
Business Problem
For businesses of all sorts, one of the great advantages of the shift from physical to digital documents is the fast and effective search and knowledge extraction methods now available. Gone are the days of reviewing documents line-by-line to find particular information. However, things get more complicated when the researcher needs to extract general concepts, rather than specific phrases. And it’s even more complicated when applied to mixed-quality scanned documents containing handwritten annotations.
Microsoft recently teamed with EY (Ernst & Young Global Limited) to improve its contract search and knowledge extraction results. EY’s professional services personnel spend significant amounts of time reviewing clients’ contracts in order to extract information about relevant concepts of interest. Automated entity and knowledge extraction from these contracts would significantly reduce the amount of time their staff need to spend on the more mundane elements of this review work.
It is challenging to achieve acceptable extraction accuracy when applying traditional search and knowledge extraction methods to these documents. Chief among these challenges are poor document image quality and handwritten annotations. The poor image quality stems from the fact that these documents are frequently scanned copies of signed agreements, stored as PDFs, often one or two generations removed from the original. This causes many optical character recognition (OCR) errors that introduce nonsense words. Also, most of these contracts include handwritten annotations which amend or define critical terms of the agreement. The handwriting legibility, style, and orientation varies widely; and the handwriting can appear in any location on the machine-printed contract page. Handwritten pointers and underscoring often note where the handwriting should be incorporated into the rest of the printed text of the agreement.
We collaborated with EY to tackle these challenges as part of their search and knowledge extraction pipeline.
Technical Problem Statement
Despite recent progress, standard OCR technology performs poorly at recognizing handwritten characters on a machine-printed page. The recognition accuracy varies widely for the reasons described above, and the software often misplaces the location of the handwritten information when melding it in line with the adjoining text. While pure handwriting recognizers have long had stand-alone applications, there are few solutions that work well with document OCR and search pipelines.
In order to enable entity and knowledge extraction from documents with handwritten annotations, the aim of our solution was first to identify handwritten words on a printed page, then recognize the characters to transcribe the text, and finally to reinsert these recognized characters back into the OCR result at the correct location. For a good user experience, all this would need to be seamlessly integrated into the document ingestion workflow.
Approach
In recent years, computer vision object detection models using deep neural networks have proven to be effective at a wide variety of object recognition tasks, but require a vast amount of expertly labeled training data. Fortunately, models pre-trained on standard datasets such as COCO, containing millions of labeled images, can be used to create powerful custom detectors with limited data via transfer learning – a method of fine-tuning an existing model to accomplish a different but related task. Transfer learning has been demonstrated to dramatically reduce the amount of training data required to achieve state-of-the-art accuracy for a wide range of applications.
For this particular case, transfer learning from a pre-trained model was an obvious choice, given our small sample of labeled handwritten annotation and the availability of relevant state-of-the-art pre-trained models.
Our workflow, from object detection to handwriting recognition and replacement in the contract image OCR result, is summarized in Figure 1 below. To start, we applied a custom object detection model on an image of a contract printed page to detect handwriting and identify its bounding box.
The sample Jupyter notebook for object detection and customizable utilities and functions for data preparation and transfer learning in the new Azure ML Package for Computer Vision (AML-PCV) made our work much easier. The AML-PCV notebook and supporting utilities take advantage of the Faster R-CNN object detection model with Tensorflow back-end, which has produced state-of-the-art results in object detection challenges in the field.
Our project Jupyter Notebooks using AML-PCV are available on our project GitHub repo. You can find more details on the implementation and customizable parameters in AML-PCV available on the Tensorflow object detection website. AML-PCV comes with support for transfer learning using faster_rcnn_resnet50_coco_2018_01_28, a model trained on the Coco Common Object in Context dataset containing more than 200k labeled images and 1.5 million object instances across 80 categories.
For our custom application, we used the Visual Object Tagging Tool (VOTT) to manually label a small set of public government contract data containing both machine-printed text and handwriting, as we’ll detail in the data section below. We labelled two classes of handwriting objects in the VOTT tool – signatures and non-signature (general text such as dates) – recording the bounding box and label for each instance. This set of labeled data were passed into the AML-PCV notebook to train a custom handwriting detection model.
Once we had recognized the handwritten annotations, we used the Microsoft Cognitive Services Computer Vision API to apply OCR to recognize the characters of the handwriting. You can find the Jupyter Notebooks for this project, and a sample of the data on the project GitHub repo.
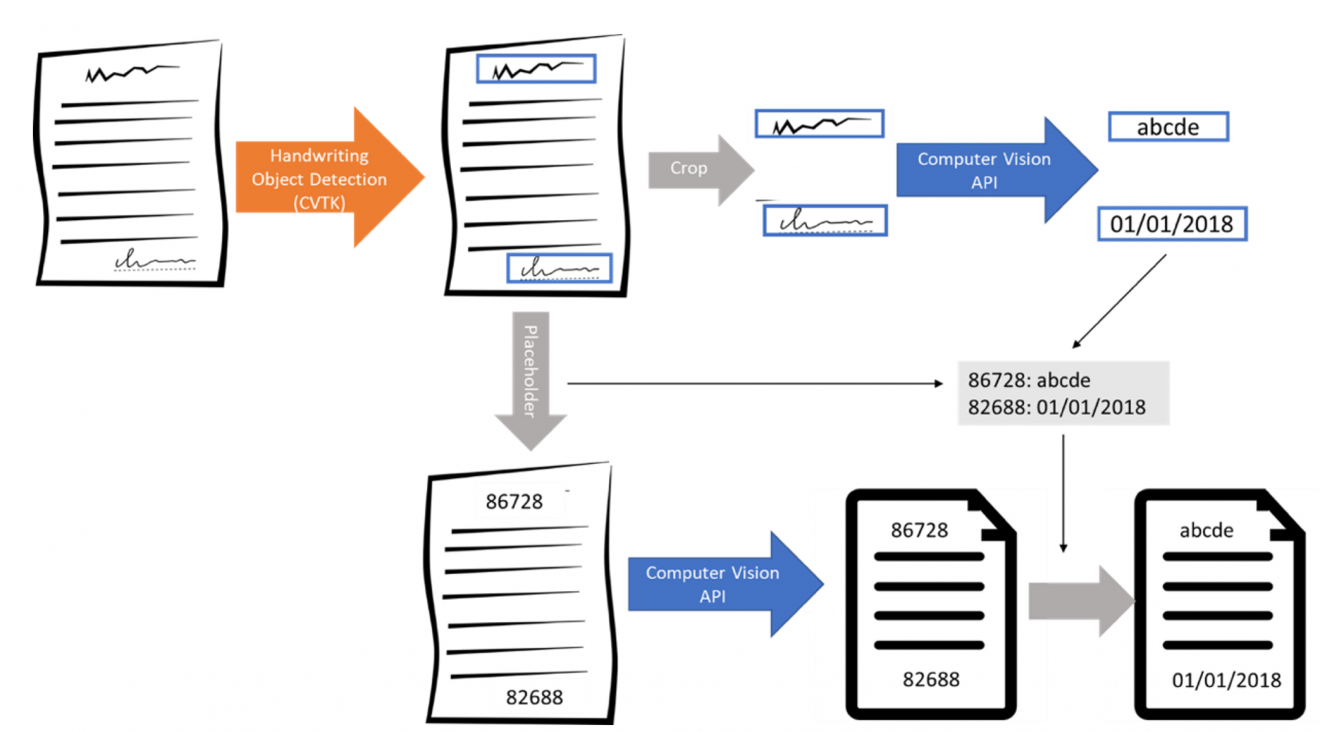
Figure 1. Model Workflow
The Data
Using VOTT allowed us to produce a training set of 182 labelled images from a sample of Government contracts in a matter of a few hours. We drew our test set from an additional 100 contract images, chosen from different states than the training set. As described in the approach, we labelled two classes: handwritten signatures and handwritten non-signatures. Our objective was primarily to correctly interpret the non-signature objects, as these were germane to the entities and concepts we were trying to extract. The signatures typically did not contain this payload. Classifying signature handwriting as a different class allowed us focus on the non-signature handwriting that was of interest.
The output of VOTT writes an XML file for each image in Pascal-VOC format, with bounding box location information for each labelled object. This format can be read into the AML-PCV directly, with further processing done by utilities called from the notebook. You can access the full set of images and labeled data from this project on an Azure blob public data repository with URI https://handwriting.blob.core.windows.net/leasedata. You can also find a smaller sample of the data in the project GitHub repo. Figure 2 shows an example of a typical contract section with relevant handwritten parts – in this case the start date of a real estate lease.

Figure 2. Screenshot of a Contract with Handwriting
Method
Here we provide detail on using the vision toolkit to train the custom object detection model.
One of the key timesavers provided by the AML-PCV utilities is the utilities to recognize, format, and pre-process our labeled training and test data. The code below will import the VOTT labeled dataset and pre-process images to create a suitable training set for the Faster-RCNN model:
import os, time from cvtk.core import Context, ObjectDetectionDataset, TFFasterRCNN from cvtk.utils import detection_utils image_folder = "<input image folder including subfolders of jpg and xml>" # training data from VOTT labeling tool model_dir = "<saved model directory>" # dir for saved training models image_path = "<test image path>" # scoring image path result_path = "<results path>" # dir for saving images with detection boxes and placeholder text data_train = ObjectDetectionDataset.create_from_dir_pascal_voc(dataset_name='training_dataset', data_dir=image_folder)
Below are the default hyperparameter selections for our handwriting object detection model. Since the default minibatch size is set to 1, we set the num_steps equal to the num_epochs multiplied by the number of images in the training set. The learning rate and step number are default parameters from AML-PCV and discussed in details in the notebook.
score_threshold = 0.0 # Threshold on the detection score, use to discard lower-confidence detections.
max_total_detections = 300 # Maximum number of detections. A high value will slow down training but might increase accuracy.
my_detector = TFFasterRCNN(labels=data_train.labels,
score_threshold=score_threshold,
max_total_detections=max_total_detections)
# to get good results, use a larger value for num_steps, e.g., 5000.
num_steps = len(dataset_train.images)*30
learning_rate = 0.001 # learning rate
step1 = 200
start_train = time.time()
my_detector.train(dataset=data_train, num_steps=num_steps,
initial_learning_rate=learning_rate,
step1=step1,
learning_rate1=learning_rate)
end_train = time.time()
print("the total training time is {}".format(end_train-start_train))
With these parameter settings and our training set of 182 images, training took 4080 seconds on a standard Azure NC6 DLVM (Azure Deep Learning Virtual Machine), with one GPU.
Let’s examine the pipeline on one government contract page below. Figure 3 shows the detected handwriting boxes in the contract – blue for non-signature and green for signature. If we are able to recognize the handwritten words, the challenge then is to decide where to insert this in the output of the printed text OCR process.
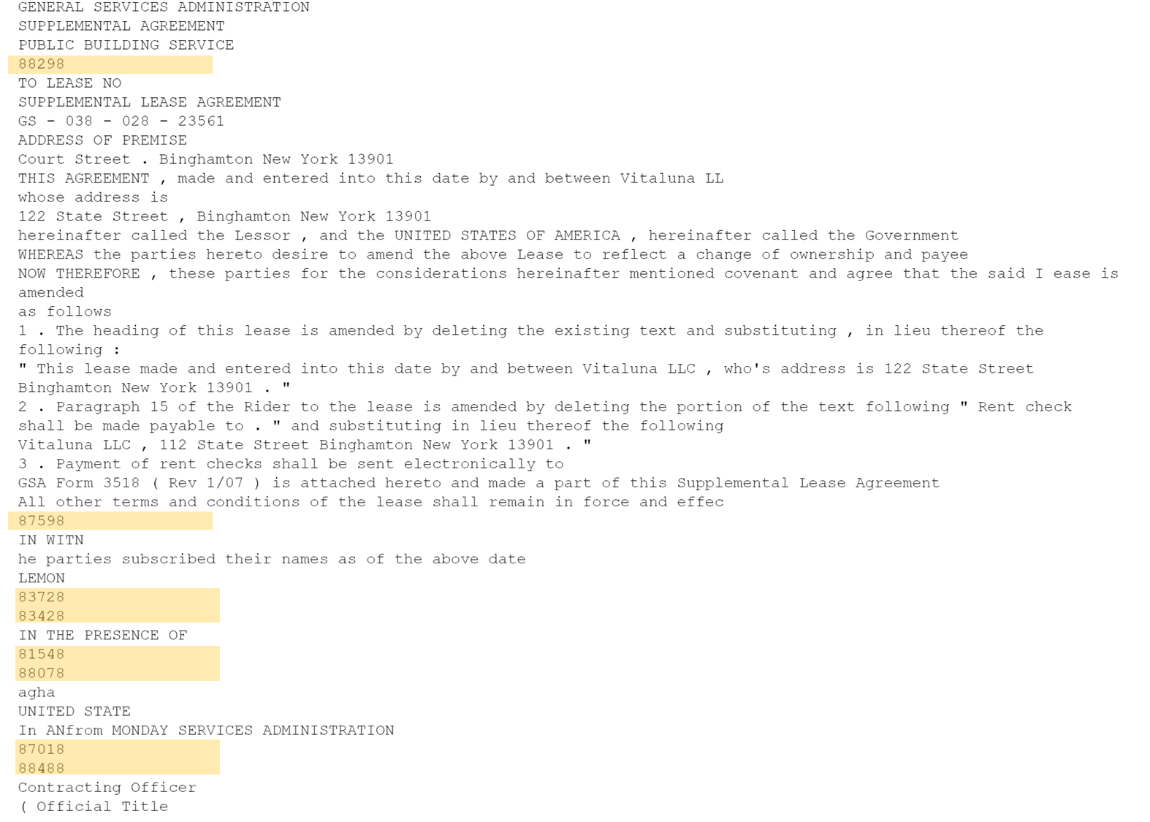
Our approach was to generate unique tokens designed to be reliably transcribed by the OCR software. We then inserted those tokens in the areas where we detected handwritten text, replacing the original handwritten section, and using these tokens as anchor points in the OCR output. After some experimentation, we proceeded with tokens comprising 5 digits, starting and ending with the number “8”, with 3 randomly generated numbers in between. Figure 4 shows the result of replacing the original text with these numbers.

Figure 3. Annotated Handwriting in One Page of PDF Contract

We then used the Microsoft Cognitive Services Computer Vision API OCR service to transcribe each detected handwriting box. Below is a helper function from our notebook to call to the Computer Vision API and return recognized characters.
def pass2CV(img_array):
import requests
print ('pass image to computer vision API ......')
image_data = cv2.imencode('.jpg', img_array)[1].tostring() # convert image array to image bytes
vision_base_url = "https://westus2.api.cognitive.microsoft.com/vision/v1.0/"
#International URLs: Replace 'westus2' with your local area, for example 'westeurope' or 'eastasia’.
#Full list of internal URL’s is available at this link:
#https://westus.dev.cognitive.microsoft.com/docs/services/56f91f2d778daf23d8ec6739/operations/56f91f2e778daf14a499e1fa
text_recognition_url = vision_base_url + "RecognizeText"
# change to your Computer Vision API subscription key
headers = {'Ocp-Apim-Subscription-Key': subscription_key,
"Content-Type": "application/octet-stream"}
params = {'handwriting' : True}
response = requests.post(text_recognition_url, headers=headers, params=params, data=image_data)
response.raise_for_status()
operation_url = response.headers["Operation-Location"]
import time
analysis = {}
while not "recognitionResult" in analysis:
response_final = requests.get(response.headers["Operation-Location"], headers=headers)
analysis = response_final.json()
time.sleep(1)
polygons = [(line["boundingBox"], line["text"]) for line in analysis["recognitionResult"]["lines"]]
return polygons
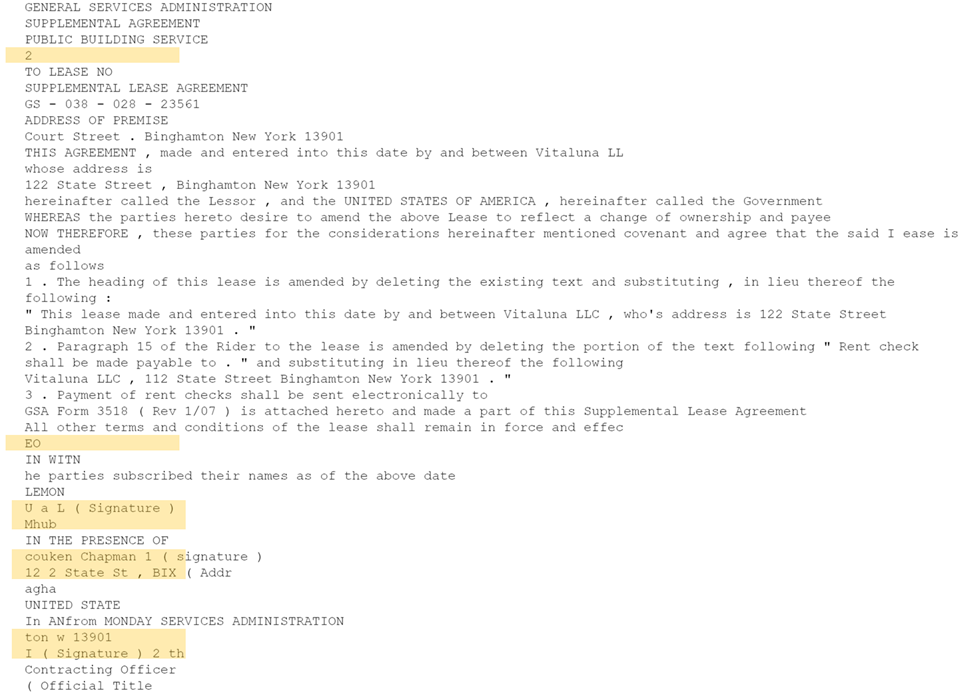
Meanwhile, we built a dictionary matching the anchor digits with the handwriting OCR results. This simplifies our final task of replacing the anchor strings in the printed OCR results. Below, we see a sample of the dictionary for handwriting boxes in Figure 3.
{'81548': 'couken Chapman 1 ( signature )',
'83428': 'Mhub',
'83728': 'U a L ( Signature )',
'87018': 'ton w 13901',
'87598': 'EO',
'88078': '12 2 State St , BIX ( Addr',
'88298': '2',
'88488': 'I ( Signature ) 2 th'}
In the last step, we matched the handwriting detected blocks with the dictionary and replaced the placeholder text with the OCR result from the Computer Vision API. Figure 5a shows OCR results for the contract page, where the placeholder text is detected well. Then, based on the dictionary above, we replaced the digits with the handwriting OCR results from Computer Vision API. The results are shown in Figure 5b.
Results
There were two main components to this project: handwriting object detection and handwriting OCR. The results on detecting handwritten words were promising. Transcribing the handwritten text was less successful and only occasionally produced useful results. Performance metrics were calculated as described below:
Our test set comprised 71 contract pages from the same government contract data source, but not yet seen by our model. All pages had both signature and non-signature handwriting present on the image.
For each image, we defined two groups:
- At = union of pixels inside true label bounding boxes (ground truth, green squares below).
- Am = union of pixels inside bounding boxes found by the model (red squares below).
Then we used the union of these two groups, instead of the sum, to account for overlapping boxes. We defined ‘success’ for our objective as:
- Ai = intersection between At and Am.

We refined the traditional intersection over union (IOU) object detection results measures for our task, as we were interested in our ability to retrieve just the areas of interest within a machine printed text, and within the non-signature handwriting to detect as precisely as possible to enable accurate OCR in the later process. We defined our results on a per image (or per page) basis as follows:
- per-image recall = Ai / At, i.e. the fraction of target pixels actually covered by the model.
- per-image precision = Ai / Am, i.e. what fraction of the pixels detected were in the actual handwriting box.
We calculated per image recall and precision for each category with our test set. For pages where the model detects non-signature handwriting but there is no non-signature handwriting in the ground truth for that detected location or vice versa, we will define precision = 0 and recall =0, which gives us a conservative performance measure.
Figure 7 shows the min, max, 25% quantile, 75% quantile and median of these metrics over all the test images. For more than 25% of the images, the non-signature precision and recall are zero. Manual inspection shows that some of these are due to incorrect labeling or noisy artifacts of the scan being recognized incorrectly. Additional training data could potentially improve these results.
Our results on the handwriting object detection were relatively good for both signature handwriting detection and non-signature handwriting object classes. The performance of non-signature handwriting detection is slightly worse and more variable than that of signature handwriting detection.
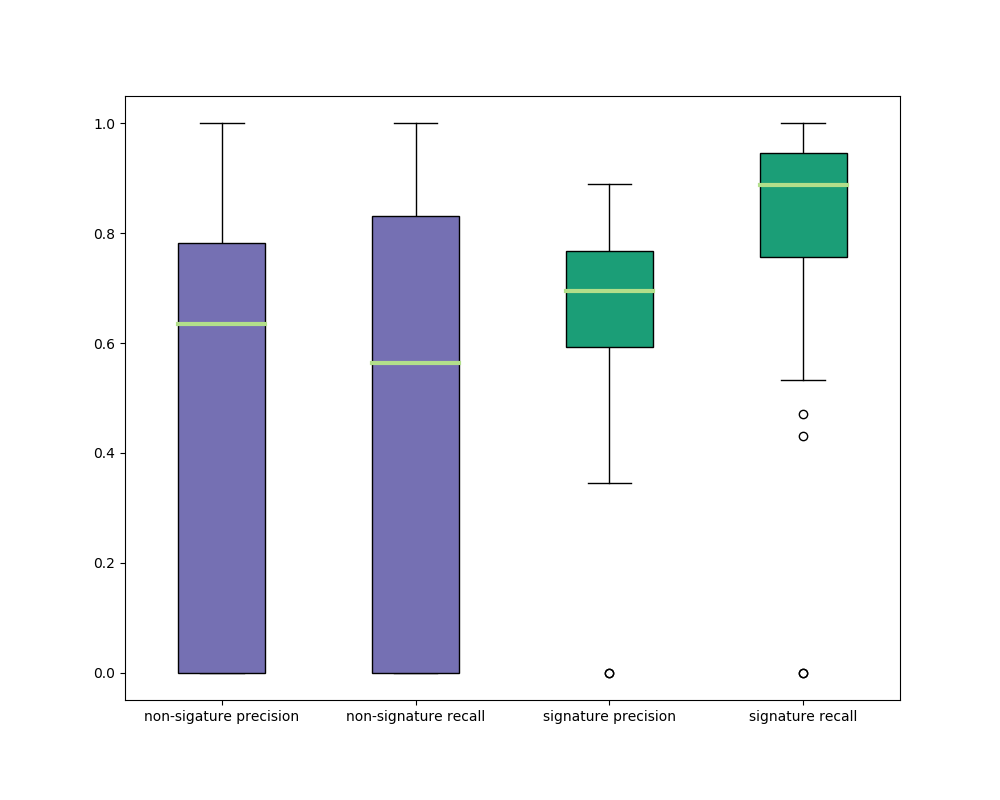
Figure 8 gives an example where there is a missing labeling in the ground truth, but the model detects it. On the figure, the green box represents the ground truth and the red box is model prediction. In this case, we defined that precision and recall=0.

Our results on the Computer Vision API handwriting OCR had limited success and reveal an area for future work and improvement. This OCR leveraged the more targeted handwriting section cropped from the full contract image from which to recognize text. The table below shows an example comparing the Computer Vision API and Human OCR for the page shown in Figure 5. Following standard approaches, we used word-level accuracy, meaning that the entire proper word should be found. It shows that the accuracy for pure digits and easily readable handwriting are much better than others. We plan to update our results with the new Cognitive Services Computer Vision API OCR capabilities, which include updates of their handwriting OCR capabilities coming in the near future.

Conclusion
For EY, the handwriting recognition function and the integration of handwriting OCR back into page OCR unblocked their contract search scenario, saving sometimes hours of review time on each contract. While the handwriting character recognition portion of the solution did not do so well, the solution already improved the performance of the existing system. Alternative handwriting OCR tools and models can easily be integrated into the pipeline if exposed as APIs. As we mentioned, we plan to update our solution with the improved Cognitive Services Computer Vision API OCR capabilities.
We leveraged the Azure ML Package for Computer Vision, including the VOTT labelling tool, available by following the provided links. Our code, in Jupyter notebooks, and a sample of the training data are available on our GitHub repository. We invite your comments and contributions to this solution.