
Background
While artificial intelligence (AI) is offering amazing data-driven insights across a range of industries, arguably one of the more important applications for us as humans has been in the field of genomics. Technologists have teamed up with geneticists to use AI technology to offer a better understanding of human DNA, in an attempt to tackle common diseases around the world. By comparing millions of samples of genetic data, experts can better understand the cause of diseases, and attempt to highlight demographics and patient profiles who are most at risk from certain conditions.
However, while the field has advanced extensively over the last two decades, thousands of genetic diseases remain unknown, and many research centers and healthcare organizations do not have the time or resources to appropriately analyze and take insights from their patient DNA data.
To help alleviate this problem, Microsoft recently partnered with Emedgene, to develop a next-generation genomics intelligence platform which incorporates advanced artificial intelligence technologies to streamline the interpretation and evidence presentation process. With this platform, healthcare providers around the world will be better able to provide individualized care to more patients through improved yields on their diagnostic data.
To allow Emedgene to scale efficiently, the company wanted to migrate their solution from AWS to Azure with support from Microsoft. However, due to the huge amount of high scale data and computing power needed to run AI applications of this type, this posed a challenge. To do this, our team migrated the compute resources to Azure, transferred more than 100 TB of blob storage and handled application secrets without embedding the Azure SDK in the application code:
Architecture & Migration
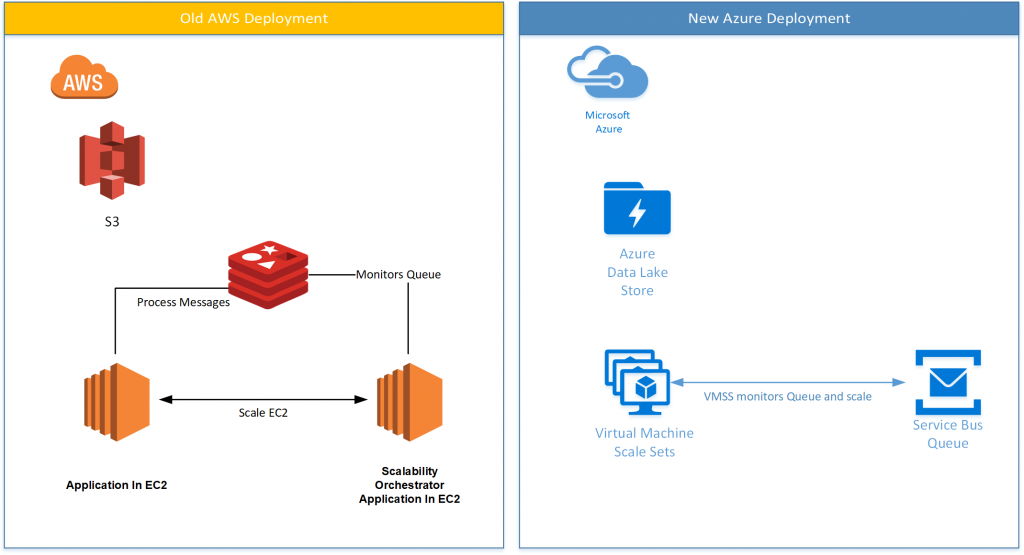
A key part of Emedgene’s architecture is the provisioning of new EC2 Spot instances to execute compute heavy analytics processes that require the input of large sets of genomics data in S3. Each analytics job metadata is enqueued in a queue for processing by the EC2 instances. The number of the instances is dynamic and varies according to the number of messages in the queue.
Compute: EC2 instances are provisioned using another EC2 instance that is monitoring a Redis Queue for additional jobs.
Data: The genomic datasets can comprise over one million individual files with a cumulative size limit of 100TB. In order to perform very fast analytics, Emedgene needs to copy the different sets of files from S3 to the instances attached disks each time an instance is provisioned and gain higher throughput and lower network latency between the instances and the data. In Azure, we will copy these files from Azure Data Lake Store to the VM’s attached disks the same way.
To support native scalability without using another application module, like the solution in AWS that included Redis Queues and additional EC2 instances, we used Virtual Machine Scale Sets (VMSS). VMSS enables us to monitor an Azure Service Bus queue for messages and provision new instances when the queue reaches a certain threshold. Once the application finishes its task, it invokes a script (Self Destroy Instance) that deletes the VM instance from VMSS. The script can be invoked in a Docker container for maximum flexibility in the deployment process.
Note: We considered working with Azure Batch Low Priority VMs but scaling with Azure Service Bus and custom VM images are not fully supported.
The DevOps flow
The Continuous Integration / Continuous Deployment (CI/CD) process is managed with Jenkins. While Jenkins provides a lot of flexibility, we needed a way to provision and manage Azure resources in the pipeline. To do this, we used Azure CLI 2.0 but we also needed to be able to propagate the results from each command to the next such as names and paths.
For example, this code is the result of a CLI command. We want to take the “name” property and propagate it to another command since it is dynamic.
{
"id": "/subscriptions/some-guid/resourceGroups/test",
"location": "northeurope",
"managedBy": null,
"name": "test",
"properties": {
"provisioningState": "Succeeded"
},
"tags": null
}
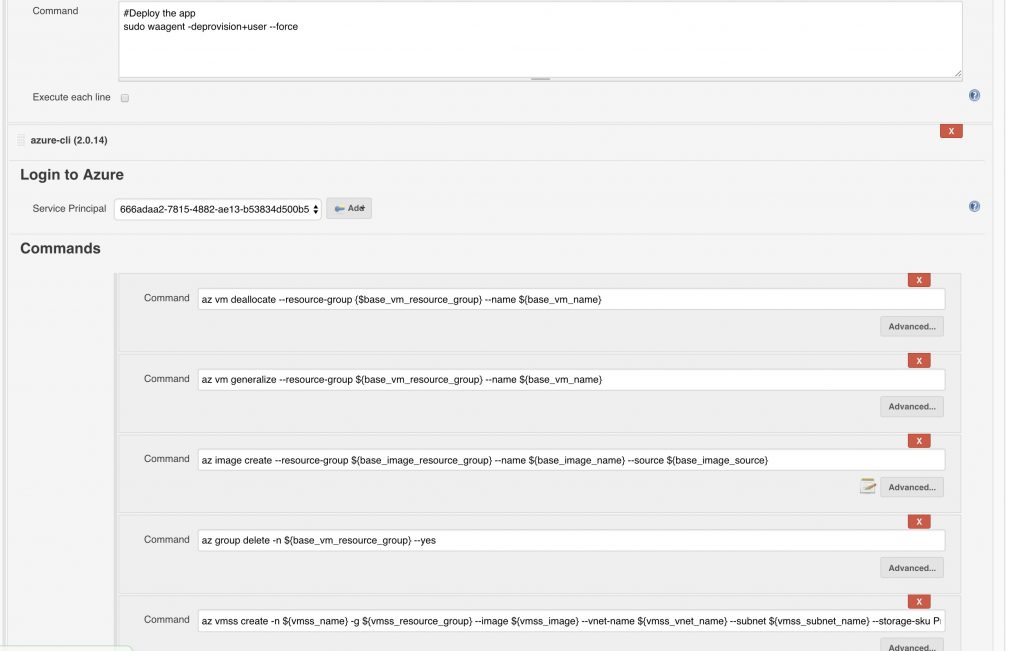
To do this, we created the Azure CLI Jenkins Plugin. The following steps describe how to provision a new VM, create an image from that VM, and create a Virtual Machine Scale Set (VMSS) from that image.
- Using the Environment Injector plugin, inject environment variables into Jenkins
# Configs base_vm_resource_group= base_vm_name= subscription_id= base_image_resource_group= base_image_name=base-image-$(date +%Y%m%d-%H%M) base_image_source= vmss_name= vmss_resource_group= vmss_image= vmss_vnet_name= vmss_subnet_name= vmss_ssh_key_path= image_user= instance_count=1 instance_type=Standard_F8S
- Provision a new VM with an attached disk
# Recreate resource group and vm az group create -n ${base_vm_resource_group} -l ${location} az vm create --resource-group ${base_vm_resource_group} --name ${base_vm_name} --image ${vmss_image} --storage-sku Premium_LRS --ssh-key-value ${vmss_ssh_key_path} --admin-username ${image_user} --size ${instance_type} - SSH into the VM using Jenkins SSH Plugin
- Deploy the application using a simple BASH script
- Copy the data from Azure Data Lake Store to the attached disk to enable the application maximum performance in Read/Write
- Deprovision the VM
sudo waagent -deprovision+user --force
- Make an image from the VM
# Deallocate (stop) the base image vm az vm deallocate --resource-group {$base_vm_resource_group} --name ${base_vm_name} # Flag vm to be able to create an image from it az vm generalize --resource-group ${base_vm_resource_group} --name ${base_vm_name} # Create the image az image create --resource-group ${base_image_resource_group} --name ${base_image_name} --source ${base_image_source} # Export the id of the image to an environment variable id|vmss_image - Delete the VM and associated resources
az group delete -n ${base_vm_resource_group} --yes - Create or update the VMSS with the current VM image
# Create (or update) VMSS with new image az vmss create -n ${vmss_name} -g ${vmss_resource_group} --image ${vmss_image} --vnet-name ${vmss_vnet_name} --subnet ${vmss_subnet_name} --storage-sku Premium_LRS --ssh-key-value ${vmss_ssh_key_path} --admin-username ${image_user} --instance-count ${instance_count} --vm-sku ${instance_type} --data-disk-sizes-gb 10 --disable-overprovisionThe image below shows the Azure CLI commands with environment variables as parameters:
Transferring the Data
Emedgene provides its customers the option of supplying data on either Azure or AWS S3. For Azure, Emedgene decided that they wanted to store their data in Azure Data Lake Store (ADLS), which enables the capture of data of any size, type, or ingestion speed. In order to achieve this functionality, they needed to transfer more than 100 TB of customer data securely from S3 storage to ADLS using Azure Data Factory. Azure Data Factory allows users to create a workflow that can ingest data from both on-premises and cloud data stores, then transform or process that data using existing compute services.
During the migration process, Emedgene faced a challenge involving their need to periodically pull from their customers’ S3 instances. While Azure Data Factory can be used for a full migration from S3, it only supports incremental data copy from external data sources by date stamp if the data store is properly structured.
Example: -|--year
|--month
|-- day
Since AWS does not provide a way of enforcing a rigid store hierarchy, Emedegene needed a mechanism to support incremental copy for improperly organized data stores. To resolve this problem, we created a Docker container for incremental data copy from S3 to ADLS. This service enables Emedgene to copy new data incrementally from S3 to ADLS by datestamp without a dependency on data store structure.
Application Secrets
Emedgene’s microservices architecture rests upon a large number of interdependent internal and external services. Emedgene needed a secure and centralized way to manage access to and between these services. Azure Key Vault provides key and secret management which allowed Emedgene to generate and manage secure access tokens for their services.
However, Emedgene wanted to be able to easily query Azure Key Vault locally using their Azure Service Provider Credentials without having to parse a response object. This approach presented a couple of challenges. While the Azure Service REST API supports Service Provider Authentication, the client-level APIs require Credential Authentication for querying the Key Vault. In addition, certain key vault management features such as retrieving a list of all key vaults are not supported by the REST API.
To support Emedgene’s request we created a scalable Docker container for querying Azure key vaults for secrets using Azure Service Provider Credentials. Once the container service is running, users can choose either to retrieve a secret from a vault or search all vaults for a given secret.
Summary
Not all Azure services have direct 1:1 parity with AWS. When migrating from AWS to Azure there were three important questions which our team had to address:
- What was the most efficient path to move the data from AWS?
- How could we achieve the same or better compute functionality upon migration?
- How to manage access to the newly migrated services?
Our solution addresses these concerns by providing Emedgene with better native compute scalability, efficient data transfer support, and access management through the Azure Key Vault.
The solution outlined in this code story is adaptable to any workload that requires:
- Continuous transfer of a large amount of data from S3 to Azure Data Lake
- Changing the Jenkins DevOps process from AWS resources to Azure resources
- Handling Key Vault secrets without embedding the Key Vault API in your code
We encourage any team undertaking a similar migration to Azure to take advantage of our code, which can be found in the following GitHub links:
The new link for S3 To ADLS: https://github.com/Azure/S3ToAdl