
Introduction
Multi-agent systems are becoming the go-to architecture for complex AI workloads. Instead of one monolithic agent doing everything, teams decompose capabilities into specialized agents — each with its own domain expertise, deployment pipeline, and release cadence. This approach mirrors the microservice patterns that have transformed backend development.
But decomposition creates a new problem: how do you maintain conversational context across agent boundaries?
When a user asks a follow-up question, the receiving agent needs to understand what came before. In a single-agent system, that context lives in memory. In a multi-agent system, context must travel between independently deployed services that share no infrastructure.
During a recent ISE engagement, the team faced exactly this challenge. We needed coordinator agents to share conversation history and domain-specific context with stateless domain agents — all using the A2A (Agent-to-Agent) protocol as the communication standard.
The following sections cover the three approaches we evaluated and why we chose the embedded context pattern.
A2A Protocol and Context Passing
The A2A protocol is an open standard for agent-to-agent communication. It defines how agents discover each other, exchange messages, and manage tasks. For context passing, three protocol concepts matter most:
contextId— A server-generated string that groups related tasks in a conversation. The remote agent assigns it on the first interaction and returns it in the response; the client echoes it back on subsequent turns. OnecontextIdmaps to many task IDs (one per turn). Think of it as the conversation thread identifier.Message— The unit of communication between agents. Each message contains apartsarray and optionalmetadata.Parts— The building blocks of a message. Each part contains exactly one of three fields:text— A string for conversational content and queries.file— AFilePartobject for file references or binary content.data— ADataPartobject for structured, machine-readable context.
Each part can include its own metadata object for type identification and versioning. This part-level metadata is what enables type discrimination — a receiving agent can inspect metadata.type to determine how to deserialize each part.
Message-level metadata handles cross-cutting concerns like user ID or session ID — information that applies to the entire message rather than a single part.
The Challenge: Context in a Stateless World
The team’s architecture followed microservice best practices. Domain agents were independently deployed services, each owned by a different team with its own release cadence. A coordinator agent orchestrated these domain agents, routing user requests to the appropriate domain agent.
This design provided deployment independence and clear ownership boundaries. It also created a context-passing problem with several hard requirements:
- Context continuity — Conversations span multiple turns and multiple agents. Each agent needs enough history to produce coherent responses.
- Version independence — Coordinator and domain agents deploy on different schedules. The context format cannot break when one side updates.
- No shared infrastructure — Domain agents function as true microservices. Requiring them to access the coordinator’s database violates service boundaries.
- Security isolation — Not every agent should see the full conversation history. The coordinator should control what context each domain agent receives.
Three patterns emerge for solving this:
- Domain agents pull context from shared storage.
- The coordinator pushes context in the message payload.
- Each domain agent maintains its own context store.
We evaluated all three and dismissed one early.
Three Approaches to Context Sharing
The A2A protocol supports three context-passing patterns. They differ in where domain agents get their context and who owns the state.
Approach 1: Shared Storage with contextId Reference
In this pattern, the coordinator sends a lightweight message containing only the contextId. The domain agent uses that ID to read conversation history from a shared Context Store — a database or cache that both the coordinator and domain agents can access.
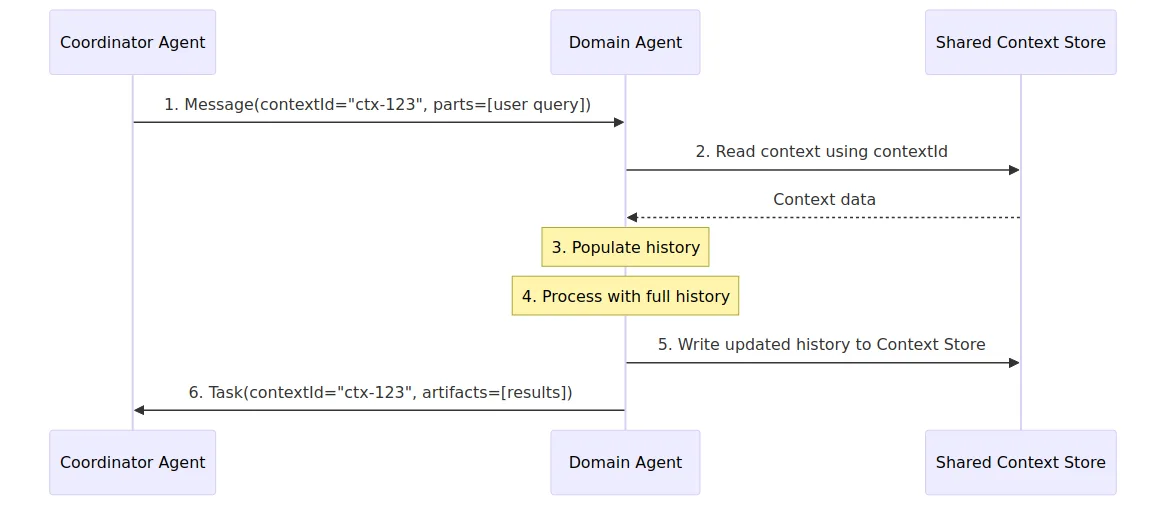
The coordinator agent also maintains its own conversation history, but this is omitted from the diagram to focus on the domain agent’s interaction with the Context Store.
This approach keeps payloads minimal since only the query travels over the wire. All agents read from the same store, providing a single source of truth. Conversation length is not limited by message size, making it scalable for long histories.
The fundamental trade-off is that this pattern violates the no-shared-infrastructure principle. It requires domain agents to access storage owned by the coordinator (or a shared platform layer), creating a runtime dependency between services that should be autonomous. Each domain agent needs connectivity and credentials for the shared store, adding operational complexity and increasing the security surface across organizational boundaries.
Approach 2: Embedded Context in Message Payload
In this pattern, the coordinator retrieves context from the Context Store, optionally summarizes it, and embeds it directly in the message payload. Domain agents receive everything they need in-band — no storage access required.

This approach eliminates storage dependencies entirely. Domain agents remain fully stateless, with no additional storage read/write operations adding latency. Coordinators control exactly what context each agent receives, providing strong security isolation. Testing is also simpler because domain agents can be validated with mock message payloads.
The trade-off is larger payloads, since the full summarized context travels with every request. Long conversations also need compression through summarization to keep payloads practical.
Approach 3: Per-Agent Context Store (Stateful Agents)
The A2A protocol implies a third option. Each domain agent maintains its own context store, using the contextId to persist and retrieve conversational state across interactions. The protocol’s Life of a Task documentation explicitly allows agents to “use the contextId to maintain internal state, conversational history, or LLM context.”
This makes each agent self-contained — no shared storage, no coordinator-managed payloads. But it introduces significant complexity. Every remote agent becomes a stateful service requiring its own storage infrastructure, state migration during deployments, and synchronization logic to prevent state divergence across agents.
We dismissed this approach early. The operational overhead of maintaining per-agent state stores across independently deployed services outweighed the benefits of agent-level autonomy.
Deep Dive: The Embedded Context Pattern
The team chose the embedded context pattern because it aligned with the engagement’s microservice principles. Domain agents should be independently deployable, independently testable, and free of infrastructure dependencies. Pulling context from shared storage violates those principles — it creates a runtime coupling between services that should be autonomous. And as discussed in Approach 3, making each domain agent stateful introduces operational overhead that undermines deployment independence.
Beyond the operational advantages, keeping domain agents stateless offers four specific benefits:
- Single source of truth — Keeping conversation state exclusively in the coordinator avoids state divergence. When each domain agent maintains its own view of the conversation, those views can drift out of sync. A single coordinator-owned state eliminates synchronization complexity.
- Context precision — A stateless design lets the coordinator refine and rewrite context before sending it to each domain agent. Rather than giving agents access to the full conversation, the coordinator provides precisely the information each agent needs — omitting extraneous details that could reduce response quality or expose sensitive data.
- Simpler maintenance and debugging — Stateless agents behave deterministically given the same input. Debugging reduces to inspecting the input message rather than reconstructing an agent’s internal state history. This also simplifies deployments — any agent instance can be replaced or rolled back without state migration.
- Evolutionary flexibility — Starting stateless preserves future options. A stateless domain agent can later adopt its own state store and ignore the coordinator-provided context, without requiring changes to the coordinator. The reverse migration, moving stateful agents to stateless, requires rearchitecting the orchestrator to embed context it never needed to provide before. Starting with embedded context is the lower-risk default.
The A2A protocol’s Message structure supports this pattern natively. Because contextId is server-generated, the first message in a conversation omits it — the remote agent assigns one and returns it in the response. On subsequent turns, the coordinator echoes the assigned contextId back. The following example shows a follow-up turn where the coordinator includes the previously assigned contextId along with embedded conversation history and domain-specific context:
{
"message": {
"messageId": "msg-001",
"contextId": "ctx-123",
"metadata": {
"userId": "2"
},
"parts": [
{
"text": "tell me more about option 4"
},
{
"data": [
{
"role": "user",
"content": "I am looking for a lightweight laptop"
},
{
"role": "assistant",
"content": "Great choice. Do you have any preferred brands, budget range, or screen size?"
},
{
"role": "user",
"content": "show me models under 1,000 dollars"
},
{
"role": "assistant",
"content": "Here are some options that match your preferences."
}
],
"metadata": {
"type": "ConversationHistory",
"schemaVersion": "1.0"
}
},
{
"data": {
"userProfile": {
"location": "Sample City",
"preferredLanguage": "en-US"
},
"foundItems": {
"query": "lightweight laptops",
"items": [
{"url": "...", "itemId": "item-123"},
{"url": "...", "itemId": "item-456"}
],
"totalCount": 2
},
"sessionContext": {
"sourceId": "WebChat",
"regionId": "region-001",
"postalCode": "00000"
}
},
"metadata": {
"type": "UserContext",
"schemaVersion": "1.0"
}
}
],
"role": "user"
}
}This message contains three parts, each serving a distinct purpose:
- Text part — The current user query (
"tell me more about option 4"). This is what the user just typed. - Conversation history part — A
dataarray containing the summarized conversation history. Themetadata.typefield identifies it asConversationHistory, andschemaVersionenables independent evolution of the history format. - User context part — A
dataobject with domain-specific context like user location and previous search results. Itsmetadata.typeisUserContext, with its ownschemaVersion.
Part-Level Metadata and Type Discrimination
The part-level metadata is what makes this pattern extensible. When a domain agent receives a message, it inspects each part’s metadata.type to determine how to process it. This enables factory patterns for strongly typed deserialization — the agent can route each part to the appropriate handler based on its type.
Because each part type carries its own schemaVersion, teams can evolve context formats independently. The coordinator might start sending a ConversationHistory v2.0 while a domain agent still expects v1.0 — versioning is explicit and manageable. Following semantic versioning conventions strengthens schema compatibility further: a receiving agent can inspect the version to determine whether an unfamiliar schema is safe to process. A minor or patch increment signals backward-compatible changes, while a major increment indicates a breaking change that requires the receiver to update its deserialization logic.
Managing Payload Size with Summarization
Embedding full conversation history in every message would quickly become impractical for long conversations. The team addressed this with a 10-turn summarization strategy: after every 10 turns, the coordinator summarizes the conversation history before embedding it. This keeps the history payload bounded while retaining the context domain agents need for coherent responses.
The coordinator retrieves the raw history from the Context Store, applies summarization, and includes the compressed version in the message. Domain agents never see the raw history — they work with the summarized version.
Summarization is not without risk. Every summarization step can lose important details or introduce inaccuracies, potentially degrading the quality of downstream responses. However, forwarding unbounded conversation history carries its own quality risks: as context grows, models may struggle with relevance and coherence. Summarization is a deliberate trade-off, balancing context fidelity against payload size, performance, and security. For this engagement, the 10-turn threshold struck that balance, and the team could tune it based on observed response quality.
This approach also provides a natural security boundary. The coordinator controls exactly what context each domain agent receives. Sensitive information from one part of the conversation can be excluded from the context sent to a specific agent. This is harder to achieve with shared storage, where access controls operate at the storage level rather than the content level.
Trade-offs and Decision Criteria
No single approach is universally better. The right choice depends on your deployment topology, security requirements, and operational constraints.
The core architectural decision is whether domain agents are stateful or stateless. Within the stateful approach, two variants exist: shared storage (all agents read from one store) and per-agent storage (each agent maintains its own). These variants share some characteristics, like additional latency from storage calls, but differ in others, like security isolation. The following matrix compares all three options across key criteria:
| Criteria | Shared Storage | Embedded Context | Per-Agent State |
|---|---|---|---|
| Storage dependency | Domain agents need shared access | Stateless domain agents | Each agent needs its own store |
| Payload size | Minimal | Manageable with summarization | Minimal |
| Context fidelity | Full history available | Summarization may lose details | Full history per agent |
| Network latency | Additional storage calls | No extra calls | Additional per-agent storage calls |
| Security isolation | Cross-agent data exposure risk | Coordinator controls context | Agent-level isolation; no cross-agent access |
| Testing complexity | Requires storage mocks | Simple payload mocks | Requires per-agent state setup |
| Version independence | Storage format coupling | Part-level schema versioning | Per-agent format management |
| State consistency | Single source of truth | Coordinator-owned state | Risk of state divergence |
| Operational overhead | Shared infrastructure | Coordinator manages context | Per-agent infrastructure |
Choose shared storage when domain agents are trusted internal services with existing access to the storage layer, when conversations are extremely long and summarization isn’t practical, or when you need centralized query capabilities over conversation history.
Choose embedded context when domain agents are independently deployed microservices, when cross-organizational boundaries make shared storage impractical, when security isolation requires fine-grained control over what each agent sees, or when you want domain agents to remain fully stateless and portable.
Choose per-agent state when domain agents need full autonomy over their conversational memory, when agents are long-running and maintain deep per-user context, or when each agent’s state is truly independent with no need for cross-agent consistency.
For the team’s engagement, embedded context was a clear fit. The domain agents were true microservices with independent deployment cycles, and the 10-turn summarization strategy kept payloads well within practical limits.
Conclusion
Passing context between agents in a multi-agent system is a design decision that ripples through your entire architecture. The embedded context pattern — sending summarized history directly in A2A message payloads — enables stateless domain agents that are independently deployable, testable, and secure.
The cost is increased payload size, but bounded summarization (the 10-turn approach used here) keeps that practical. The security benefit of coordinator-controlled context sharing is significant, especially when agents cross team or organizational boundaries.
Embedded context is also the lower-risk starting point: adopting state later is additive, while removing it requires rearchitecting the orchestrator.
If you’re building multi-agent systems with the A2A protocol, evaluate all three patterns against your deployment topology. Start with the decision matrix above and let your architecture constraints guide the choice.
References
The feature image was generated using Copilot.