

Introduction
Recently, we worked on a sustainability project with a major customer in the oil industry. Their goal was to leverage geospatial and climate data to build a platform that can assess the production impact of their sites on the nearby biodiversity using machine learning. The project’s goal was to port the codebase, written by data scientists and machine learning engineers in the form of experimental Python notebooks, to a platform where the processes of data preparation and model training could be automated, using workflows and pipelines, at scale.
One of the challenges of the project was to find a cost-effective way to process hundreds of gigabytes of geospatial data at scale and to create the machine learning features required to train the models. In this post we will introduce the general technical context of the project and detail how we leveraged Azure Machine Learning Compute Clusters to perform these large-scale data preparation tasks using the Dask framework.
What is Dask?
Dask is a flexible library for parallel computing in Python. It can scale Python libraries such as NumPy, Pandas, Scikit-Learn, and more, to multi-core machines and distributed clusters when datasets exceed memory. Dask has a familiar Python API that integrates natively with Python code to ensure consistency and minimize friction.
Dask is very popular with data scientists because it enables parallel computing with these familiar Python APIs, which makes it easy to use and integrate with existing code.
Dask works by providing parallel data processing capabilities to the existing Python stack. It does this by splitting large data structures, like arrays and dataframes, into smaller chunks that can be processed independently, and then combined. Dask also implements dynamic task scheduling that can optimize computation based on dependencies, resources, and priorities.
Dask is particularly popular in the world of geoscience and geospatial data processing. In our project, we leveraged its power to run a significant amount of code – roughly 5,000 lines of Python code – split among 40 Jupyter notebooks. Re-using this codebase was essential to accelerate the project development. We had a solid starting point that required a bit of refactoring in order to be executed in a batch environment. All we needed to do was to determine how to run this code at scale on the customer’s platform!
Running Dask jobs on Azure Machine Learning
The platform we built was designed to leverage Azure Machine Learning from the start. In a few words, Azure Machine Learning is a cloud-based platform that empowers data scientists and developers to build, deploy, and manage high-quality models faster and with confidence. It supports several features such as compute options, datastores, notebooks, a designer GUI, and automated ML. It also enables industry-leading machine learning operations (MLOps) with tools such as CI/CD integration, MLFlow integration, and pipeline scheduling.
One of our ideas was to leverage Azure ML Compute Clusters to run the Dask-based data preparation and feature engineering tasks at scale without code modification. This would be a huge optimization when compared to the cost of deploying a separate data processing component like Spark, and possibly having to rewrite the code to leverage this new infrastructure.
When we looked at Dask in detail, we found it can use a number of back-end platforms to distribute computing tasks, like Kubernetes, Virtual Machines, etc.
One of the supported backends is the venerable Message Passing Interface (MPI), which is also supported by Azure ML compute clusters. This means that the code written in the Planetary Computer Hub using Jupyter notebooks could be easily executed on Azure ML clusters to automate and scale the data preparation jobs.
In other words, since Azure ML Compute Clusters natively support MPI workloads, all that was needed to run Dask jobs at scale was to assemble the right environment and configuration.
Create the environment
In Azure ML, we can use Conda environment files that list all the required dependencies to run data preparation scripts on a cluster node. Here is a minimal example with the required libraries required to run Dask via MPI:
# conda.yml
dependencies:
- python=3.8
- pip:
- dask[complete]
- dask_mpi
- mpi4py
name: dask-mpiTo create the environment in Azure ML, we can use the Azure command line with the Azure ML extension. This will upload our Conda environment definition and trigger the build of the Docker image that our cluster nodes will use:
az ml environment create \
-g $GROUP \
-w $WORKSPACE \
--name dask-mpi \
--conda-file conda.yml \
--image mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04This will create an Azure ML environment called dask-mpi.
The base Docker image specified in the environment creation already contains all the necessary OpenMPI libraries. You can see a full list of available base images in the GitHub repo AzureML-Containers.
Create the compute cluster
We need an Azure ML Compute Cluster to run our script. The command below will create one with the following settings:
- VM size Standard_D8_v3, which is 8 vCPU and 32 GiB RAM. See Supported VM series and sizes for a list of possible options.
- Maximum of 6 instances.
- Use your current SSH key so you can connect to the nodes.
az ml compute create \
-g $GROUP \
-w $WORKSPACE \
--type AmlCompute \
--name dask-cluster \
--size Standard_D8_v3 \
--max-instances 6 \
--admin-username azureuser \
--ssh-key-value "$(cat ~/.ssh/id_rsa.pub)"Run the Dask script
In order to leverage the MPI environment, the Dask script needs to be modified to add the following lines at startup:
from dask_mpi import initialize
initialize()
from distributed import Client
client = Client()This is all that is necessary for the Dask framework to connect to the cluster nodes. You can learn more about this initialization code in the Dask-MPI documentation.
To run this script on an Azure ML cluster, we will need a job definition file. Here is an example that we could use to execute a script named prep_nyctaxi.py, located in the src folder.
# job.yml
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
display_name: dask-job
experiment_name: azureml-dask
description: Dask data preparation job
environment: azureml:dask-mpi@latest
compute: azureml:dask-cluster
inputs:
nyc_taxi_dataset:
path: wasbs://datasets@azuremlexamples.blob.core.windows.net/nyctaxi/
mode: ro_mount
outputs:
output_folder:
type: uri_folder
distribution:
type: mpi
process_count_per_instance: 8
resources:
instance_count: 4
code: src
command: >-
python prep_nyctaxi.py --nyc_taxi_dataset ${{inputs.nyc_taxi_dataset}} --output_folder ${{outputs.output_folder}}The important part of that file, regarding Dask, is the following section:
distribution:
type: mpi
process_count_per_instance: 8
resources:
instance_count: 4This is where we request to run the script using an MPI cluster of 4 instances (instance_count) and 8 processes per instance (process_count_per_instance). You should adjust these numbers according to the configuration of your cluster.
The job also defines inputs and outputs, both mounted directly from Blob Storage to the compute nodes. This means the inputs and outputs will appear on all the nodes as local folders.
Also note that the job definition requests to use the dask-mpi environment that we created above.
The job execution can be triggered using the following command:
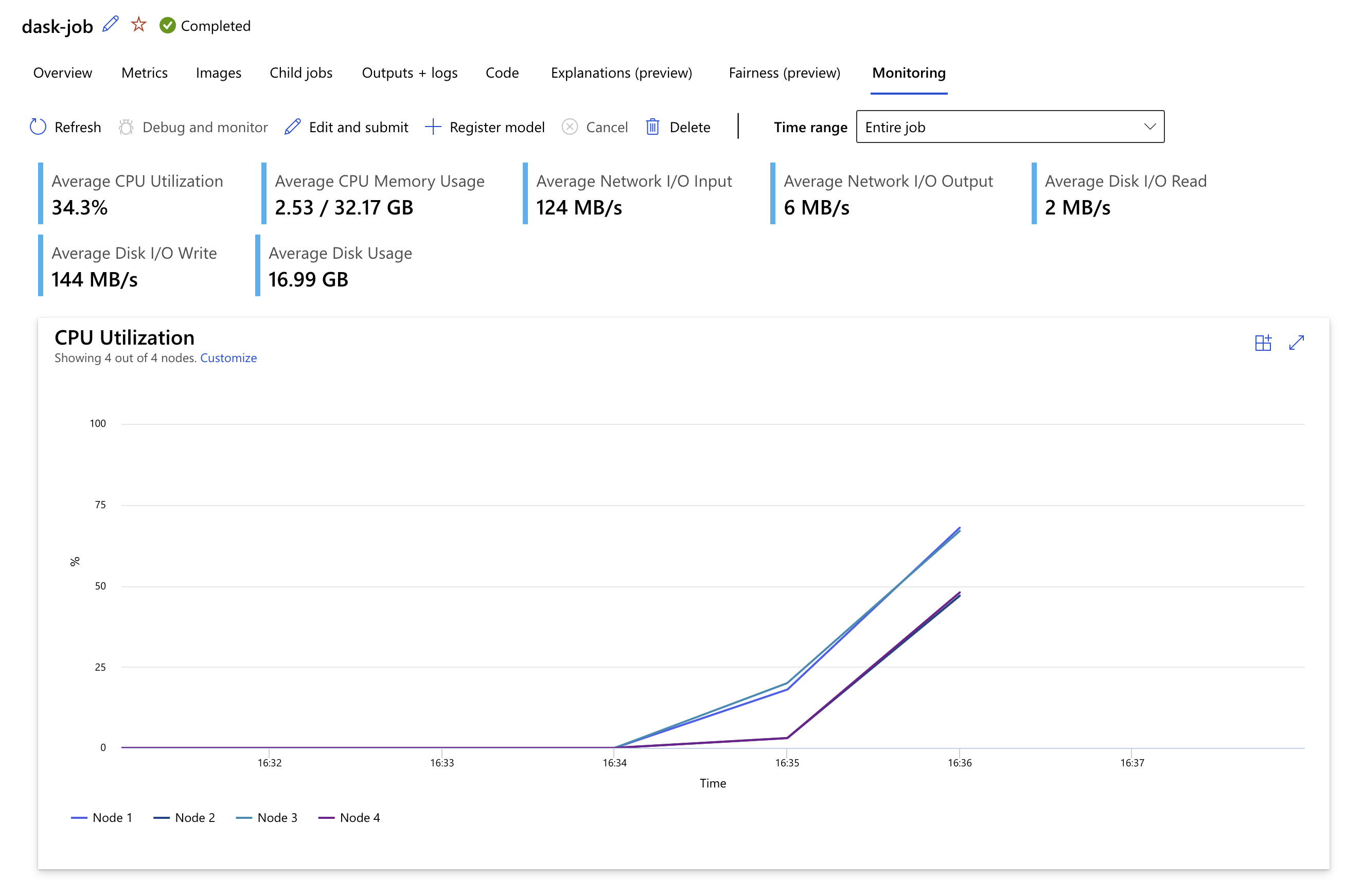
az ml job create -g $GROUP -w $WORKSPACE --file job.ymlYou can then track the execution of the job in the Azure ML Studio. In the screen capture below, you can see the job using all four nodes to run a data preparation job.
Full source code
You can find a full working example in this GitHub repository: dask-on-azureml-sample. It includes a sample script, plus all the necessary Azure ML configuration.
Conclusion
Using Dask-MPI and the native Azure ML MPI support, we were able to run our Dask-based data preparation at scale on Azure ML Compute Clusters, with minimal effort, no additional custom dependencies, and no code changes.