

Autonomous driving systems depend on sensors, complex algorithms, machine learning systems and processors to run software. They create and maintain a map of their surroundings based on a variety of sensors situated in different parts of the vehicle like radar, cameras, and LiDAR (Light Detection and Ranging).
Software then processes all this sensory input, plots a path, and sends instructions to the vehicle’s actuators, which control acceleration, braking, and steering. Rules, obstacle avoidance algorithms, predictive modeling, and object recognition help the software learn to follow traffic rules and navigate obstacles. But to do all this, there are complex processing challenges with respect to the data collected for building this software.
This article highlights how we approached some of the concerns and constraints when developing a cloud-based data processing solution for AVOps (Autonomous Vehicle Operations). We aligned our solution with Microsoft’s AVOps reference architecture. This provides a comprehensive set of cloud, edge, vehicle, and AI services that enable an integrated, end-to-end workflow for developing, verifying, and improving automated driving functions.
We needed to be able to process a large amount of data collected for building and training ML models for Autonomous Vehicles. Basically, we needed a scalable and cost-effective solution to be able to deal with potentially petabytes of data.
The data was collected from test vehicles going around the city and were in the Rosbag file format. A Rosbag, or bag, is a file format in ROS for storing ROS message data. Rosbag is an effective way to store all the collected sensor data in a format that can be easily used. Each Rosbag could range from 2-10 GB in size. Each vehicle would collect a maximum of 100 TB of data. After collection, this data will be uploaded to Azure for further processing.
Challenges with the Data Processing
-
The storage used was ADLS Gen 2 (Azure Data Lake Storage). This storage account has a soft limit of 5 PB. If the number of vehicles collecting data increased, then this limit would be easily reached.
-
Storage costs would increase as the size of the data increases and the duration of storage increases as well
-
We needed an efficient and cost-effective way of processing this large amount of data.
-
We needed some way to track the processed data that came from which Rosbag file. This type of lineage will help in tracking and auditing once ML processing starts on top of this data
Below, we will discuss our experience using ADLS Gen2, ADF, Azure Batch and Databricks to accomplish this objective in four steps:
-
Upload and store the raw collected data
-
Extract and process the raw data using ADF and Azure Batch
-
Store the processed data such that it can be used further in MLOps
-
Search the processed data and curate it for further analysis
Solution
We resolved these challenges mentioned in the previous section in three ways:
-
The storage account we used was an unlimited storage account. We also used the concept of data zones ex: landing zone, raw zone and extracted zone. Each data zone would be backed by a storage account.
-
We used a combination of ADF and Azure Batch to do the large-scale processing of the data. In addition, we used spot instances in Azure Batch for cost optimization.
-
We developed APIs to add metadata and track the lineage of the data
-
We developed a data discovery feature to be able to search through the datastreams and find the data most useful for us.
Data Model
In AVOps, for training of the needed ML models, a diverse set of data on the roads is needed. This data could be about driving the car in different traffic conditions, different weather conditions, lane cutting, etc.
Admins create a list of tasks which map to these conditions and assign the tasks to the drivers. The driver then start with the tasks assigned to them.
When the conditions are correct for the task at hand ex: driving on a sunny day in a heavy traffic situation, then the driver starts the task by starting the recording in the car.
Microsoft’s Common Data Model provides a shared data language for business and analytical applications to use. Our solution is deeply inspired by the Common Data Model approach and utilizes one of the core automotive pillar models viz. Measurement (called DeviceMeasurement in the Common Data Model).
Measurement
A measurement corresponds to a collection of data files generated at the vehicle when it went to perform a specific task. It contains all the information about the drive like the task, vehicle information, driving conditions and information of the the Rosbag files recorded during the drive.
Measurement has following content:
-
Rosbag files
-
The Rosbag files contain the actual raw data of various sensors (LiDAR, radar, camera, etc.) which was recorded during a vehicle run. The data is kept in the form of segregated topics of specific sensors in a Rosbag file.
-
For better operations, Rosbag files are created in chunks of 2 GB size.
-
-
Manifest File
-
The manifest file contains the metadata information of a measurement, which mainly contains the following details:
-
Vehicle (Vehicle identifier, type, make etc.)
-
Driver (Driver personal details)
-
Task information (Unique task identifier, driving area, co-relation with vehicle and driver)
-
Rosbag metadata (A list of Rosbag file’s metadata, which contains the path, name, checksum, file creationTime)
-
-
Derived Datastreams and Maintaining Lineage
Datastream is an immutable stream of data and the most fundamental unit to work within the data pipelines in this platform. DataStream can be considered as the first footprint of vehicle data in the cloud. It could be of two types, raw and derived.
Datastream points to the physical location of Rosbag files and manifests in the cloud (possibly an ADLS folder link). It contains the sources of the datastream as an empty list and a lineage for trackability.
Once measurement comes into the landing zone in the cloud, a raw datastream is created from it. All processes on top of the raw datastream cause derived datastreams to be created. As you can see in the diagram, extraction process on the raw datastream will create an extracted datastream from it. Any datastream built on top of a raw datastream is a derived datastream.
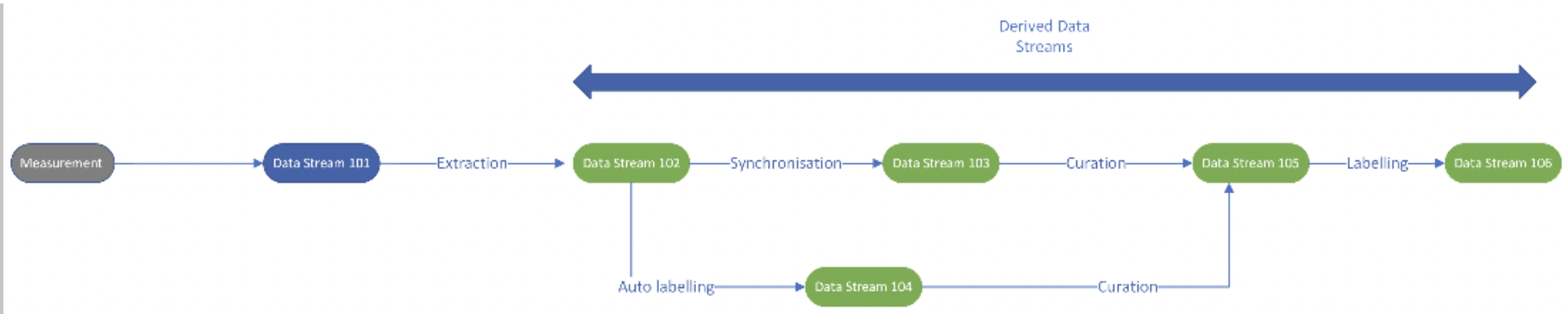
We maintain the lineage of the data from the measurement to the derived datastream. This makes it easy to track which Rosbag had the files for the derived datastream. This becomes important during auditing when we need to understand which videos and images went into the training of the ML model. Hence, lineage of the data becomes important from an audit and legal standpoint.
Architecture deep-dive
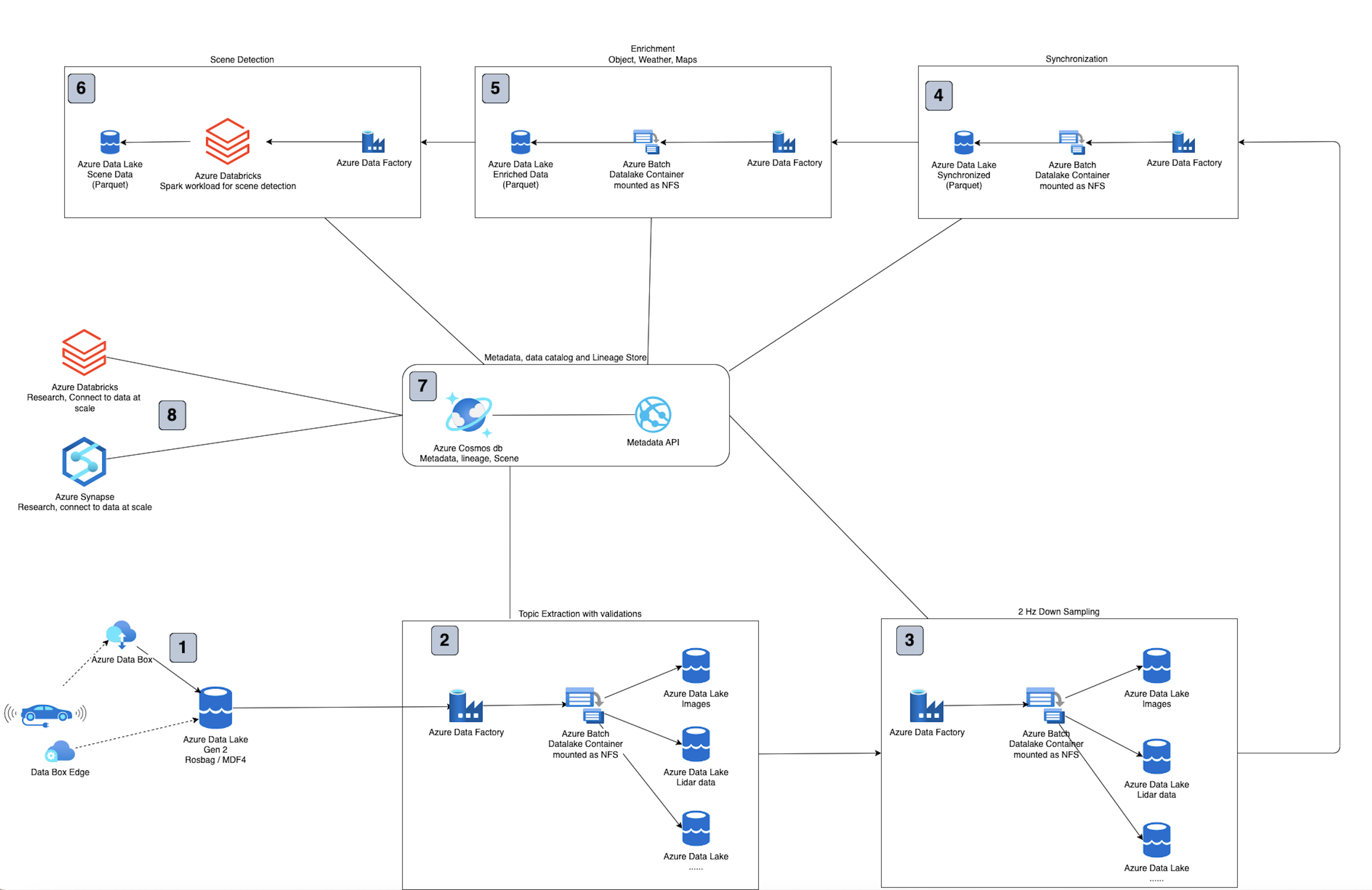
-
Data copied from vehicle to Azure Data box or Azure Data Box (Edge) which is later sent to Azure data center for copy to Azure Data Lake Landing zone.
-
Azure Data Factory pipeline for extracting the data from Landing zone is triggered.
-
Azure batch uses the mounted folder from Azure data lake to extract the data in a canonical folder location in extracted zone of Azure Data Lake. A folder for each topic like camera, GPS, LiDAR, radar, etc.
-
We used AZCopy running on Azure Batch to copy files across storage accounts as it was more performant and cost effective.
-
In each storage account, we store the data in a hierarchical structure ex: in the raw storage account, it will be
raw/YYYY/MM/DD/VIN/MeasurementID/DatastreamID
-
-
Azure Data Factory pipeline for down sampling the data to reduce the amount of data to label/annotate. Code for downsampling can be run on Azure Batch.
-
Azure Data Factory pipeline for Synchronization (algorithmic) of data across sensors. Alternatively, the synchronization could have happened at the device level itself.
-
Azure Data Factory pipeline for further enriching the data with weather, maps or objects. Data generated can be kept in Parquet files to relate with the synchronized data. Metadata about the enriched data is also stored in Metadata store.
-
Azure Data Factory pipeline for scene detection. Scene Metadata is kept in the metadata store while scenes themselves as objects can be stored in Parquet files.
-
Metadata store (Azure CosmosDB) to store metadata about measurements (drive data), lineage of data as it goes though each process of extraction, downsampling, synchronization, enrichment and scene detection; Metadata about enrichment and scene’s detected. Metadata API to access measurements, Lineage, and scenes and find out which data is stored where. The Metadata API thus becomes the storage layer manager which can spread data across storage accounts and helps the developer finding out data location using metadata based search.
-
Azure Databricks / Azure Synapse to connect with Metadata API and access the azure data lake storage and research on the data. This enables the ML engineers or data scientists to search for interesting images across the datastreams and select them for further processing.
Summary
Each step in the AVOps journey is complex and fraught with many challenges. In this article, we provided you with a glimpse into one of the first steps of data processing. As a next step, do check out the overall AVOps reference architecture.