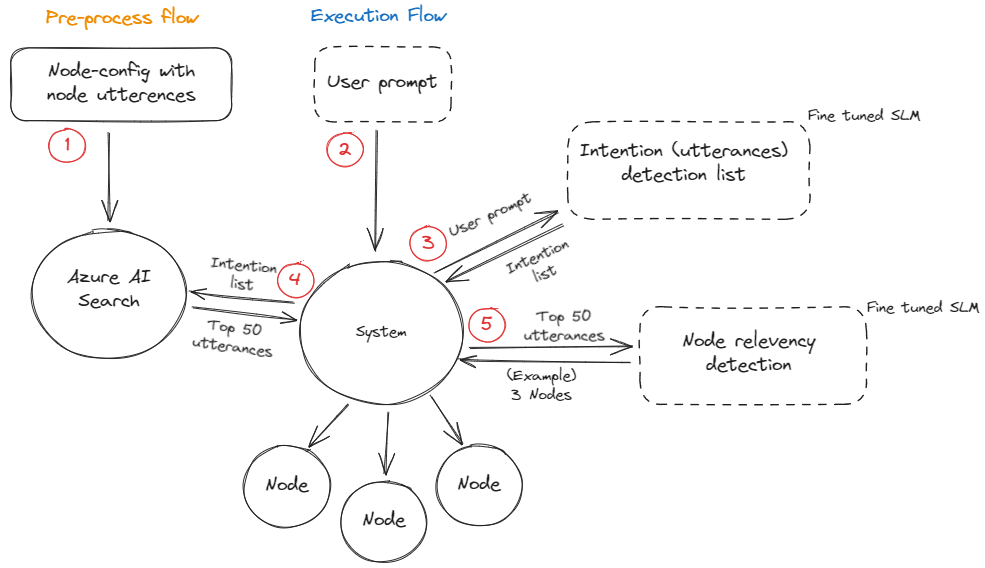
Pre-process Flow
- Node Configuration: We start with a node-config file containing node definitions and associated utterances. An example of a two nodes is shown below:
{
"nodes": [
{
"id": "1",
"name": "home-loans-information",
"description": "Information and services related to applying for, managing, and understanding home loans.",
"utterances": [
"Apply for a home loan",
"Find out interest rates for home loans",
"Learn about different types of home loans"
]
},
{
"id": "2",
"name": "online-banking-information",
"description": "Information on registering, using, and securing online banking services.",
"utterances": [
"Register for online banking",
"Explore features available in online banking",
"Check the security of online banking"
]
}
]
}- Indexing: Node utterances are processed into embeddings and stored in an Azure AI Search index. Along with the metadata (id, name, description)
Execution Flow
- User Input: The process begins when a user submits a query.
- Intention Detection: The system uses phi-3-mini-4k-instruct to analyze the input and extract possible intentions. For example, if a user’s query is “What are the current interest rates for home loans and what documents do I need to apply?”, the extracted intentions would be “Find out the current interest rates for home loans.” and “Learn about the documents needed to apply for a home loan.”
- Azure AI Search Query: For every identified intention, we execute a hybrid search with semantic re-ranking on our indexed node-config data. This process involves two key components: the extracted intention’s text itself and an embedding generated from this text. The system uses both of these elements to perform the hybrid search, combining outcomes from full-text queries and vector queries. These queries use ranking methods like BM25 for text and Hierarchical Navigable Small World (HNSW) for vector searches. Results are merged using a Reciprocal Rank Fusion (RRF) algorithm, which produces a final, unified ranking. On top of this, the semantic ranking capability provides a score which uses multi-lingual, deep learning models adapted from Microsoft Bing to promote the most semantically relevant results.
- Node Relevancy Detection: The system employs phi-3-mini-4k-instruct to evaluate the relevance of the top results by considering them alongside the original user query and any additional pertinent information.
- Node Selection: Based on the relevancy check, the system selects nodes for execution.
Example using basic setup
- The first step is to set up our environment.
# .env
# OpenAI configuration
OPENAI_API_KEY=my-openai-api-key # Your OpenAI API key
OPENAI_EMBEDDING_MODEL=text-embedding-3-large # The embedding model we use, which will use 3072 dimensions
# Azure search configuration
AZURE_SEARCH_SERVICE_ENDPOINT=my-search-service.search.windows.net # Your Azure AI Search resource endpoint
AZURE_SEARCH_API_KEY=my-search-service-api-key # Your Azure AI Search resource API key
AZURE_SEARCH_INDEX_NAME=my-search-index # The name of the index that will be created and used for search- Next, in a separate file – let’s call it semantic_router.py, this is where the rest of the code will go. Begin with your imports.
# semantic_router.py
import os
import logging
from typing import List, Dict, Any
from dotenv import load_dotenv, find_dotenv
from azure.core.credentials import AzureKeyCredential
from azure.search.documents import SearchClient
from azure.search.documents import SearchClient
from azure.search.documents.models import VectorizedQuery
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents.indexes.models import (
SearchIndex,
SimpleField,
SearchField,
SearchableField,
VectorSearch,
HnswAlgorithmConfiguration,
VectorSearchAlgorithmKind,
VectorSearchAlgorithmMetric,
VectorSearchProfile,
SemanticConfiguration,
SemanticField,
SemanticSearch,
CorsOptions,
SearchFieldDataType,
SemanticPrioritizedFields,
)
from openai import OpenAI- We should then load our environment variables using the
dotenvmodule and set up some basic logging.
# Load environment variables
load_dotenv(find_dotenv())
# Set up basic logging
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s')- Next, we need an easy way to set up our clients for Azure AI Search, so let’s define those functions.
def get_search_client() -> SearchClient:
return SearchClient(
endpoint=os.getenv('AZURE_SEARCH_SERVICE_ENDPOINT'),
index_name=os.getenv('AZURE_SEARCH_INDEX_NAME', 'dataset-index'),
credential=AzureKeyCredential(os.getenv('AZURE_SEARCH_API_KEY'))
)
def get_search_index_client() -> SearchIndexClient:
return SearchIndexClient(
os.getenv('AZURE_SEARCH_SERVICE_ENDPOINT'),
AzureKeyCredential(os.getenv('AZURE_SEARCH_API_KEY')
)
)- Next, we can define a function that converts text into an embedding using OpenAI, though AzureOpenAI can also be used. Keep in mind the dimensions used for our embedding, which is 3072 as specified in the
.envfile. This dimension must be reflected when we create our index for the vector in theutteranceVectorfield.
def get_embedding(text: str) -> List[float]:
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
model = os.getenv('OPENAI_EMBEDDING_MODEL')
response = client.embeddings.create(
input=text,
model=model
)
embedding = response.data[0].embedding
return embedding- Now, we define a function to create the index according to our node schema.
def create_index(search_client: SearchClient) -> None:
# Create a SearchIndexClient
logging.info(f"Connecting to Azure Search service at {
os.getenv('AZURE_SEARCH_SERVICE_ENDPOINT')}")
# Define the fields
logging.info("Defining index fields")
fields: List[SimpleField] = [
SimpleField(name="id", type=SearchFieldDataType.String,
key=True, searchable=False, retrievable=True),
SimpleField(name="node_id", type=SearchFieldDataType.String,
searchable=False, retrievable=True),
SearchableField(name="node_name",
type=SearchFieldDataType.String, retrievable=True),
SearchableField(name="utterance",
type=SearchFieldDataType.String, retrievable=True),
SearchField(name="utteranceVector", type=SearchFieldDataType.Collection(SearchFieldDataType.Single),
searchable=True, vector_search_dimensions=3072,
vector_search_profile_name="default-vector-profile"),
SearchableField(name="description",
type=SearchFieldDataType.String, retrievable=True),
SimpleField(name="services", type=SearchFieldDataType.Collection(SearchFieldDataType.String),
searchable=True, retrievable=True)
]
# Define CORS options
logging.info("Setting up CORS options")
cors_options: CorsOptions = CorsOptions(
allowed_origins=["*"], max_age_in_seconds=300)
# Define vector search configuration
logging.info("Configuring vector search")
vector_search: VectorSearch = VectorSearch(
algorithms=[
HnswAlgorithmConfiguration(
name="hnsw-config",
kind=VectorSearchAlgorithmKind.HNSW,
parameters={
"m": 4,
"efConstruction": 400,
"efSearch": 500,
"metric": VectorSearchAlgorithmMetric.COSINE
}
)
],
profiles=[
VectorSearchProfile(
name="default-vector-profile",
algorithm_configuration_name="hnsw-config"
)
]
)
# Define semantic search configuration
logging.info("Configuring semantic search")
semantic_config: SemanticConfiguration = SemanticConfiguration(
name="semantic-config",
prioritized_fields=SemanticPrioritizedFields(
title_field=SemanticField(field_name="node_name"),
content_fields=[
SemanticField(field_name="utterance"),
SemanticField(field_name="description"),
SemanticField(field_name="services")
]
)
)
semantic_search = SemanticSearch(
configurations=[semantic_config])
# Create the index
logging.info("Creating or updating index.")
index: SearchIndex = SearchIndex(
name=os.getenv('AZURE_SEARCH_INDEX_NAME', 'dataset-index'),
fields=fields,
cors_options=cors_options,
vector_search=vector_search,
semantic_search=semantic_search
)
search_index_client = get_search_index_client()
result: SearchIndex = search_index_client.create_or_update_index(index)
logging.info(f"Index '{result.name}' created successfully")- We also need a function to execute the search based on a given intention.
def execute_hybrid_semantic_search(search_client: SearchClient, intention: str) -> List[Dict[str, Any]]:
# Initialize Azure Search client
intention_embedding = get_embedding(intention)
vector_query = VectorizedQuery(
vector=intention_embedding, k_nearest_neighbors=50, fields="utteranceVector")
logging.info("Using Semantic Reranker for search.")
results = search_client.search(
search_text=intention,
vector_queries=[vector_query],
query_type='semantic',
semantic_configuration_name='semantic-config',
select='id,node_name,utterance,description,services',
query_caption='extractive',
query_answer="extractive",
top=50
)
return list(results)- Now, let’s put everything together and run the process:
- Convert all utterances into embeddings.
- Define our nodes in a
documentsvariable. - Create the index in Azure AI Search.
- Upload our documents to make them searchable.
- Execute the hybrid semantic search using an extracted intention from a query.
- Display the results by logging the top result.
# Pre-process utterances and get documents prepared for upload
banking_utterance_vector = get_embedding("Open a new savings account")
home_loan_utterance_vector = get_embedding(
"Understand the process of applying for a home loan")
# Node structure in a banking context
documents = [
{
"id": "1-0",
"node_id": "1",
"node_name": "banking",
"description": "The scope for banking is to provide information about the different types of accounts, credit cards, personal loans, and term deposits that are available. It also provides information on how to apply for these services.",
"services": ["credit-cards", "personal-loans", "term-deposits", "everyday-accounts"],
"utterance": "Open a new savings account",
"utteranceVector": banking_utterance_vector
},
{
"id": "2-0",
"node_id": "2",
"node_name": "home-loans",
"description": "The scope for home loans is to provide information about the different types of home loans that are available. It also provides information on how to apply for a home loan, the interest rates, and the maximum loan amount that can be applied for. It also provides information on refinancing home loans, stamp duty, and the minimum deposit required for a home loan.",
"services": ["home-loans"],
"utterance": "Understand the process of applying for a home loan",
"utteranceVector": home_loan_utterance_vector
}
]
search_client = get_search_client()
# Create the index
create_index(search_client=search_client)
# Upload documents to Azure Search
result = search_client.upload_documents(documents=documents)
# Example extracted intention from user query
intention = "Apply for a home loan"
# Execute Azure AI Hybrid Search query with Semantic Reranking
search_results = execute_hybrid_semantic_search(
search_client=search_client, intention=intention)
# Get the top result
top_result = search_results[0]
logging.info("Top Search Result:")
logging.info(f"Node Name: {top_result['node_name']}")
logging.info(f"ID: {top_result['id']}")
logging.info(f"Utterance: {top_result['utterance']}")
logging.info(f"Description: {top_result['description']}")
logging.info(f"Services: {', '.join(top_result['services'])}")
logging.info(f"Search Score: {top_result['@search.score']:.6f}")
logging.info(f"Reranker Score: {top_result['@search.reranker_score']:.6f}")Potential Advantages of this Approach
- Accuracy: When compared to few-shot prompting with many examples, this approach may offer improved accuracy. As the number of routing options increases, maintaining high accuracy with few-shot prompting can become challenging. The combination of intention detection, Azure AI Search, and relevancy checking could potentially provide more precise routing decisions.
- Scalability: As we increase the number of routes, this system should be able to handle it better compared to a single LLM holding all the route information within a prompt. This is due to filtering the amount of routes that are relevant. Few-shot examples might not fit in a prompt when dealing with numerous routing options, whereas this approach can potentially handle a larger number of routes efficiently.
- Extensibility: By indexing new route examples in Azure Search, the system can be easily extended without the need for retraining. This allows for quick updates to routing options, which can be particularly advantageous in dynamic environments where new routes are frequently added or modified.
- Modularity: By having single responsibility nodes we can add or remove nodes as we see fit, and can update them without affecting other nodes.
- Comparison to Fine-tuned Small Language Models (SLMs): When compared to fine-tuning a smaller language model (SLM), which can be accurate, low cost, and scalable, the main advantage of this approach might be its extensibility. Updating an index in Azure Search could potentially be faster and more flexible than retraining an SLM, especially in scenarios where routing options change frequently.
Experimental Results
To validate the proposed semantic routing approach using Azure AI Search, we conducted a series of tests comparing it with traditional LLM-based routing methods. These experiments were designed to evaluate the system’s performance in terms of accuracy and efficiency.
Test Setup
We created a test environment with the following components:
- A node configuration file containing 12 distinct routing nodes (domains) with a total of 98 utterances (intentions).
- A test set of 30 prompts, varying in length and complexity, each with an expected most relevant Utterance and Node.
- An Azure AI Search index populated with the node configuration data.
- GPT-3.5, GPT-4o and GPT-4o-mini models for comparison.
As a visual example, here is one of the prompts we used for testing: “Are there any special offers on term deposits?”
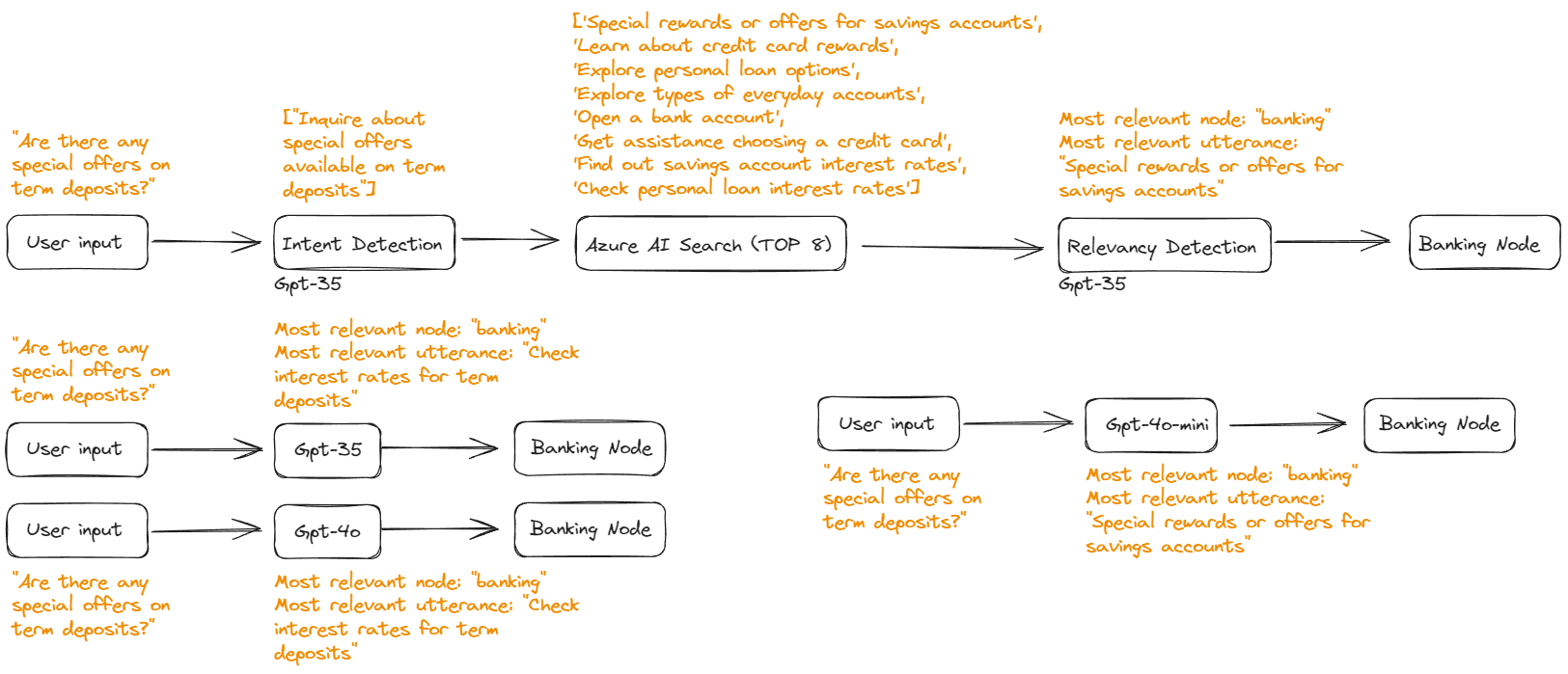
Here are the results of our tests:
| Model | Total Tests | Correct Utterance Matches | Correct Node Matches | Utterance Accuracy | Node Accuracy | Average Execution Time |
|---|---|---|---|---|---|---|
| GPT-3.5 Turbo | 30 | 24 | 30 | 80.00% | 100.00% | 0.81 seconds |
| Semantic Routing w/Azure AI Search, GPT3.5 Extraction, Reranker & GPT3.5 Detection | 30 | 30 | 30 | 100.00% | 100.00% | 4.79 seconds |
| GPT-4o | 30 | 29 | 30 | 96.67% | 100.00% | 1.11 seconds |
| GPT-4o-mini | 30 | 28 | 29 | 93.33% | 96.67% | 1.17 seconds |
Summary
Semantic routing using Azure AI Search with GPT-3.5 proved to be the most accurate, achieving 100% accuracy for both utterance and node matching. However, it was also the slowest with an average execution time of 4.79 seconds.
GPT-4o demonstrated excellent performance, with 96.67% utterance accuracy and 100% node accuracy, and a relatively fast average execution time of 1.11 seconds.
GPT-4o-mini showed strong results as well, with 93.33% utterance accuracy and 96.67% node accuracy, and an average execution time of 1.17 seconds, slightly slower than GPT-4o.
GPT-3.5 Turbo was the quickest but least accurate for utterance matching, with 80% utterance accuracy and 100% node accuracy, and the fastest average execution time of 0.81 seconds.
In summary, while Semantic routing achieved perfect accuracy, its slower speed might be a trade-off. GPT-4o and GPT-4o-mini both offer a good balance of accuracy and speed, with GPT-4o having a slight edge. GPT-3.5 Turbo remains the fastest option but at the cost of lower utterance accuracy.
If semantic routing were to be considered for implementation in a system, more thorough testing and evaluation would need to be conducted to ensure its effectiveness across a wider range of scenarios and larger datasets.
Conclusion
The Semantic Router using Azure AI Search approach presented here offers a potential solution to the growing challenge of efficient query routing in complex AI systems. By leveraging Azure AI Search and SLMs like phi-3-mini-4k-instruct, this theoretical system aims to handle numerous routing options while potentially improving speed, cost-efficiency, and accuracy compared to some other options in the community.
It’s important to note that this solution is conceptual and untested. Real-world implementation and rigorous testing are necessary to validate its effectiveness, efficiency gains, and scalability. We present this as a starting point for discussion and welcome feedback from the community on this approach to addressing routing challenges in evolving AI architectures.