

The intent of this blog post is to showcase a collaborative customer engagement with ISE, providing an in-depth exploration of the development and evaluation process of a custom AI Copilot solution for robotic code generation. Developing efficient, reliable code for robotic systems presents unique challenges, especially for users unfamiliar with specialized languages. Robotic programming often requires precise instructions for movement, sensor integration, and task coordination, all tailored to the hardware and capabilities of a robot. Addressing these complexities, the AI Copilot aims to simplify this process, making robotic programming more accessible.
In this post, you’ll discover detailed explanations of the evaluation metrics, data sources, and strategies employed to ensure the copilot’s performance aligns with expert standards. By exploring various testing strategies, retrieval techniques, and expert assessments, this post equips you with valuable insights into the journey of optimizing AI-driven code generation.
Please note that this blog post does not specify a single correct way to create or evaluate such solutions, as actual methodologies will differ based on unique requirements, project goals, and contextual factors.
Introduction
Developing efficient, reliable code for robotic systems can be a daunting challenge, especially for users unfamiliar with specialised languages. Here at ISE, we have had the privilege to work with one of Microsoft’s customers developing those robotics systems and a specialised language to operate them. Together, we set out to build a Code Generation Copilot, an AI assistant capable of converting natural language into robotic code. The copilot aimed to simplify the programming of a robot, making it more accessible to users with varying levels of expertise.
While building the copilot itself was a significant task, our primary focus during this project was on evaluating how well it could perform this task—measuring the quality of the generated code through a comprehensive, data-driven approach.
TL;DR
Our project centred on creating a Code Generation Copilot that translates natural language commands into robotic code. Robotic code is a specialised type of programming code used to control and automate the actions of robots. Unlike general-purpose programming languages, robotic code often includes specific instructions for movement, sensor integration, and task execution tailored to the robot’s hardware and capabilities.
A key part of our journey was evaluating the generated code through:
- Developing performance metrics with expert input (LLM-based metrics, traditional text metrics, and code parser).
- Conducting rigorous testing, including functional, performance, and safety tests, to ensure reliability across varied scenarios.
- Gathering diverse datasets, including user feedback, which was essential to refine the system based on real-world usability and needs.
- Exploring advanced retrieval and search strategies to enhance the relevance and accuracy of generated code.
- Benchmarking system performance against expert feedback to validate and improve our results.
In this blog post, we dive deep into how we evaluated the copilot’s performance, the methods we used, and the key insights we gained about optimizing AI-driven code generation.
Project Overview
The primary goal of our project was to develop a Code Generation Copilot capable of producing raw code for robotic programming using a specialised programming language. The solution would operate through a chat interface, where a user asks a question and describes the functionality of the desired program.
Why not use existing AI coding assistants?
The copilot had to generate the code in the specific, specialised language for operating customer robots. While general AI coding assistants like GitHub Copilot are effective for mainstream languages, they would not be suitable for this particular case. The coding assistant would need to acquire knowledge about the rules and best practices of programming in the new language, which is not available on the wide Internet.
Customizing GitHub Copilot via fine-tuning was also considered. However, this approach relies on inferring the required knowledge from an existing code base, while our project focused on explicitly incorporating specialised knowledge through examples and rules. This approach was chosen because the data required for fine-tuning was not readily available, and we were interested in understanding the performance of pre-trained models. Depending on data availability and project requirements, one approach might be preferable over another, or they could be combined. Establishing a way to measure and compare the copilot’s performance allows for data-driven decisions on the best approach for specific tasks. This leads us to the objectives of our engagement.
Objectives and Hypotheses
In the beginning of the project, we decided to focus on three main objectives:
- Establishing Relevant Metrics: We hypothesised that by working with subject matter experts, we could develop metrics to accurately measure the performance of our code generation model.
- Synthetic Data: We believed that some of the existing raw data could be transformed into structured synthetic data, enhancing our copilot solution.
- Leveraging Off-the-Shelf Models: By integrating existing Azure OpenAI models with a retrieval-augmented generation system, we aimed to create a service that could generate valid code based on natural language queries.
Those specific hypotheses were formulated to establish a data science-driven foundation for the project. We needed to test them to determine the copilot’s development trajectory. Could we establish a way to measure the performance of the model without solely relying on human experts? What data would we need for this, and could we augment it with synthetically generated sources to speed up the process? Would the performance of the latest Azure OpenAI models be sufficient for the task?
These hypotheses guided our approach, providing a framework for experimentation and evaluation. To verify them, high-quality data was essential, as it would directly impact the accuracy and reliability of our results, leading us to the next crucial aspect of our project: data acquisition and management.
Data: The Backbone of Our Project
Data quality was crucial for evaluating our solution. We recognised early on that acquiring high-quality data would be essential for understanding the solution’s functionality, assessing the reliability of our metrics, and identifying areas for improvement. But what exactly does “high-quality” data mean in the context of LLM assessments?
What Does “High-Quality” Data Mean?
“High-quality” data is characterized by several key attributes that ensure the effectiveness and robustness of our LLM metrics:
- Accuracy: The data must be factually correct, whether it involves reference code, expected outputs, or test cases. Any errors in the ground truth data could lead to misleading metric evaluations, where the model is penalized or rewarded incorrectly. For instance, if the Copilot is instructed to generate code for a robot’s navigation through a grid, the ground truth code must precisely execute the grid movements without errors. Inaccurate reference data could lead to misleading evaluations, making it seem that the model performs poorly even when it’s correct. Accurate data ensures that LLM outputs are judged fairly.
- Relevance: The data must be aligned with the specific task or problem being addressed. Irrelevant data, or data that doesn’t match the intended function of the generated code, can result in inaccurate metric scores. For example, using a dataset about general-purpose Python scripts would be irrelevant for a robotic system requiring specialized commands for motor control and sensor integration.
- Diversity: To create robust and generalizable metrics, the data must represent a wide range of use cases, edge cases, and variations in code logic. For example, the dataset should cover both basic tasks (like simple movement sequences) and more complex tasks (like pathfinding with obstacle avoidance). Including both common use cases and rare, challenging scenarios ensures the model is tested for versatility and robustness. A diverse dataset challenges the model in different ways, helping to identify both strengths and weaknesses. This includes covering simple tasks, complex algorithms, and ambiguous scenarios where logical reasoning plays a critical role.
- Consistency: High-quality data should follow a consistent structure and format across all test cases. For example, if some reference code includes specific initialization functions and others do not, this could cause inconsistent results. Maintaining consistency ensures that each evaluation is conducted under uniform conditions. This reduces noise and variability in the results.
- Realism: Finally, high-quality data should simulate real-world scenarios as closely as possible. This means using actual user questions, realistic code bases, and practical coding challenges. The more realistic the data, the better the LLM’s performance will reflect its utility in real-world applications.
Without high-quality data, even the most sophisticated metrics would fail to provide accurate or useful evaluations. By ensuring the data is accurate, relevant, and diverse, we can maximize the reliability of our metrics and improve the overall performance of the LLM. In turn, this helps to ensure that the models are genuinely solving problems as intended, not just performing well in idealized or overly simplistic scenarios.
Did we have perfect-quality datasets for this project? No, but it was an iterative process of continuously improving various aspects. For instance, consistency was an immediate issue. We noticed that some reference code contained generic setup sections, while others didn’t. To address this, we introduced code templates and ensured consistent formatting across all samples. The commitment from the SMEs, who continuously addressed these issues and enhanced the data quality, was crucial in this process. This process is ongoing and will continue in the future.
Data Sources and Their Roles
We utilised four main data sources, each serving a distinct purpose:
1. Core Contextual Data for Code Generation
This data acted as the building blocks for code generation, providing the syntax rules, code examples, subfunctions, and system variables necessary for generating valid robotic code. Curated by subject matter experts, it created a foundational knowledge base that the copilot could rely on to produce accurate and functional code. During this phase of the project, we gathered 95 samples of context data, ensuring comprehensive coverage of essential programming topics and structures.
2. Q&A Evaluation Data
This evaluation dataset consisted of 29 high-level problems paired with expert-generated solutions. It was designed to test the copilot’s ability to handle complex queries, such as designing an application with subfunctions for control and integration. Additionally, this dataset allowed us to test the retrieval component separately by referencing relevant context data, helping us measure how well the system could retrieve and apply the right examples during the code generation process.
3. User Feedback Data for Real-World Interaction Insights
Gathering user feedback was crucial in understanding how real users would interact with the copilot. From the outset, we aimed to capture feedback from alpha users through an internal web app. This allowed us to assess how user inquiries aligned with our context and evaluation data, as well as to identify usability issues. For example, user queries frequently appeared in languages other than English, prompting us to adapt the web app’s interface. In total, we collected 74 unique conversation sessions, 27% of which provided feedback scores, with 11% offering detailed insights. This feedback was essential for refining the user experience and testing the copilot’s real-world application.
4. Expert Assessments for Quality Benchmarking
To capture the quality of the predictions on the evaluation dataset, we asked experts to label the generations based on their quality. We have collected the general quality from 1 to 5 (“Unusable” to “Very Good”) for general analysis and usage for correlation against evaluation metrics, as well as descriptive feedback for detailed understanding of the issues with the generated code.
To capture experts’ feedback efficiently, we deployed another web app developed with Streamlit. The ability to capture the feedback in a user-friendly way was crucial to expedite the labelling process. The feedback from experts was very positive about the experience. It also proved to be a fast and convenient way for Data Scientists to manually inspect the model’s predictions and analyse experts and LLM judges’ scores.
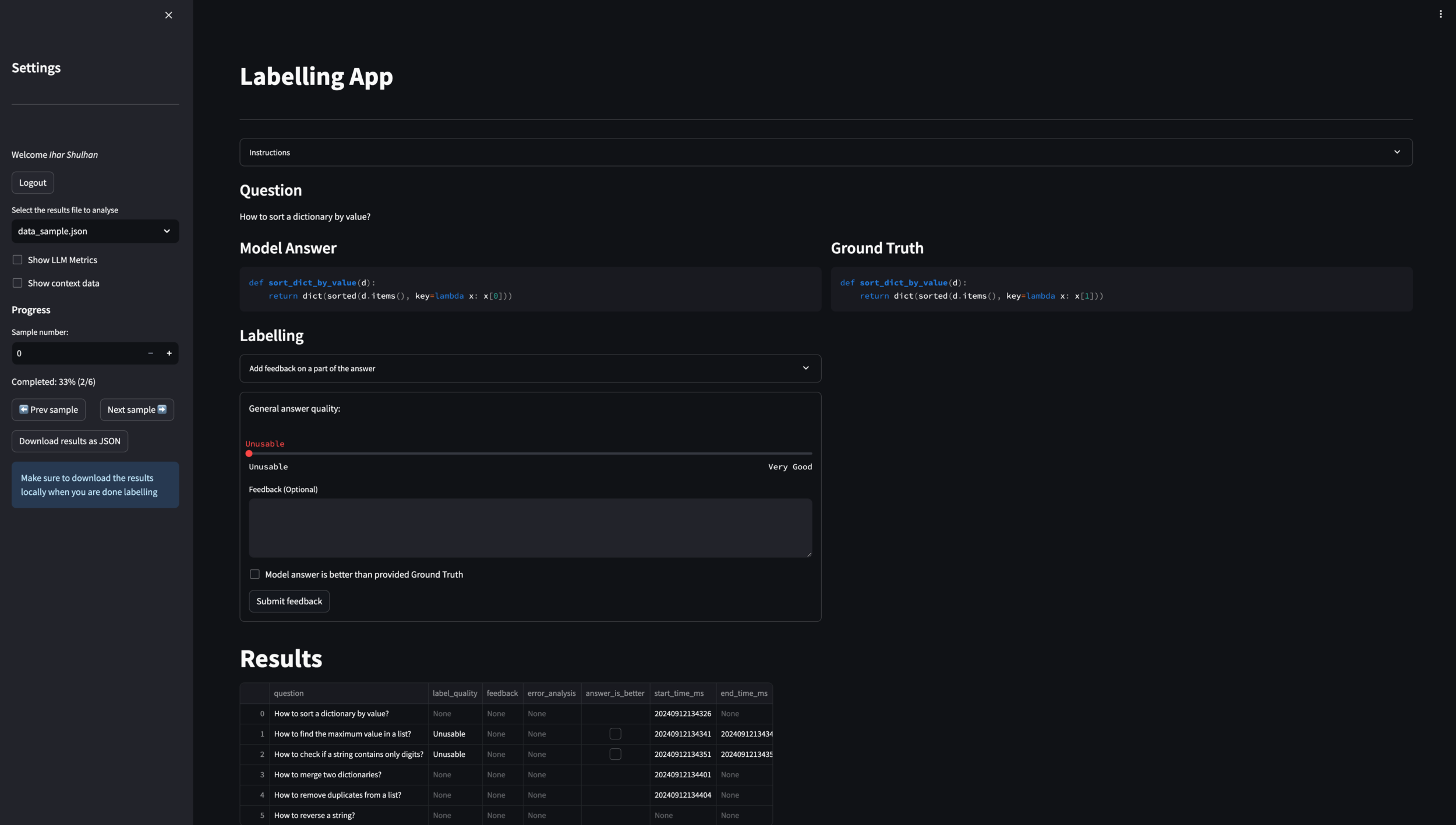 Figure: A web app for labelling allowed experts to quickly assess the quality of the generated code
Figure: A web app for labelling allowed experts to quickly assess the quality of the generated code
In total, we collected feedback from 3 experts over 10 runs, covering 280 unique model answers. Each run received labels from at least 2 experts.
Code Generation Approach and Evaluation
The Copilot utilised Azure OpenAI models by supplying a custom system message that incorporated key syntax rules, answer templates, and a general description of the assistant’s functionality. In addition to that, it took optional examples from the retrieval component and produced code based on user queries. While our web application supported both single-turn and multi-turn conversations, we chose to focus on evaluating single-turn conversations for a number of reasons.
In single-turn conversations, the user asks a question or provides a command, and the copilot generates a single, self-contained response. This is a simpler interaction model and allows for more straightforward evaluation of code quality and generation accuracy, as the system doesn’t need to maintain context across multiple exchanges.
On the other hand, multi-turn conversations involve back-and-forth dialogue between the user and the copilot. These require the system to retain and process context from previous turns, which adds a layer of complexity. For example, in a multi-turn scenario, the user might refine their request by asking the copilot to adjust part of the generated code in a subsequent interaction. Handling this properly requires the copilot to correctly track and interpret the evolving conversation, which poses significant challenges in managing conversation history and code dependencies.
Why Focus on Single-Turn Conversations?
We prioritised single-turn conversation evaluation because it allowed us to rigorously test the core functionality of the copilot without the added complexity of multi-turn context handling. By focusing on these single-turn interactions, we could ensure that the copilot could generate high-quality code for a wide range of isolated queries. This approach provided us with a clear and direct measure of the model’s ability to generate code based purely on the given query and retrieved context, without the influence of prior turns or conversation memory.
That said, multi-turn conversations are crucial for more advanced use cases, where users iteratively refine their requests. While we support multi-turn interactions in the web app, their complexity requires additional data collection to expand datasets with prior conversational history required to answer a request. Future evaluations will delve deeper into optimizing the copilot’s ability to handle such extended interactions effectively. Meanwhile, the ability to measure user feedback at different points in a conversation allows us to detect degradations in the performance and potential drifts over time.
Retrieval
The solution employed a retrieval component to identify the most relevant examples for the user query. The retrieval component searches for existing examples that match a user’s query, helping the copilot generate more accurate code. We utilised Azure AI Search to handle context data and assess various search strategies. Chunking, or dividing large documents into smaller, manageable parts for more targeted searching, was not necessary in our case due to the relatively small size of our context data.
Retrieval Strategies
We explored various search strategies to optimize the retrieval process:
- No Search: Used to evaluate how the Copilot performs without any relevant examples. Gives a lower boundary of the performance.
- Perfect Search: Labels from the evaluation dataset are used to directly extract the relevant examples marked by experts. Gives an upper boundary of the performance of the solution with an optimised retrieval component.
- All data: Return all the samples in the context data and push them to the user prompt, achieving perfect recall. Although not optimal from the performance/cost trade-off, it gives a good estimate of how well the solution can utilise longer context and work with irrelevant data.
- Keywords search: Uses full-text search by terms or phrases.
- Vector search: Uses vector embeddings to find relevant examples based on the provided embeddings.
- Hybrid search: Combines keywords and vector search with semantic ranking.
Flexibility and Adaptability
While we provide retrieval experimentation results in the subsequent section, they are highly dependent on the context and evaluation data. As the data evolves and changes, the most effective search method may also change. Therefore, it’s crucial to have flexibility in the evaluation pipeline to monitor these changes and optimize the methods accordingly.
To enable the retrieval component’s flexibility, we have utilised AzureML pipelines to orchestrate the experimentation. The pipelines contained multiple re-usable steps: 1) dataset generation and preprocessing, 2) data ingestion into search index, 3) retrieval and generation, 4) evaluation of the generated outputs. This ensured data lineage across all steps and provided us with a straightforward option to re-evaluate and optimize the retrieval method as the solution evolved, guaranteeing consistency with previous experiments. This adaptability ensured that our approach remained effective even when the model and data changed.
Retrieval experimentation results
Our experiments revealed that vector search, using OpenAI’s text-embeddings-large model, performed best. This approach significantly improved generation results, with Precision@5 and Recall@5 scores of 0.31 and 0.27, respectively. The generation results were also significantly better for vector search compared to the solution without search, with experts’ evaluating vector search with an average score of 0.56±0.07, while no search had a score of 0.39±0.09. (See Expert assessments and Metric analysis sections for score explanation)
Importantly, perfect search did not enhance overall performance, averaging an expert score of 0.58±0.06, a result explained by examining the embedding space between context data and user questions:
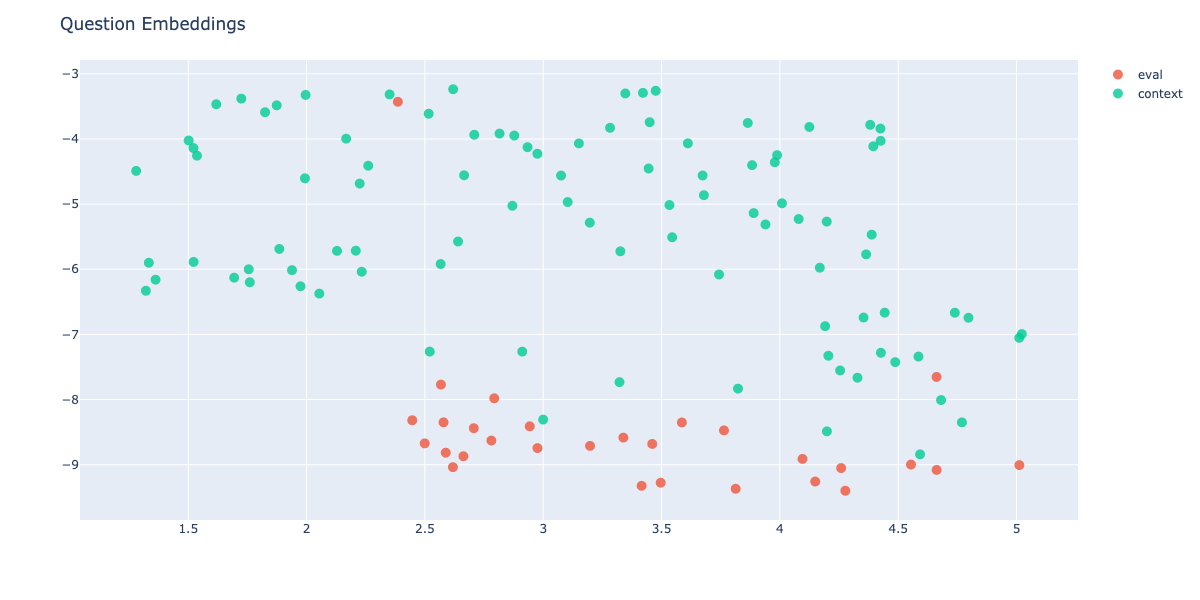 Figure: A scatter plot showing the embedding space of context data and user questions.
Figure: A scatter plot showing the embedding space of context data and user questions.
By analysing the embedding space of evaluation and context data, we could see that data is clearly separated, indicating a need for better alignment of context data with evaluation questions.
Having the option to verify the performance of the model with a perfect search allows us to spot those issues and understand clearly which part of the overall solution should be optimised first. Without those results, purely looking at the precision and recall metrics of the retrieval component, we might have prioritised investing our time in improvements of the search method, which would not have left a positive impact on overall performance.
Code Evaluation Metrics
Evaluating the generated code required a comprehensive set of metrics. We explored both traditional text-based metrics, LLM judge metrics, and metrics specific to the syntax of the programming language. Here is a list of all metrics which were calculated and later on evaluated against experts’ judgements.
| Category | Metric | Description | Needs Ground Truth |
|---|---|---|---|
| Traditional Metrics | BLEU | Measures the precision of word n-grams between generated and reference texts. | Yes |
| ROUGE | Measures the recall of word n-grams and longest common subsequence between generated and reference texts. | Yes | |
| CHRF | Measures the F-score of character n-grams between generated and reference texts. | Yes | |
| Levenshtein Distance | Measures the difference between two sequences by counting the minimum number of single-character edits (insertions, deletions, or substitutions). | Yes | |
| LLM Judge Metrics | Answer Correctness F1 | Splits code into sub-parts and evaluates each part independently. F1 score calculated using precision and recall based on similarity of parts using LLM. | Yes |
| Factual Correctness | Checks whether the functionality of each extracted code part is correct, considering the user question. | No | |
| Simple Answer Correctness | Compares the predicted code to the ground truth code, taking the user question into account. | Yes | |
| Simple Factual Correctness | Verifies if the predicted code is factually correct, given the user question. | No | |
| Syntax-Specific Metric | Parser | Detects the number of errors in the generated code using a parser. | No |
LLM Metrics
Unlike traditional metrics, which rely on simple text comparisons, LLM metrics leverage advanced models to assess both the functional and logical accuracy of generated code. For our LLM-based evaluations, we used GPT-4o (version 2024-05-13) as the primary LLM judge. Each metric was designed to output JSON responses, including detailed reasoning and a final numerical score that reflects the accuracy of the generated code.
We categorised the LLM metrics based on two key parameters:
- Detailed Version: Indicates whether the metric evaluates specific sub-parts of the generated code or the code as a whole.
- Usage of Ground Truth: Specifies whether the metric requires a reference (ground truth) code for comparison.
| Detailed Version | Uses Ground Truth | Does Not Use Ground Truth |
|---|---|---|
| Yes | Answer Correctness F1 | Factual Correctness |
| No | Simple Answer Correctness | Simple Factual Correctness |
Example: Answer Correctness F1
The Answer Correctness F1 metric was inspired by ragas and RadFact methodologies. The primary hypothesis is that breaking the code into logical sub-parts enables a more focused assessment, helping the LLM evaluate correctness by concentrating on specific code segments. This metric employs precision and recall to measure two key aspects:
- Precision: Whether the generated code includes all necessary and correct details.
- Recall: Whether all components of the generated code are relevant to the task.
Precision was calculated by evaluating predicted code against ground truth and recall by reversing the comparison and evaluating ground truth against prediction.
A notable distinction between Answer Correctness F1 and ragas/RadFact approaches is that the code parts are not independent and cannot be evaluated without taking the context into consideration. Hence, when evaluating the part of the code, we have also provided the full code for the context:
**User Question:**: {user_question}
**Ground Truth Code:**:
{reference}
**Full Predicted Code:**:
{full_predicted_code}
**Part for Evaluation:**:
{snippet}By including the full predicted code during sub-part evaluation, we ensure the LLM can interpret the snippet within its full context. This approach significantly enhances the accuracy of the assessment.
Challenges and Limitations
While this method works well in most scenarios, some examples revealed incorrect scoring due to the LLM’s misinterpretation of specific code parts. In these cases, the model would mistakenly downgrade a sub-part for missing content, even though the complete code included the necessary components. To mitigate this issue, we incorporated few-shot examples to help guide the model’s focus towards the relevant parts. However, additional experiments and adjustments may be needed to minimize these errors.
Another challenge with Answer Correctness F1 is its resource-intensive nature. Since the code must be divided into logical segments, the risk of introducing errors or noise increases. Additionally, this approach demands significantly more computational resources—up to 20 times more calls compared to Simple Answer Correctness metric.
Other LLM Metrics
- Simple Answer Correctness: Unlike its detailed counterpart, this metric evaluates the overall correctness of the generated code without dividing it into sub-parts. It is faster and less resource-intensive but may overlook issues within specific code segments.
- Factual Correctness: This is a detailed metric that evaluates the generated code, without requiring reference (ground truth) code for direct comparison. The metric focuses on whether the generated code adheres to logical consistency and correctness based on the user requirements. Since it analyses the generated code at a granular level, Factual Correctness is particularly useful in scenarios where the correctness of individual elements (such as variables, loops, or function calls) must be scrutinised for logical soundness. However, because it doesn’t rely on ground truth for comparison, the metric heavily depends on the LLM’s internal knowledge and reasoning capabilities, making it versatile but also prone to potential inaccuracies when the model’s understanding of a domain is limited.
- Simple Factual Correctness: Unlike the Factual Correctness metric, Simple Factual Correctness provides a high-level evaluation of whether the generated code is logically coherent and factually sound, but it does so without diving into the specifics of sub-parts or details.
Iterative approach
Our iterative approach was central to refining our evaluation methods. By continuously aligning metrics with expert feedback, we could make informed adjustments and improvements.
The iterative process involved several key steps:
- Initial Formulation: We began with a basic formulation of the prompt and ran end-to-end evaluations.
- Comparison and Analysis: By comparing LLM metrics with expert scores, we identified common cases where metrics failed to capture errors.
- Refinement and Adjustment: Using insights from the analysis, we modified the metric prompts and incorporated few-shot examples to guide the model.
This process was crucial for ensuring that our metrics accurately reflected the quality of generated code.
Metrics analysis
Throughout the project, we labelled predictions from multiple runs using different experts. We have used general quality from 1 to 5 (“Unusable” to “Very Good”) labels recorded by experts and then normalised the values between 0 and 1. Those were used as targets to compare against the evaluation metrics. To determine which metrics are useful and aligned with experts’ opinions, we analysed the correlation between expert scores and evaluation metrics.
We used two different methods to calculate correlations:
Sample-Level Correlations
In this approach, we combined all labeled data across different runs, treating each prediction and its corresponding expert score as an individual sample. Correlations were then calculated based on these individual sample values.
Example: Suppose we have 5 predictions from each of 3 different runs, and the experts have scored them as follows (normalized from 0 to 1):
- Run 1: [0.3, 0.8, 0.5, 0.9, 0.2]
- Run 2: [0.6, 0.4, 0.7, 0.5, 0.1]
- Run 3: [0.9, 0.8, 0.2, 0.4, 0.3]
For sample-level correlations, we take all 15 samples (5 from each run) and calculate the correlation between their individual expert scores and the evaluation metrics generated for each prediction. This method gives a fine-grained view, showing how well the metrics align with expert judgments on a sample-by-sample basis.
Dataset-Level Correlations
Here, we calculate correlations at the level of each run, rather than for individual samples. For each labeled run, the expert scores and evaluation metrics are averaged, and correlations are calculated between those averages.
Example: Using the same predictions from Run 1, Run 2, and Run 3, we first average the expert scores for each run:
- Run 1 Average: (0.3 + 0.8 + 0.5 + 0.9 + 0.2) / 5 = 0.54
- Run 2 Average: (0.6 + 0.4 + 0.7 + 0.5 + 0.1) / 5 = 0.46
- Run 3 Average: (0.9 + 0.8 + 0.2 + 0.4 + 0.3) / 5 = 0.52
We then calculate the correlation between these averaged expert scores and the corresponding average evaluation metrics for each run. Dataset-level correlations provide a broader, more aggregated view of the alignment between metrics and expert judgments, focusing on trends across different runs rather than individual predictions.
Key Differences
- Sample-level correlations offer a detailed look at how metrics align with expert scores on a case-by-case basis, potentially highlighting specific areas where the evaluation metrics succeed or fail.
- Dataset-level correlations smooth out individual variations by focusing on averages, providing insights into how well the metrics perform at a higher level across entire runs or datasets.
Agreement between experts
To understand how consistent the labels are between the experts themselves, we examined the correlation between pairs of experts and the number of samples both experts have labelled:
Sample level correlations:
| score_expert_1 | score_expert_2 | score_expert_3 | |
|---|---|---|---|
| score_expert_1 | 1.0 | 0.48 (169) | 0.47 (140) |
| score_expert_2 | 0.48 (169) | 1.0 | 0.17 (56) |
| score_expert_3 | 0.47 (140) | 0.17 (56) | 1.0 |
Dataset level correlations:
| score_expert_1 | score_expert_2 | score_expert_3 | |
|---|---|---|---|
| score_expert_1 | 1.0 | 0.52 (7) | 0.28 (5) |
| score_expert_2 | 0.52 (7) | 1.0 | -1.00 (2) |
| score_expert_3 | 0.28 (5) | -1.00 (2) | 1.0 |
Note: Correlation numbers reflect the strength and direction of the relationship between two variables, ranging from -1 to 1. A score of 1 means a perfect positive correlation, -1 indicates a perfect negative correlation, and 0 shows no correlation. There is a perfect negative correlation between expert_2 and expert_3 at the dataset level, but this is not significant as we only had 2 data points for analysis.
It is evident that the correlation remains relatively modest, hovering around 0.5, indicating considerable variability in how different experts annotate the data. This underscores the challenge of maintaining consistent code labelling and suggests that additional guidelines might be necessary to achieve better alignment among experts. Moreover, this provides a useful benchmark when examining the correlation between metrics and expert scores.
Metrics correlation
For metrics correlation, we have used the average between expert scores per each sample as a target. Here are the correlations between average expert score and the evaluation metrics:
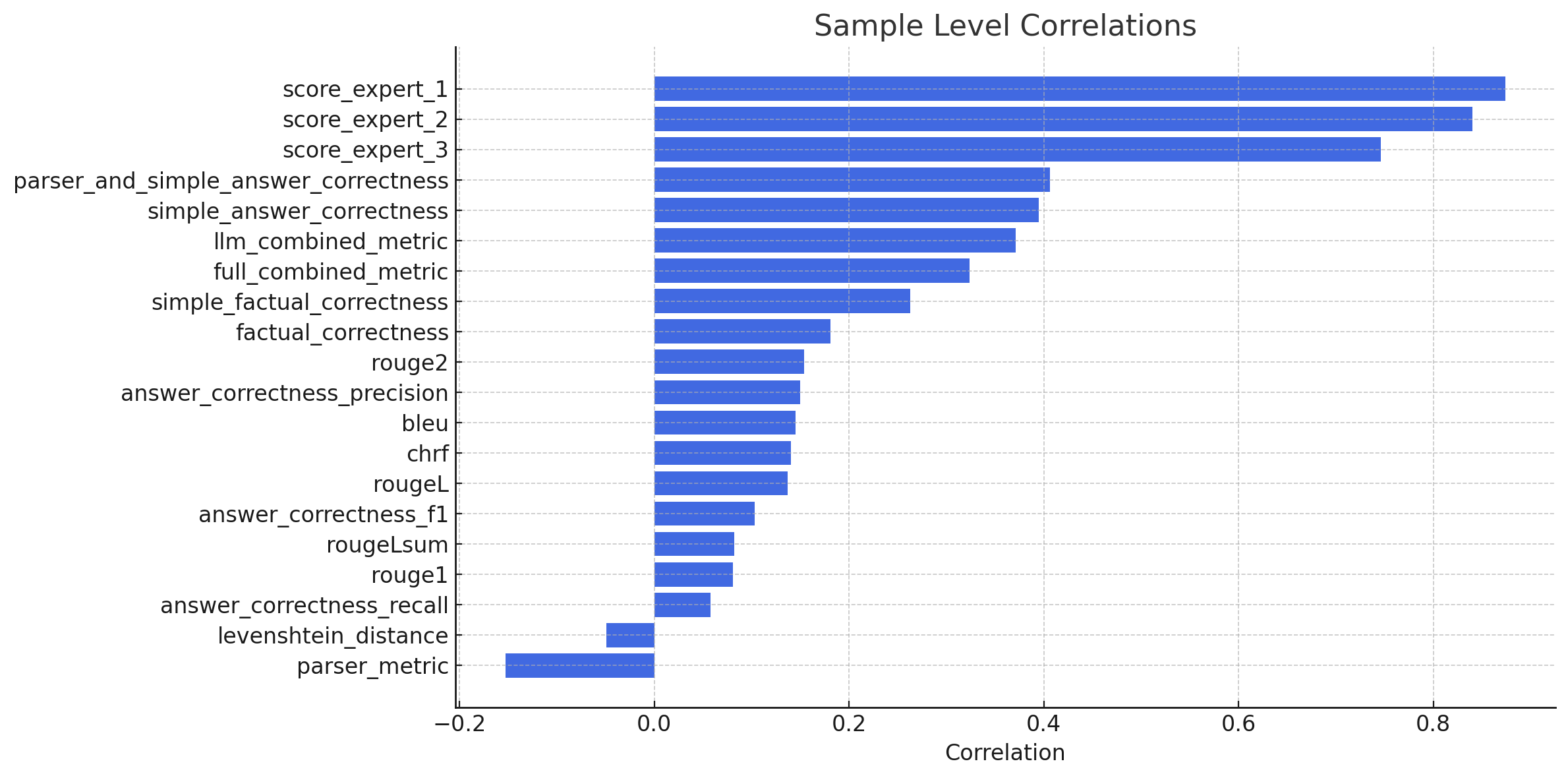 Figure 1: A bar plot showing the correlation between various metrics and expert scores at the sample level.
Figure 1: A bar plot showing the correlation between various metrics and expert scores at the sample level.
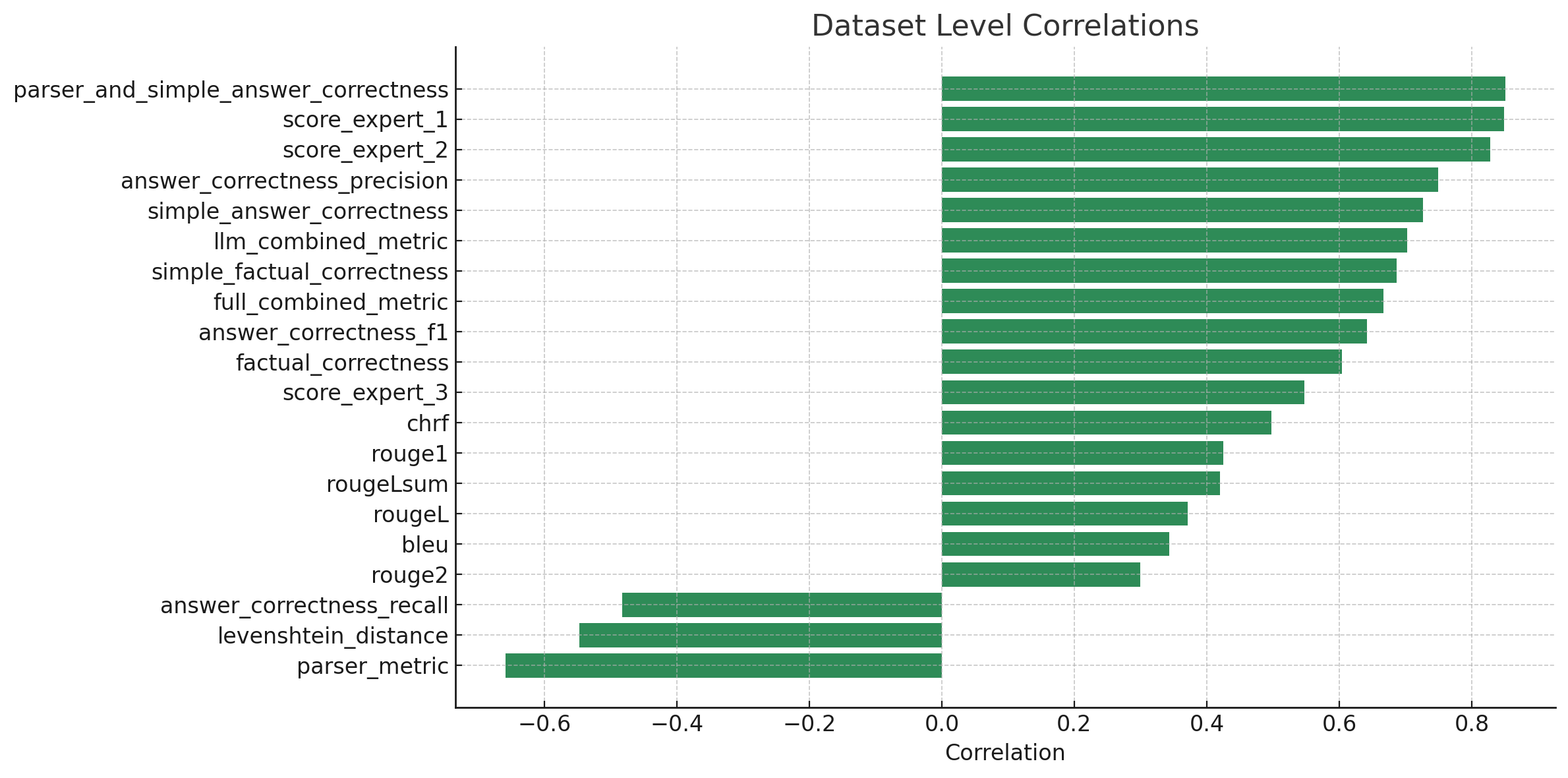 Figure 2: A bar plot showing the correlation between various metrics and expert scores at the dataset level.
Figure 2: A bar plot showing the correlation between various metrics and expert scores at the dataset level.
- To begin with, it is evident that there is a significant discrepancy between sample-level correlations and those at the dataset level. This indicates considerable noise at the sample level, where metrics often conflict with the labels. However, when we compute average scores across multiple runs and datasets, a stronger correlation becomes apparent.
- Among metrics from LLM judges, the simple_answer_correctness stands out as the most promising. It demonstrates the highest correlation with expert scores at the sample level and exhibits a correlation similar to answer_correctness_precision at the dataset level.
- Factual correctness metrics also exhibit strong correlation at the dataset level, indicating their potential utility in situations lacking ground truth. For instance, we applied this in synthetic data generation as a subsampling step to identify challenging examples. Another application could be employing the metric during the self-reflection phase for LLMs to enhance response quality automatically.
- The parser metric is also valuable, given its high absolute dataset-level correlation scores. The parser metrics has a negative correlation with the experts’ score because it counts the number of errors in the code. A higher parser metrics score indicates lower code quality. Combining the parser with simple_answer_correctness (an average of two metrics) produced correlations comparable to the aggregated expert’s score.
- Ultimately, the metrics for detailed answer correctness and factual accuracy applied to parts of the code did not meet expectations, displaying low correlations with sample-level scores. Notably, answer_recall exhibited a negative correlation with expert scores at the dataset level, which indicated misalignment of the scores. However, these detailed metrics offer more parameters for optimisation, such as snippet extraction, and after further tuning, they may align better with expert opinions. They could also be beneficial when evaluating more complex examples containing multiple individual functions that require independent assessment.
Synthetic Data Generation
To enhance our dataset and introduce more data samples, we explored synthetic data generation. This process involved leveraging user questions recorded in the web app and generating new queries with LLMs.
Approach and Methodology
Our approach to synthetic data generation involved several steps:
- Gathering Questions: We collected questions from our web app, cleaned them, and removed duplicates.
- Generating New Questions: Using each question as inspiration, we generated new queries with LLMs.
- Generating Code: For each synthetic question, we generated code with the copilot.
- Filtering Duplicates: We filtered out duplicates based on embedding similarity and code similarity.
- Subsampling Challenging Examples: Using a factual correctness metric, we identified questions that produced incorrect answers and ensured they were well-represented in the final dataset.
Examples of Generated Questions
The synthetic data included complex and varied questions, such as:
- How can I create a program that picks components from a supply point, moves to specific locations, places the components, and repeats this for all components in a sequence? Include a function call to control the gripper.
- How can I program the robot to perform an automated tool change, switching between a welding torch and a gripper, and then proceed with the respective tasks in a predefined manner? Include safety checks and tool calibration steps.
- Can you help me write a program to stack boxes onto a pallet in a specific pattern, with precise placement and an offset of 10mm between each layer? The robot should check for box presence using a sensor and handle up to 3 different box sizes.
Labelling and Integration
To integrate the newly produced data, we included an option to label it directly within the same app used for evaluation. This allowed experts to quickly dismiss irrelevant questions, edit queries, and supply correct code answers.
Although the labelling of synthetic data was not a primary focus during the project, initial assessments by experts confirmed the relevance and suitability of the generated questions. Based on the limited sample, here are the comparisons against the evaluation dataset:
- Expert scores: 0.38±0.12 vs 0.56±0.07
- Length of the generated code: 2644.62±197.35 vs 1318.29±194.35.
This indicates that the generated questions are more complex, leading to lower scores and extended responses. Therefore, the new synthetic data would be beneficial in the future as a source of challenging examples for evaluation or context datasets.
Leveraging Off-the-Shelf Models
One of our primary goals was to evaluate if off-the-shelf models—in this case, OpenAI’s GPT-4 models—with a retrieval-augmented generation system could support accurate and efficient code generation based on natural language queries.

In our experiments, we observed that using the latest GPT-4o (version 2024-05-13) model with all available context data directly in the prompt generated the highest-quality results, as reflected by an expert score of 0.62±0.06. This run also demonstrated strong performance in terms of answer and factual correctness. However, the downside was the increased token usage, with an average of over 22,000 tokens per request vs 3,500 tokens on average with vector search, making it resource-intensive and less efficient from a cost-performance perspective. Expert’s evaluation of the GPT-4o model outputs with vector search for retrieval showed a score of 0.58±0.09.
To find a more balanced approach, we experimented with GPT-4o-mini (version 2024-07-18), a lighter version of GPT-4o. This model maintained a comparable expert score (0.58±0.10) while significantly reducing request duration (6 seconds vs. 12.86 seconds for the full GPT-4o). These gains in efficiency, coupled with only minor differences in answer correctness, highlighted the trade-offs between performance and cost that we could optimize for solution deployment.
The analysis of several runs revealed that the top-performing models were closely matched in terms of scores, suggesting that minor adjustments to model settings had little impact on overall performance under the current dataset. This highlighted a potential limitation of our evaluation dataset in its ability to distinguish nuanced differences between models. Expanding the dataset to include more diverse and complex examples is likely necessary to better capture these differences.
Confirmation of the Third Hypothesis
Our third hypothesis questioned whether the performance of the latest Azure OpenAI models would be sufficient for the task. The feedback from alpha users of the web app provided valuable insights here. Users rated the model responses with an average feedback score of 0.7±0.18, indicating a generally positive reception and confirming the model’s capability to meet user expectations.
This feedback, combined with expert evaluations, confirmed that leveraging off-the-shelf models was indeed a viable strategy. The models not only supported accurate code generation but also demonstrated a strong alignment with user needs, validating our hypothesis.
Ultimately, leveraging off-the-shelf models proved effective in quickly establishing a reliable foundation for the code generation service. The experiment also underscored the need for careful consideration of trade-offs between model complexity, cost, and real-time performance. Through iterative testing, we identified an optimal balance that minimised costs while maintaining high-quality code generation results.
Conclusion
Throughout our project, we focused on several key areas that significantly contributed to the development and evaluation of the Code Generation Copilot. This project emphasised the importance of comprehensive data collection, iterative improvements, and establishing meaningful baselines, all of which helped refine the copilot’s capabilities.
Data Collection was a critical part of our process, supported by two specialised web applications. The Internal Alpha User Webapp enabled real users to interact with the copilot in its alpha stage, providing invaluable feedback and real-world interaction data. This allowed us to compare user behaviour with our initial assumptions, which informed the exploration of synthetic data generation.
The Labelling Webapp, designed specifically for domain experts, played a crucial role in ensuring high-quality data labelling. By providing an intuitive platform for experts to rate the copilot’s predictions, it streamlined the evaluation process. This app eliminated the need for manual labelling via spreadsheets, allowing for faster, more consistent evaluations, ultimately leading to better-quality datasets and improved model validation.
In parallel, our approach to Iterative Development & Improvement of Metrics proved essential. Like any other ML-based solution, optimizing language model metrics is an ongoing process. We started with standard LLM metrics, which showed low correlation with expert judgments. However, through iterative experiments — adjusting prompts, using few-shot examples, and customizing them for our specific use case — we achieved much stronger alignment between our metrics and expert evaluations. This highlights the need to continuously refine models and metrics to suit the application.
Finally, we observed again the Importance of Baselines. Initially, we implemented a complex evaluation metric for code generation, which involved splitting the code into logical units for separate evaluations. However, we found that a simpler approach — evaluating everything in a single prompt — yielded better results and was more efficient, being 20x faster and cheaper to run. This insight underscored the importance of establishing a solid baseline and thoroughly testing different approaches before settling on an optimal solution.
In conclusion, this project showed the power of careful data collection, iterative refinement, and baseline testing in developing effective code generation tools. By focusing on these principles, we were able to significantly improve the copilot’s performance and set the foundation for further innovations.
Acknowledgements
We would like to give thanks to the other authors who helped to craft and review this post: Benjamin Guinebertière, Annie Wong and Ehsan Zare Borzeshi.
The feature image was generated using Bing Image Creator. Terms can be found here.