



Introduction
You have built out a generative AI application. Now are you wondering how to assess that your application is returning quality results? Have you considered using Azure AI Foundry to evaluate your application? If you are wondering how to start programmatically evaluating your application in a way that is both adaptable and extensible, while also leveraging the features of Azure AI Foundry, this blog post may be a good place to start.
Azure AI Foundry provides a platform of tools for evaluating how your generative AI application performs. Out of the box, Foundry offers several built-in evaluation metrics that may be run against a test dataset. In addition to the ability to leverage these built-in evaluation metrics, Foundry also allows for creating custom evaluators which output customized metrics. Custom evaluators for local evaluations are built using the Azure AI Evaluation SDK, which is available in Python. The documentation offers two options for custom evaluators: code-based evaluators and prompt-based evaluators.
Depending on your evaluation needs, you may want to leverage code-based evaluators to accomplish generating custom metrics such as BERT or MOVERS scores. Another great use case for a code-based evaluator would be a custom evaluation of token usage. Perhaps there is a target maximum limit of token usage per user interaction with your generative AI application. A simple code-based evaluator would be able to take the tokens used as input and output a percentage of target tokens utilized based on a configured maximum value. As another example, a great use case for a code-based evaluator would be to assess if the expected function (or plugin) calls of a generative AI application are those that were expected to be invoked. The Semantic Kernel SDK allows for the kernel context to be returned via a FunctionInvocationFilter. This context, along with the Semantic Kernel ChatHistory object, provides visibility into what functions are available and which ones are ultimately called and with what arguments. This supporting metadata can be fed into your evaluation system to determine how well the user-defined expected function invocations align with the actual function calls.
There are also many great use-cases for prompt-based evaluators. Using an LLM to evaluate the output of a generative AI application has become increasingly popular, as indicated by the number of AI-assisted built-in evaluators present in Foundry. What if the evaluations provided by the built-in AI-assisted evaluators do not produce as accurate results as desired for a specific use-case? The prompts used for these built-in AI-assisted evaluators are open source (check out the evaluators’ .prompty files here), and can be tweaked and used in a custom prompt-based evaluator to fit better to a specific use case. Alternatively, perhaps you are evaluating an application to ensure that any system responses back to a user are positive and helpful. An LLM evaluation could take in the system response and assess the sentiment of the statement to be returned as a metric for analysis.
Custom evaluators can add great value to your evaluation process; However, built-in evaluators can be just as useful! So what if both should be used? Evaluation can quickly become complicated as a variety of scenarios handled by a generative application need to be evaluated with different evaluators, each having different settings, and potentially each having a variety of arguments and configurations needed. This necessitates an evaluation system needing to be customizable and extensible enough to handle this complexity.
This blog post will guide you through building such a system, covering:
- Considerations for experimentation files
- Creating a configuration system for evaluators
- How custom AI-assisted evaluators might be implemented
Experimentation Files
According to the documentation for the Azure AI Evaluation SDK, the evaluate() API accepts data in JSONLines format. In the provided example, values are provided for the query, context, response, and ground_truth fields. Even though these are the various required fields for the built-in evaluators, and the format of .jsonl may be limited, the data input into your experiment should NOT be restricted. Interestingly, while the documentation indicates context should be a string, a JSON object input into the context also works and produces appropriate results for built-in evaluators such as groundedness and retrieval:
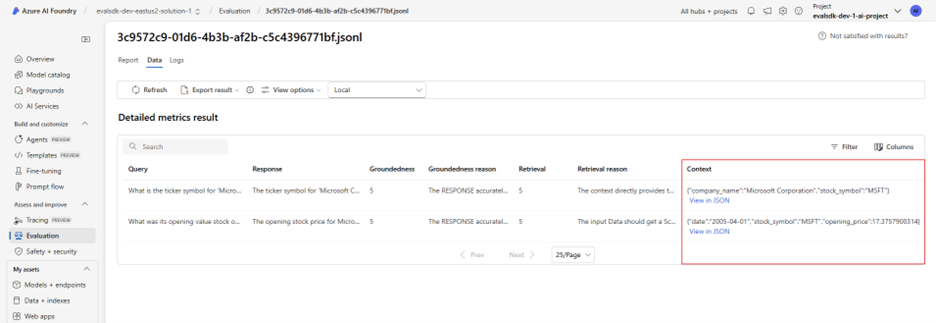
In the pictured example, a “groundedness reason” reports:
The RESPONSE accurately conveys the information from the CONTEXT without introducing any unsupported details or omitting critical points, making it fully grounded and complete.
and one of the “retrieval reasons”:
The input Data should get a Score of 5 because the context fully addresses the query, providing the exact opening stock value for MSFT on the specified date, and it is presented in a clear and direct manner.
Additionally, even though query, context, response, and ground_truth may be the available required fields for built-in evaluators, this does not mean that other fields cannot be included in the experiment .jsonl’s. Any arbitrary field may also be included and then utilized in a custom evaluator. To return to the custom token utilization example, a line in experiment.jsonl may contain the following information:
{
"query": "What is the ticker symbol for 'Microsoft Corporation'?",
"ground_truth": "The ticker symbol 'Microsoft Corporation' is 'MSFT.",
"context": {
"company_name": "Microsoft Corporation",
"stock_symbol": "MSFT"
},
"response": "The ticker symbol for 'Microsoft Corporation' is MSFT.",
"total_token_count": 691
}Then the __call__() method in a custom TokenCountEvaluator just needs to accept the total_token_count parameter.
"""Evaluates token usage as a percentage of maximum allowed tokens."""
from dataclasses import dataclass, field
from typing import Any, Optional, override
@dataclass
class TokenPercentageCustomEvaluator():
"""
Evaluates token usage as a percentage of maximum allowed tokens.
Attributes
----------
- _max_tokens:int
"""
max_tokens: int = field(init=False, default=1000)
@override
async def __call__(
self,
*,
total_token_count: int,
**kwargs: Optional[dict[str, Any]],
) -> str:
"""Evaluate the percentage of tokens used."""
return str(total_token_count/self.max_tokens * 100)Evaluator Configuration
As the need arises for a mixture of built-in and custom evaluators, with a variety of combinations needed to be run at various times, a mechanism for evaluator configuration can be very helpful. A useful configuration for the evaluators may contain:
- Evaluator name
- Model config details
- Connection type (i.e. AzureOpenAI)
- Deployment name
- API version
- Column mappings (refers to the
experiment.jsonlfields) - Arguments
- Any defaults for the above
Given that any number of evaluators may be required to run at one time, each with potentially different configurations for AI model configurations and column mappings, an adaptable evaluator configuration can be very helpful; however, keeping this configuration as simple as possible is also important for readability.
The configuration below demonstrates a flexible approach where common settings are defined once in defaults and can be overridden at the evaluator level when needed. This reduces repetition while maintaining the flexibility to customize individual evaluators:
{
"defaults": {
"client": {
"type": "AzureOpenAI",
"api_version": "2024-06-01",
"model": "gpt-4o-mini"
},
"column_mapping": {
"query": "${data.query}",
"context": "${data.context}",
"response": "${data.response}",
"ground_truth": "${data.ground_truth}"
}
},
"evaluators": [
{
"name": "custom_similarity",
"custom": true
},
{
"name": "meteor_score",
"arguments": {
"alpha": 0.9,
"beta": 3.0,
"gamma": 0.5
}
},
{
"name": "custom_token_usage_percent",
"custom": true
}
]
}An evaluation system can leverage these configurations to assess different experiment.jsonl files. It can distinguish between custom and built-in evaluators, and have access to the necessary information to populate a model_config– which may also be defined at the evaluator level. Column mappings for resolving data from the JSONL files are available and can likewise be specified per evaluator. Additionally, all required arguments for each evaluator are provided.
For an example implementation, an evaluation service could be passed a series of key/value pairs that indicate which evaluator class to instantiate based on this configuration as a part of any evaluation run. For example, a python service would have this dictionary passed in:
service = ExperimentService(
evaluator_types=
{
"custom_token_usage_percent": TokenPercentageCustomEvaluator,
"meteor_score": MeteorScoreEvaluator,
"relevance": RelevanceEvaluator,
"retrieval": RetrievalEvaluator,
"rouge_score": RougeScoreEvaluator,
}
)Upon evaluation, the appropriate constructor can be found as keyed by its name and on evaluator class instantiation, the arguments specified in the config can simply be passed in and the evaluate() method called with the instantiated evaluators; i.e.
evaluate(
...
evaluators=[your_list_of_instantiated_evaluators]
)Implementing Custom AI-Assisted Evaluators
As linked above, prompt-based custom evaluators can be built using a Prompty file. The implementation shown in the documentation appears as though a prompt flow is actually created as a part of the evaluator call, however, this does not seem to be the case. Nevertheless, there may be reasons for not wanting to use Prompty files as a part of the evaluator, such as wanting more fine-grained prompt control depending on certain logic or the desire to not have an entire file for simpler, smaller prompts. Another option is to configure the LLM client directly within the custom evaluator and call the LLM directly on evaluator invocation. In this way, there is total control over the LLM calls. As an example, a simple custom similarity evaluator could directly invoke a chat completion and look like the following:
@dataclass
class SimilarityAzureOpenAICustomEvaluator():
"""
Custom evaluator that uses Azure OpenAI to assess similarity between response and ground truth.
Attributes
----------
- _ai_services_client_oai:AsyncAzure
- _model:str
- prompt:str
"""
azure_openai_client: AsyncAzureOpenAI = field(init=False)
model: str = field(init=False, default="")
prompt: str = field(init=False, default=SIMILARITY_PROMPT)
@override
async def __call__(
self,
*,
query: str,
response: str,
ground_truth: str,
**kwargs: Optional[dict[str, Any]],
) -> EvaluatorResult:
"""Evaluate the similarity between the response and ground truth."""
logger.debug("Calling AzureOpenAIEvaluator with response: %s and ground_truth: %s", response, ground_truth)
logger.debug("Running similarity evaluation with response: %s and ground_truth: %s", response, ground_truth)
response = await self.azure_openai_client.chat.completions.create( # type: ignore
model=self.model,
messages=[
{"role": "system", "content": self.prompt},
{"role": "user", "content": f"The first string to compare is {response}"},
{"role": "user", "content": f"The second string to evaluate against is {ground_truth}"},
],
)
first_choice: Choice = response.choices[0]
evaluation: Optional[str] = first_choice.message.content
logger.info("Similarity evaluation response for response: %s and ground_truth: %s is: %s", response, ground_truth, evaluation)
return evaluation or ""Conclusion
Evaluation of a generative AI application can be just as (if not more) important than the application itself! A robust evaluation strategy helps ensure your application delivers consistent, high-quality results as it evolves.
The feature image was generated using DALL-E-3.